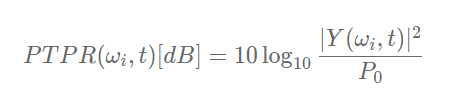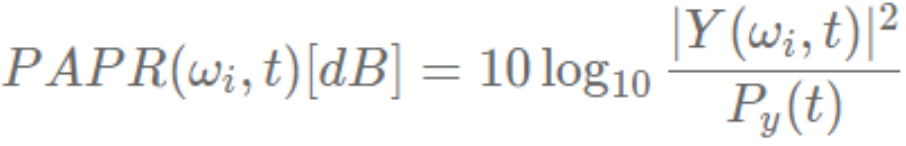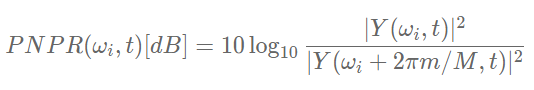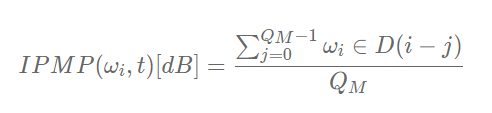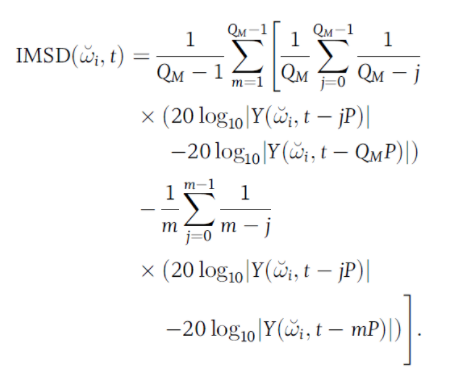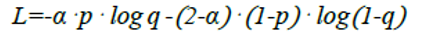网易云信音频实验室持续在实时通信音频领域进行创新,基于 AI 的啸叫检测方法的研究方案被 ICASSP 2022 接收,并受邀于会议面向学术界和工业界进行研究报告。
ICASSP (International Conference on Acoustics, Speech and Signal Processing) 即国际声学、语音与信号处理会议,是 IEEE 主办的全世界最大的,也是最全面的信号处理及其应用方面的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。2022 年线上会议于 5 月 7-13 日举行,线下会议于 5 月 22-27 日在新加披举行。
![]()
本次论文的接收是网易云信音频实验室继 AI 音频降噪、AI 音乐检测 2 篇论文被 INTER-NOISE 2021 收录之后,在音频信号处理领域又一新的里程碑。AI 啸叫检测也是国际上首次将 AI 和啸叫问题进行深度结合的实践,该研究结果包括 89.46% 的检出率,以及 0.40% 的误检率,在实际应用中有着广泛意义。
![]()
![]()
论文地址:https://ieeexplore.ieee.org/document/9747719
啸叫现象在现实生活中常有发生,在传统的场景中,例如会议室、KTV 等公放拾音系统,助听器,带有降噪透传或者耳返功能的耳机等。
![]()
随着实时通信(RTC)领域的发展,啸叫的产生也有了新的场景,尤其当多个设备在同一物理空间同时入会时,极易出现啸叫现象。
![]()
首先分析一下传统的场景中,当声学传输路径存在反馈闭环通路 (麦克风 -> 扬声器 ->麦克风),就有可能产生啸叫。
![]()
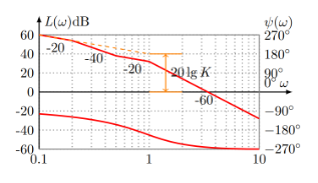
在反馈控制理论中,可以通过奈奎斯特稳定性判据进行判断,如果反馈系统处于非稳定状态,则会导致啸叫的产生。从系统传递函数的奈奎斯特图或者 Bode 图中可以直观的分析出系统的稳定性,声学系统产生啸叫的必要条件是:
2) 反馈环路为正反馈,即对应的开环增益大于 1。
![]()
![]()
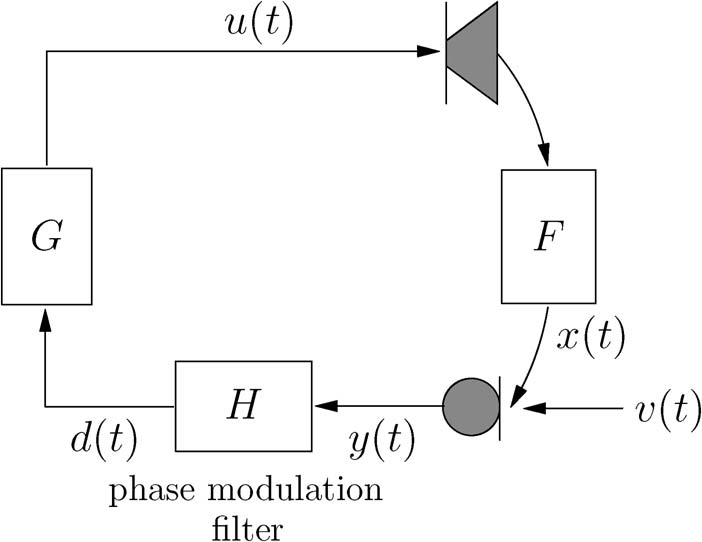
