应对个性化定制语音合成挑战,微软推出AdaSpeech系列研究

(本文阅读时间:15 分钟)
语音个性化定制(custom voice)是一项非常重要的文本到语音合成(text to speech, TTS)服务。其通过使用较少的目标说话人的语音数据,来微调(适配)一个源 TTS 模型,以合成目标说话人的声音。但当前语音个性化定制仍面临一系列挑战:1)为了支持不同类型的说话人,源 TTS 模型需要支持不同类型的声学条件,比如不同的口音、说话风格、录音环境等,这可能与训练源TTS模型使用的声音数据的声学条件并不相同;2)为了支持大量的说话人,需要减少声音定制过程中使用的目标说话人的数据以及适配参数,以实现高效的声音定制化。
面对以上挑战,微软亚洲研究院机器学习组和微软 Azure 语音团队合作推出了 AdaSpeech 1/2/3 系列工作,旨在实现更有泛化性且更高效的语音个性化定制:
1) AdaSpeech 1 (Adaptive Text to Speech for Custom Voice) 主要提升源 TTS 模型的鲁棒泛化性,以更好地支持不同类型的说话人;同时降低模型的适配参数量,以更好地支持更多数量的说话人。
2)AdaSpeech 2 (Adaptive Text to Speech with Untranscribed Data) 支持目标说话人仅使用无文本标注的语音数据进行声音的定制,实现了和有文本标注的语音数据相当的适配语音质量。
3)AdaSpeech 3 (Adaptive Text to Speech for Spontaneous Style) 主要针对自发风格的语音(spontaneous-style speech)设计了高效的定制化方法,以实现此类语音风格的定制。
AdaSpeech 1/2/3 系列相关研究论文已分别收录于 ICLR 2021 / ICASSP 2021 / INTERSPEECH2021 三个顶级学术会议。同时,该系列研究工作也被应用于微软 Azure TTS 语音合成技术,以构建更好的语音定制化服务。
详情可查看:
https://speech.microsoft.com/customvoice
AdaSpeech: Adaptive Text to Speech for Custom Voice, ICLR 2021
链接:https://arxiv.org/pdf/2103.00993.pdf
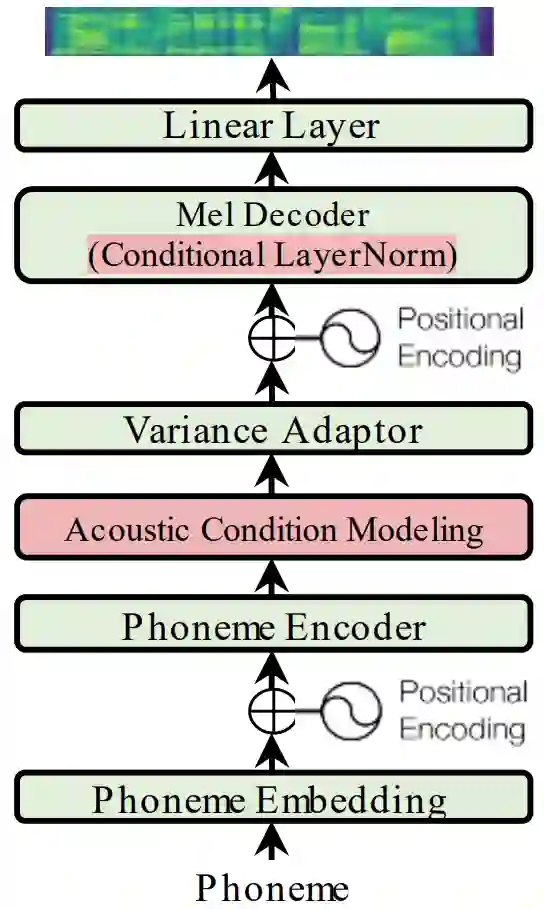