这里 R(s)代表系统的输入,可以理解为外界的激励信号;G(s)代表前向传递函数,可以理解为麦克风拾音到扬声器播放这条路径;H(s)代表反向传递函数,可以理解为扬声器播放到麦克风再次拾取声音这条路径。
同时需要强调的是,啸叫产生的原因是系统的稳定性出了问题,和外界的激励信号没有关系。
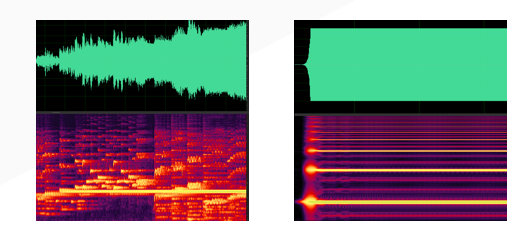
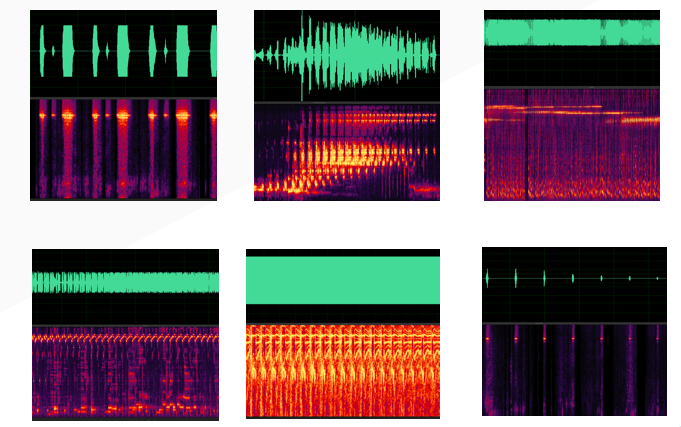
在传统的场景中,由于系统相对稳定,所产生的啸叫具有明显的时频域特征,例如具有稳定的啸叫频点,啸叫的能量逐渐增大,并且会长时间持续产生。下面给出了两个示例。
![]()
针对这一类啸叫场景,往往有两种解决方案,第一类是根据系统的分析,预先针对系统进行更加合理的声学设计(如剧院声学设计、耳机声学设计、指向性麦克风等),第二类是在线进行啸叫检测,根据啸叫的特征,从信号处理的角度检测是否产生啸叫、啸叫频点等,然后利用检测的结果进行啸叫抑制。
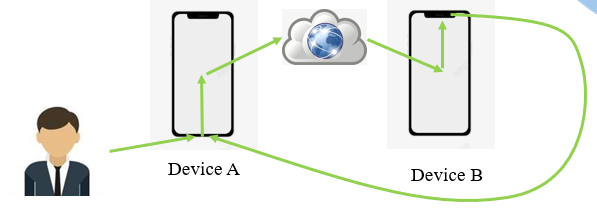
RTC 场景中,当多设备位于同一个物理空间时,同时进入线上会议,此时便会存在多条声学反馈环路,极易导致啸叫的产生。最简单的情况是 2 个移动设备与会,会存在如下的反馈环路。
![]()
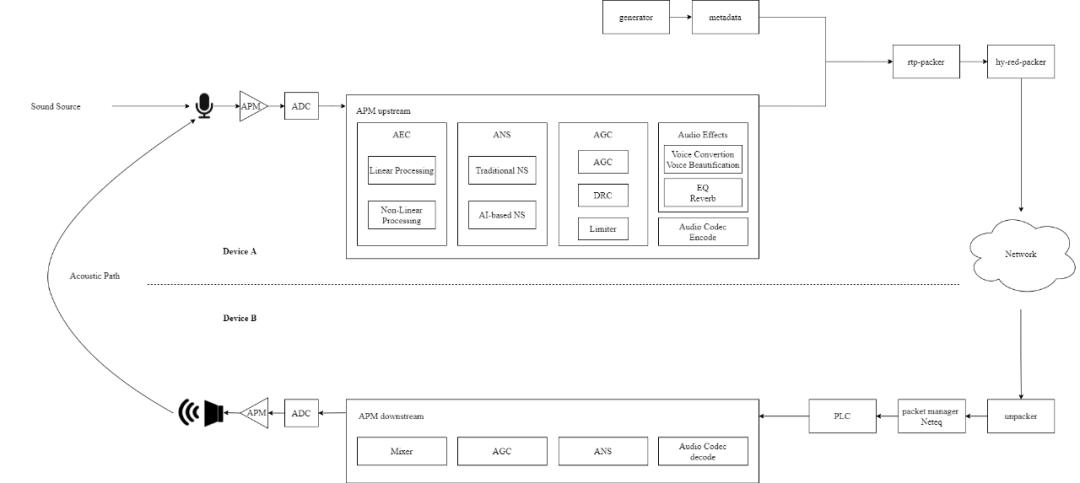
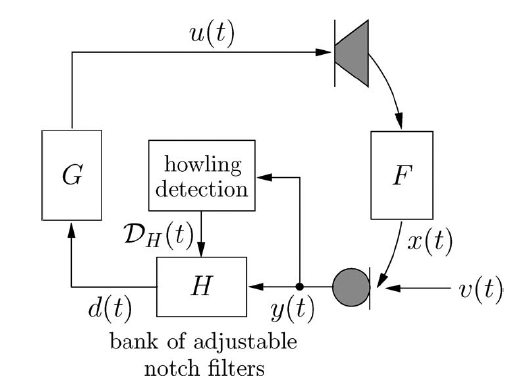
和传统场景不同的是,RTC 场景中啸叫具有复杂性、多样性、非线性等特征,主要是由于 RTC 系统的复杂性带来的,整个系统音频的框图如下。
![]()
由于链路中存在音频算法的处理(典型的如 3A 处理),网络传输的稳定性,环境的多样性,设备的多样性,设备位置的变化等等非线性和多样性因素的存在,整个系统呈现出非线性、时变的特征,从而导致最终啸叫表现出间断性、多频点、频点扩散、频点移动、点叫等等的特征。
![]()
也正是因为场景的复杂性以及啸叫特征的多样性,基于传统的信号处理的检测方案很难准确的捕捉到 RTC 场景下的啸叫特征。而网易云信正是基于场景的深入分析,将 RTC 场景下的啸叫检测问题和 AI 技术相结合,进行创新实践。
首先介绍一下啸叫检测和抑制的传统解决方案,这些方案在传统场景中有着高效的应用。
传统场景下的啸叫具有明显的时频域特征,故可以使用一些信号特征进行检测:
1) 峰值阈值功率比(Peak-to-Threshold Power Raio, PTPR)
啸叫的功率远大于正常播放的音频。故设定一个阈值,只有功率超过阈值的频点,才会进行啸叫检测,减少无意义的检测判决。
![]()
2)峰值均值功率比(Peak-to-Average Power Raio, PAPR)
产生啸叫的频点功率远大于其他频点的功率,故可以先计算出整个频谱的平均功率,然后计算每个频点功率与平均功率之比。比值大于预设阈值的频点,记为候选啸叫频率。
![]()
3)峰值邻近功率比(Peak-to-Neighboring Power Raio, PNPR)
PNPR 寻找功率谱的峰值点,加入候选啸叫频率。可以选取左右各 M 个相邻频点进行比较,当前频点功率比邻值都高时,记为候选啸叫频率,M 选取 5 点左右。
![]()
4)峰值谐波功率比(Peak-to-Harmonics Power Raio, PHPR)
语音谱有谐波峰,而啸叫频率是不含谐波峰的,故可以根据一个峰值点的谐波频率功率是不是也很大,来判断该峰值是否为啸叫点。
![]()
5)帧间峰值保持度(Interframe Peak Magnitude Persistence, IPMP)
IPMP 是时域特征,如果一个频点,连续几帧都是检测出来的候选啸叫峰值,那就认为这个点确实发生了啸叫。实现时可以选定 5 帧,超过 3 帧是候选啸叫频点的位置,判定为啸叫点。
![]()
6)帧间幅度斜率偏差度(Interframe Magnitude Slope Deviation, IMSD)
IMSD 也是时域特征,是从啸叫开始发生时判断
,此时啸叫频点幅度线性增长,帧间斜率将会保持不变。取多帧进行区间观察,计算多帧平均斜率与区间内更短区间的斜率之间的差值,如果差值在设定阈值以下
,就认为该区间斜率保持不变,可能是发生了啸叫。
![]()
频域特征 PTPR、PAPR、PNPR、PHPR 都是对一帧内频点进行分析,而时域特征是对多帧间的特征进行分析。所以在进行判决时,一般先对每帧频谱进行频域特征分析,然后对累计的时域特许证进行分析。
当然,其中的一些特性在某些场景中不一定明显,比如 PHPR,有些啸叫的系统是多频点的,并且高频确实是基频的谐波成分;比如 IMSD,在有外界干扰的情况下,这个特征也会被弱化。
更多优化的方法包括利用谱平坦度、基于时频谱统计分析、结合 VAD 等等,大多也都是基于以上几个特征,进行更细精度的优化,但均存在相对明显的误检,尤其对音乐信号不太友好。在后续的实验中,该研究也选取了一种信号处理方案进行对比。
啸叫产生的原因是系统的幅度响应和相位响应对应的啸叫点的裕度不够,可以试图通过移频或者移相的方法,改变这一特性,使得候选的啸叫点具有足够的裕度,从而改善系统的稳定性。
![]()
但这类方法的最大问题是,移频移相会对信号带来失真。
此方案严重依赖于啸叫频点的检测,根据啸叫频点进行针对性的压制。
![]()
啸叫频点检出之后,进行 notch 陷波器压制。
当然也有一些方法跳过了啸叫频点的检测,使用自适应的 notch filter 进行啸叫抑制。
通过使用 lms 、nlms 等自适应算法,把麦克风二次采集的反馈信号从麦克风信号中滤掉。这种算法会减小扩音系统的空间感,同时对语音损伤较大,适用于对音质要求不高的场景。
![]()
1、移频器:升高或降低输入音频信号的频率,改变频率的输出信号再次进入系统不会和原始信号频率叠加,达到抑制啸叫,这种方法用在对音质要求不高的场景。