为了支持不同类型的目标说话人和不同的声学条件,以及降低适配过程中的模型参数量,微软亚洲研究院和微软 Azure 语音团队的研究员们提出了一个可适配的 TTS 系统—— AdaSpeech,来实现高质量和高效率的声音个性化定制。AdaSpeech 以 FastSpeech2 为基本的模型框架,如图1所示。其含有两个重要的模块:
1)不同粒度的声学条件建模(acoustic condition modeling),用以支持含有不同类型声学条件的语音数据;
2)将自适应层归一化(conditional layer normalization)应用于模型解码器,微调模型时,只调整自适应层归一化的参数以降低适配参数及保证高的定制音质。
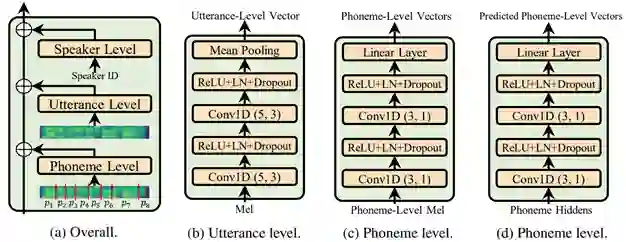
声学条件建模(acoustic condition modeling)的结构如图2所示。研究员们将声学条件建模分为三个粒度:说话人级别(speaker level)、句子级别(utterance level)和音素级别(phoneme level),如图2(a) 所示。在说话人级别,可以采用常见的说话人嵌入向量来刻画说话人的特征。在句子级别,可以使用一个声学编码器来从参考语音中抽取句子级特征,如图2(b)所示,在训练过程中使用目标语音作为参考语音,而在测试中,则随机选用该说话人的其它语音来作为参考语音。在音素级别,可以使用另一个声学编码器从目标语音中抽取音素级别的特征,如图2(c)所示,同时,还可以通过训练另一个音素级别的声学预测器,来预测这些特征,以便在测试时使用,如图2(d)所示。
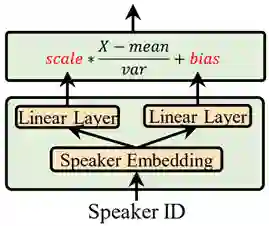
自适应层归一化(conditional layer normalization)的结构如图3所示。在语音解码器的每一层中,自适应层归一化通过两个线性层,从说话人嵌入表征里预测出层归一化的 scale 和 bias 参数,以更加自适应地调节模型的隐层表征。而在适配过程中,则只需要调整自适应层归一化的相关参数,就可以极大降低调整参数量,并且同时保证了定制音质。
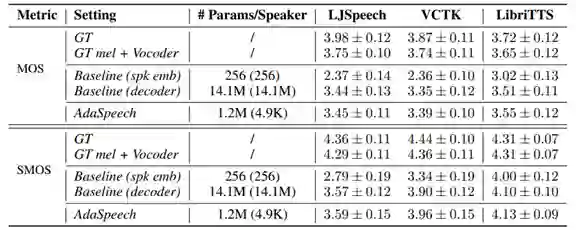
研究员们在 LibriTTS 数据集上训练了源 TTS 模型,然后在 VCTK 和 LJSpeech 上进行了语音定制。对于每个定制的说话人,只使用了20条语音进行模型适配。结果如表1所示,可以看出:1)和基线 (spk emb) 相比,AdaSpeech 在极低的适配参数下(4.9K),取得了极大的定制音质提升;2)和基线 (decoder) 相比,AdaSpeech 在相同或略微好的定制音质下,能极大降低所需参数量(4.9K vs 14.1M),很好地满足了语音个性化定制场景的需求。