然而在 RTC 场景下,啸叫频点会出现扩散特征,故移频无法保证能够完全解决啸叫问题。
2、陷波器:通过降低啸叫频率点处的增益,破坏啸叫产生的增益条件。即对信号中出现的较明显的几个或十几个产生啸叫的频率点降低 db,从而达到抑制啸叫的目的。
然而本方案依赖于精准的啸叫频率检测,但是如前分析,很难在 RTC 场景下估计出准确的啸叫频率。
3、自适应反馈抑制算法:通过使用 lms、nlms 等自适应算法,把麦克风二次采集的反馈信号从麦克风信号中滤掉。这种算法会减小扩音系统的空间感,同时对语音损伤较大,适用于对音质要求不高的场景。
自适应反馈抑制的方法思路类似于AEC,在自激啸叫的场景可以尝试,但是如果抑制存在残留,实际使用中仍会产生较弱的啸叫;然而在 RTC 场景下,啸叫是由两个手机构成的环路形成,啸叫的时候是没有对端的下行参考信号的,故无法实施。
对场景以及传统解决方案的分析,并结合 RTC 场景啸叫的特征,该研究选择使用 AI 模型进行啸叫问题的处理,首先需要准确的检测出啸叫是否发生。
![]()
由于问题的新颖性,目前业界没有 RTC 场景下的开源啸叫数据集。因此该研究基于真实场景,利用网易云信音频实验室等资源,进行了大量的数据采集,完成云信啸叫数据集的构造,总共包括 52h+,并进行了精细的标注。
采集数据主要涉及信号、设备、环境、场景等几个方面。
信号方面,采集的信号为设备麦克风采集并转换传给 3A 算法的输入信号,播放的信号包括语音、音乐、噪声、环境声以及一些特殊的声音,如铃声、鸟叫声、口哨声等。
设备方面,设备频响的多样性以及适配设备 3A 算法的多样性,包括不同性能、样式、处理程度不同的 3A 算法的机型进行覆盖。
环境方面,覆盖安静、嘈杂等不同信噪比、混响的环境。
场景方面,场景主要为啸叫与不啸叫的场景,包括单设备入会、多设备入会,设备处于不同的物理位置等等。
2)由于啸叫的特征与设备、环境等多因素相关,因此模型需要较好的泛化能力;
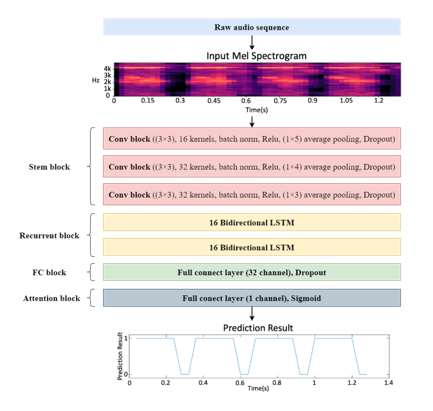
本文针对上述 3 个问题,参考音频事件检测的相关思路和方法,进行了优化。
由于啸叫频率往往处于 8kHz 以内,该研究将所有数据重采样到 16kHz,并设定帧移为 40ms,序列长度设置为 1.28s,然后对数据求 60 维的 log 梅尔谱,并对训练集 + 验证集的数据进行了归一化处理。
![]()
input: 模型的输入为 32 帧的 log 梅尔谱,即(1*32*60);同时经过 norm 操作;
stem block: 包含 3 层 CNN 结构,每层分别包含 16,32,32 个卷积核,卷积核大小为(3,3)、stride 为(1,1),每个 CNN 之后通过 batchnorm 层,ReLu 激活函数,以及 average pool 池化层,池化层的参数分别为(1,5),(1,4),(1,3),之后再加上一层 dropout 防止过拟合;这样通过 CNN 结构进行特征学习,并且将频率维度融合到 channel 维度;
Recurrent blovk: 2 层双向 LSTM,通道数为 32,通过 RNN 结构学习时间上的特征(temporal context information);
FC block: 通过一层线性层过渡,通道数为 32,同样添加了 dropout 层;
Attention block:通过一层线性层达到分类的目的,通道数为 1,激活函数为 sigmoid;
output: 模型的输出为 32 帧,即帧级别的输出。
最终转换为 binary 的结果需要对 sigmoid 的输出进行门限判决,门限默认设为 0.5。
针对误检率的问题,该研究使用了 weighted binary cross entropy loss。
![]()
为了进一步满足 RTC 实时性要求,该研究使用了模型压缩技术,具体使用了基于L1
filter 的剪枝方法以及基于 QAT 的量化方法,这进一步减小了模型的大小和运算量。
针对 RTC 场景,该研究主要使用了检出率 TP 以及误检率 FP 最为评价指标,同时计算了 F1 score 作为参考。
TP(true positive):检出率,实际为真,判断为真, 1->1
TN(true negtive);实际为假,判断为假, 0->0
FP(false positive):误检率,实际为假,判断为真, 0→1
FN(false negtive): 漏检率,实际为真,判断为假, 1→0
P(precision):精准度,TP / (TP + FP),即判断为真的中,正确的数目
R(recall):召回率,TP / (TP + FN),即实际为真的中,检出了多少
F1 socre:2 * P * R / (P + R),即 P 和 R 的几何平均值
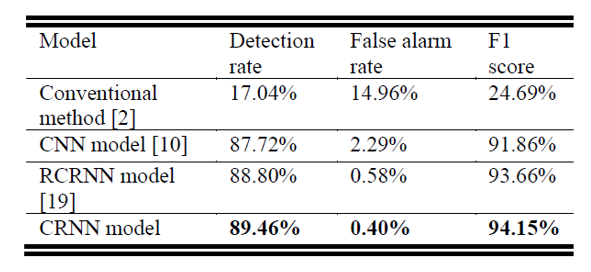
该研究对比了 4 个方法,包括基于信号特征的传统信号处理检测方法;基于 CNN 的神经网络方法;基于 RCRNN 的神经网络方法;以及本文提出的基于 CRNN 的神经网络方法。
1) 基于信号特征的传统信号处理检测方法:结合了 PTPR/PAPR/PNPR/IPMP 四个特征,以及使用了 VAD 作为辅助;
2) 基于 CNN 的神经网络方法: 主体结构使用了 3 层 CNN,相比于 CRNN 的方案,去除了 RNN 层;
3) 基于 RCRNN 的神经网络方法:基于 CRNN 结构,增加了残差卷积结构,并且使用了基于时空卷积的 attention 模块,详细内容可以查看论文参考。
在测试集中,本文方法达到 89.46% 帧级别的检出率,以及 0.40% 帧级别的误检率。
![]()
从实验结果得出,基于神经网络的方法表现明显优于传统的信号处理方法;RNN 结构的使用可以明显降低模型的误检率;尽管更复杂的模型在声音事件检测任务中提供更好的表现,但是更复杂的模型并没有更多的提升其在啸叫检测任务中的表现。