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data, ICASSP2021
链接:https://arxiv.org/pdf/2104.09715.pdf
常见的语音定制化方法通常使用语音数据及其对应的文本数据(transcription)来微调一个源 TTS 模型,以合成目标说话人的声音。然而,在许多应用场景中,通常只能获取到没有转录文本(无标注)的语音数据(untranscribed speech)。使用语音识别系统(ASR)来获得对应文本是一种较为直接的方法,但其需要引入冗余的语音识别系统,同时会带来文本识别误差,从而造成语音适配效果的下降。另有一些研究尝试直接使用无标注语音数据来微调模型,但这类方法大多需要源 TTS 模型和用于微调的模块联合训练,限制了方法的可扩展性。
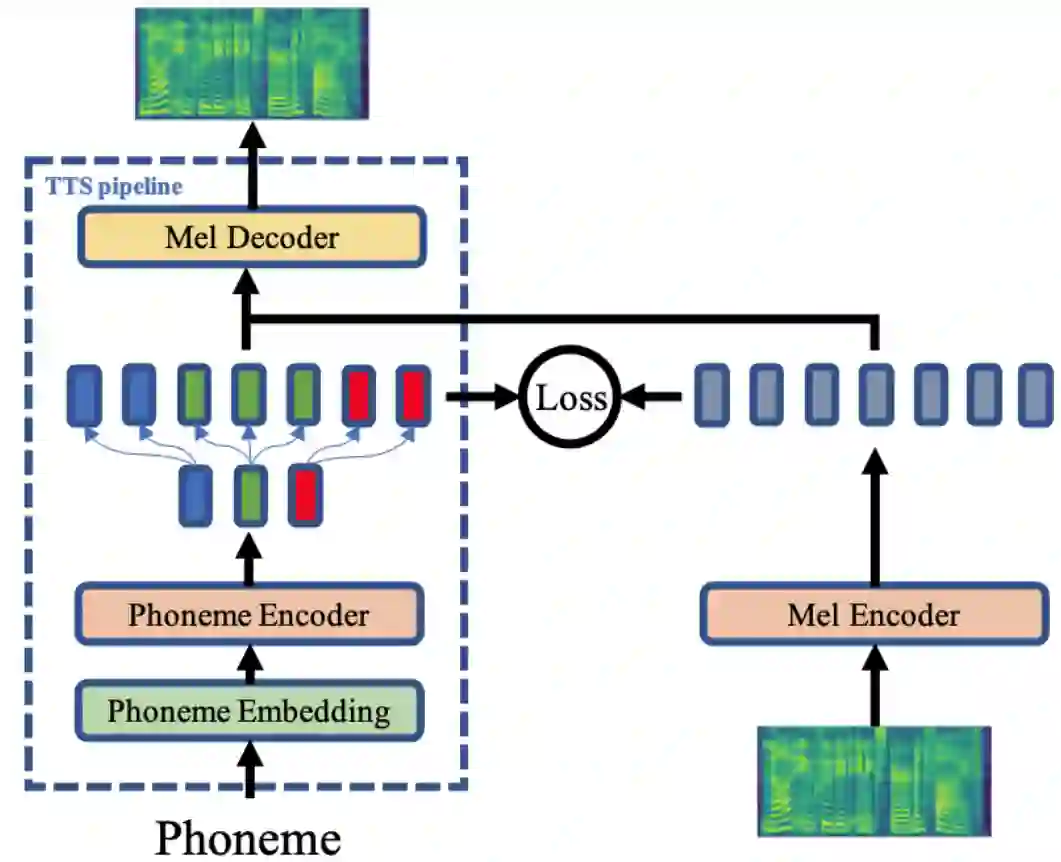
因此,微软亚洲研究院和微软 Azure 语音团队的研究员们提出了 AdaSpeech 2,这是一种可直接利用无标注语音数据进行 TTS 模型微调的方法。如图4所示,该方法在 AdaSpeech 的基础上引入了一个梅尔谱编码器(mel-spectrogram encoder),并且使用 L2 损失来约束音素编码器(phoneme encoder)和梅尔谱编码器的输出空间,从而直接利用语音数据来对训练好的源 TTS 模型中的相关参数进行微调,以进行语音合成的定制化。该方法有两点优势:
1)可插拔性,该方法关键在于引入额外的编码器,因此可以方便地在其它编码器-解码器结构的 TTS 模型中进行推广,而不依赖新模块与源模型的联合训练;
2)有效性,在使用相同数据量的条件下,该方法与需要对应文本的微调方法相比,达到了相同水平的语音合成效果。
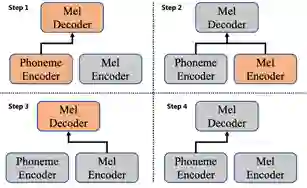
Adaspeech 2 方法包含四个步骤,如图5所示:1)源模型的训练(source model training):使用大量数据训练一个仅包含音素编码器和梅尔谱解码器的语音合成系统。2)梅尔谱编码器的引入与对齐(mel-spectrogram encoder aligning):引入并激活梅尔谱编码器,固定源 TTS 模型中的音素编码器和梅尔谱解码器参数进行训练。