本文针对误检率的分析发现,多数的误检信号集中在具有和啸叫类似特征和听感的信号,例如鸟叫声、口哨声。
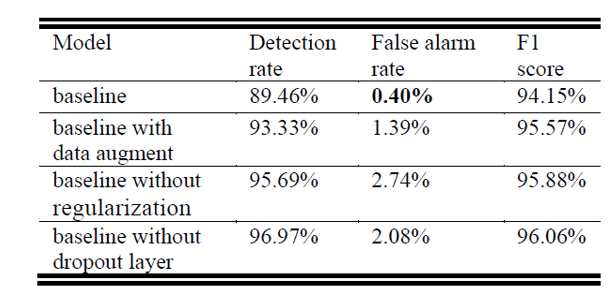
该研究对比了数据增强(变速变调、加噪、谱增强等方法)、参数正则化、dropout 层等优化项的表现。
1)使用数据增强时,该研究在 time strectch/pitch shift/frame shift/add gaussian noise/time mask/frequency mask 等 6 种方法中,随机选取若干种进行数据扩充,并重复 4 次,这样可以获得 5 倍的实验数据;
2) 该研究尝试了在训练时不加入参数正则化的操作;
3) 该研究尝试了在模型中各层 (CNN/FC) 不加入 dropout 层。
![]()
从实验结果得出,数据增强可以有效地提升检出率和 F1 score,尤其是 F1 score,作为声音时间检测的一项指标,数据增强会有效提升任务表现,但是对于啸叫检测任务而言,由于误检率也明显提升,对于实际应用并没有明显的帮助;去除了参数正则化和 dropout 层并没有导致所谓的过拟合现象,在测试集中仍然有较好的表现,尤其是检出率和 F1 score,但是同样,会进一步提升误检率,对于啸叫检测的特定任务,并没有表现出更好的效果。
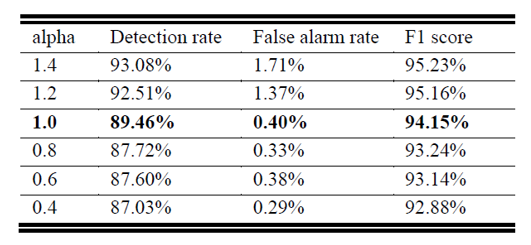
此实验验证了不同α系数对检出率和误检率的影响。可以看出,α小于 1 的取值,会进一步降低误检率,更适用于本文的应用场景;而α大于 1 的取值,可以有效地提升检出率。对于相关任务,可以针对检出率或者误检率的要求,有借鉴意义。
![]()
最后,实验使用了基于 L1 filter 的剪枝方法以及基于 QAT 的量化方法,模型大小从 121kB 压缩到 39kB,检出率从 89.46% 略微降低到 87.84%,误检率从 0.40% 略微增加到 0.49%。
在模型速度上,在华为 X10 手机上进行实验,每 10ms 数据的最大处理时间约 62.5us。
本文中,从啸叫产生的场景、产生的原因及特征进行了详细介绍,并且分析了传统的基于信号特征的解决方案,及其在 RTC 场景中的不足,最后介绍了基于 AI 的啸叫检测方案,论文的主要贡献在于将啸叫问题和神经网络进行了深度的结合,在效果和性能表现上都达到了较为理想的状态。
啸叫检测的结果将会为后续的啸叫抑制提供有力的支持,从应用角度来看,可以利用检测的结构通知用户,或者进行静音、降低音量操作,当然,更加理想的方式是能够将啸叫信号进行消除,同时最大程度上保留有用的信号。这一点有一点类似降噪的思路,所以该研究后续也会深度结合 AI 啸叫检测和 AI 噪声抑制,进一步提升用户的体验。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com