在该步中,一个用以约束音素编码器和梅尔谱编码器输出空间的 L2 损失被引入到模型中,并且只更新梅尔谱编码器的参数。之后研究员们继续使用大量的多人文本-语音数据进行该步的训练。3)基于无标注文本数据的个性化适配。获得了目标人的无文本语音数据后,研究员们激活了梅尔谱编码器和梅尔谱解码器,并将目标数据同时作为输入和目标输出进行训练(类似一个语音重建过程)。在该步中,研究员们参照 AdaSpeech 的做法,微调了梅尔谱解码器中的少量参数。4)定制化语音合成。
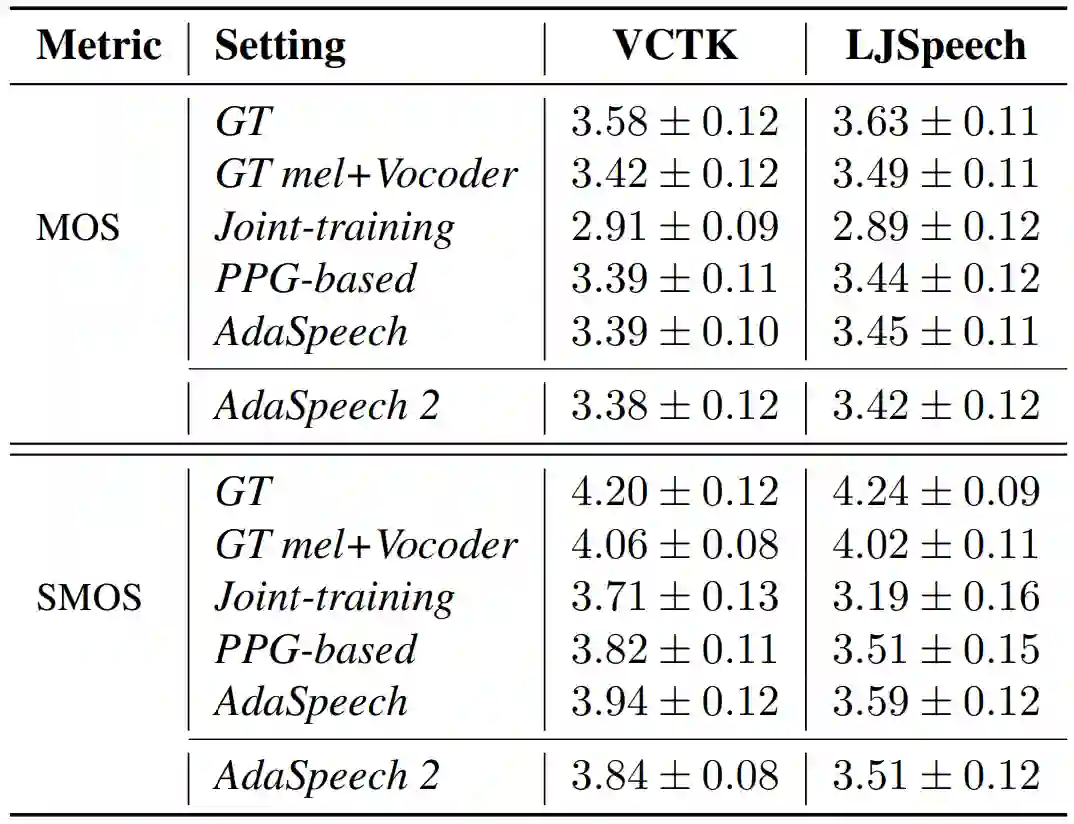
研究员们在 LibriTTS 数据集上训练了源 TTS 模型,然后在 VCTK 和 LJSpeech 上进行了语音定制。对于每个定制的说话人,研究员们使用了50条语音进行模型适配。结果如表2所示,可以看出:1)该方法实现了可与目标的真实语音和两种上限算法(AdaSpeech,PPG-based)匹敌的声音合成质量;2)在声音相似度上,该方法略逊于上限算法 AdaSpeech,但仍优于流行的基于 joint-training 的方法。并且,该方法继承了 AdaSpeech 的各种优点,极大拓宽了语音个性化定制的应用场景。
AdaSpeech 3: Adaptive Text to Speech for Spontaneous Style, INTERSPEECH 2021
链接:https://arxiv.org/pdf/2107.02530.pdf
现有的语音合成系统在合成朗读风格(reading-style)的语音时表现良好,但在合成自发风格(spontaneous-style,例如演讲或谈话时人的自然讲话风格)的语音时却遇到了挑战。其主要原因有:1)自发风格的语音数据集较为稀少,不足以训练一个源 TTS 系统;2)建模自发风格语音中的关键性因素:有声停顿(filled pauses,例如 um/uh 等语气助词)以及语调变化(diverse rhythms)较为困难。为此,研究员们又提出了针对自发风格语音的定制化语音合成系统 —— AdaSpeech 3。
AdaSpeech 3 有以下三个创新点:1)为了使合成的语音具有自发风格的特点,研究员们引入了有声停顿预测器(FP predictor)来为合成的语句插入有声停顿。2)为了使合成的语音在语速和语调上更加多变,研究员们引入了基于混合专家系统(mixture of experts, MoE)的语速预测器来控制语速。该语速预测器包含三个语速档次,并分别控制语音以不同的速率生成,如图6所示。3)为了使合成的语音更贴近目标音色,AdaSpeech 3 需要微调模型中的少量参数。另外,研究员们针对训练数据不足的问题,还开发了一套数据挖掘的工作流程,并通过该流程,从互联网上挖掘出自发风格的语音数据集。该数据集的相关统计见表3所示。有声停顿预测器和语速预测器具体的训练流程可参考 AdaSpeech 3 论文。
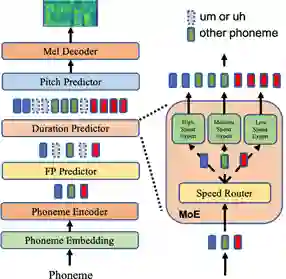

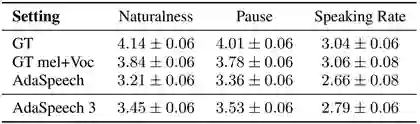
在实验方面,研究员们在 LibriTTS 数据集上训练了源 TTS 模型,并利用挖掘出的风格和自发的语音数据集,来训练额外的有声停顿预测器和语速预测器,从而使得生成的语音具有更高的随意性,更贴近日常对话。从合成语音的音质结果来看,该方法相对于 AdaSpeech 在语音自然度、停顿合适度和语速等主观 MOS 指标上均有提升,如表4。研究员们还进行了消融实验验证了各个设计模块的有效性。在对不同目标人说话声音的模仿上,AdaSpeech 3 在相似度指标 SMOS 上亦有提升。综上所述,AdaSpeech 3 提升了语音合成系统在模仿自然人语音的效果,也提升了合成语音的真实感。
AdaSpeech 系列相关研究论文已分别收录于 ICLR 2021 / ICASSP 2021 / INTERSPEECH 2021 三个顶级学术会议。同时,该系列研究工作也被应用于微软 Azure TTS 语音合成技术,以构建更好的语音定制化服务。微软亚洲研究院机器学习组一直致力于语音方面的相关研究,包括语音合成、语音识别、歌声合成及音乐生成等。
了解更多关研究工作可访问:
https://speechresearch.github.io/
试用微软Azure语音合成服务请访问:
https://azure.microsoft.com/en-us/services/cognitive-services/text-to-speech/
相关链接:
https://www.microsoft.com/en-us/research/people/xuta/
https://www.microsoft.com/en-us/research/project/text-to-speech/
https://speech.microsoft.com/customvoice
https://azure.microsoft.com/en-us/services/cognitive-services/text-to-speech/
你也许还想看:









