嘈杂场景语音识别准确率怎么提?脸书:看嘴唇
明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
借助读唇语,人类能够更容易听懂他人的讲话内容,那么AI也能如此吗?
最近,Meta提出了一种视听版BERT,不仅能读唇语,还能将识别错误率降低75%。
效果大概就像如下这样,给一段视频,该模型就能根据人物的口型及语音输出他所说的内容。

而且与此前同类方法相比,它只用十分之一的标记数据,性能就能超过过去最好的视听语音识别系统。
这种结合了读唇的语音识别方法,对于识别嘈杂环境下的语音有重大帮助。
Meta的研究专家Abdelrahman Mohamed表示,该技术未来可用在手机智能助手、AR眼镜等智能设备上。
目前,Meta已将相关代码开源至GitHub。
自监督+多模态
Meta将该方法命名为AV-HuBERT,这是一个多模态的自监督学习框架。
多模态不难理解,该框架需要输入语音音频和唇语视频两种不同形式内容,然后输出对应文本。
Meta表示,通过结合人们说话过程中嘴唇和牙齿活动、语音方面的信息,AV-HuBERT可以捕捉到音频和视频间的微妙联系。
这和人类本身感知语言的模式很相似。
此前已经有研究表明,阅读唇语是人类理解语言的一种重要方式。尤其是在嘈杂的环境下,通过读唇可以将语言识别的准确性最高提升6倍。
在该模型中,通过一个ResNet-transformer框架可将掩码音频、图像序列编码为视听特征,从而来预测离散的集群任务序列。
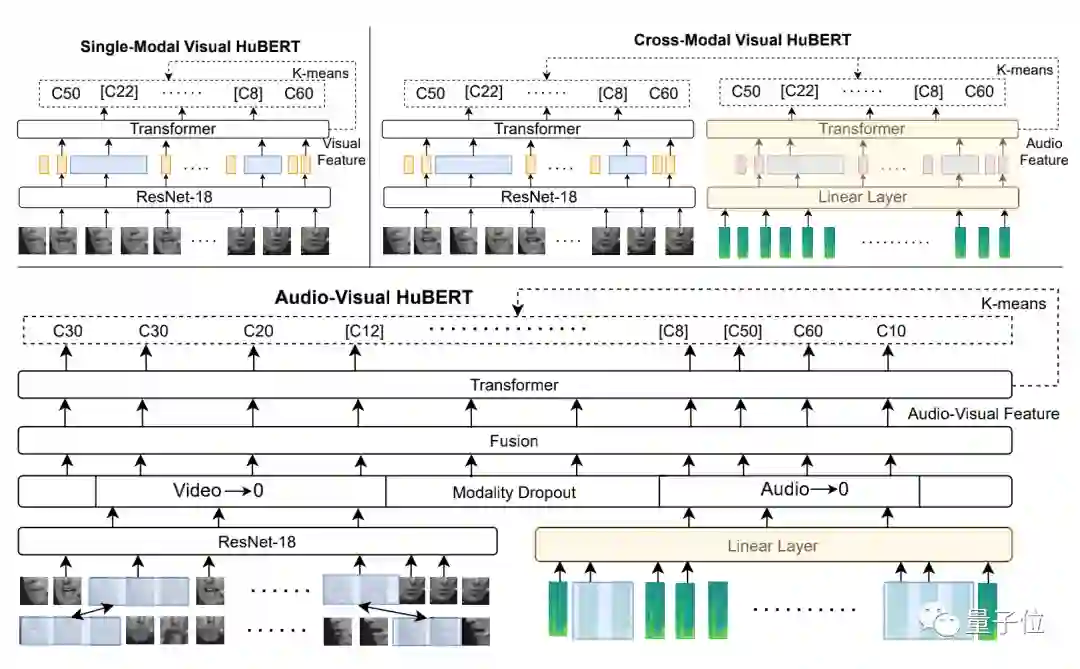
具体来看,AV-HuBERT使用帧级同步的音频流和视频流作为输入,来更好地建模和提取两种模态之间的相关性。
图像序列和音频特征能够通过轻量级的模态特定编码器来产生中间特征,然后将这个中间特征融合并反馈到共享的主干transformer编码器中,以此来预测掩蔽聚类任务 (masked cluster assignments)。
该目标是根据聚类音频特征或AV-HuBERT模型上一次迭代中提取的特征生成的。
当对唇读微调时,该模型只使用视觉输入、不使用音频输入。
结果表明,AV-HuBERT经过30个小时带有标签的TED演讲视频训练后,单词错误率(WER)为32.5%,而此前方法能达到的最低错误率为33.6%,并且此方法训练时间高达31000个小时。
WER是语音识别任务中的错误率指标,计算方法为将错误识别单词数除以总单词数,32.5%意味着大约每30个单词出现一个错误。
经过433个小时TED演讲训练后,错误率可进一步降低至26.9%。

另一方面,AV-HuBERT与前人方法最大不同之处在于,它采用了自监督学习方法。
此前DeepMind、牛津大学提出的方法中,由于需要对数据集打标签,使得可学习的词汇范围受到限制。
AV-HuBERT在预训练中使用特征聚类和掩蔽预测两个步骤不断迭代训练,从而实现自己学习对标记的数据进行分类。
这样一来,对于一些音频数据集很少的语言,AV-HuBERT也能很好学习。
在使用不到十分之一的标记数据(433小时/30小时)情况下,该方法可将识别错误率平均降低至此前方法的75%(25.8% vs 5.8%)。
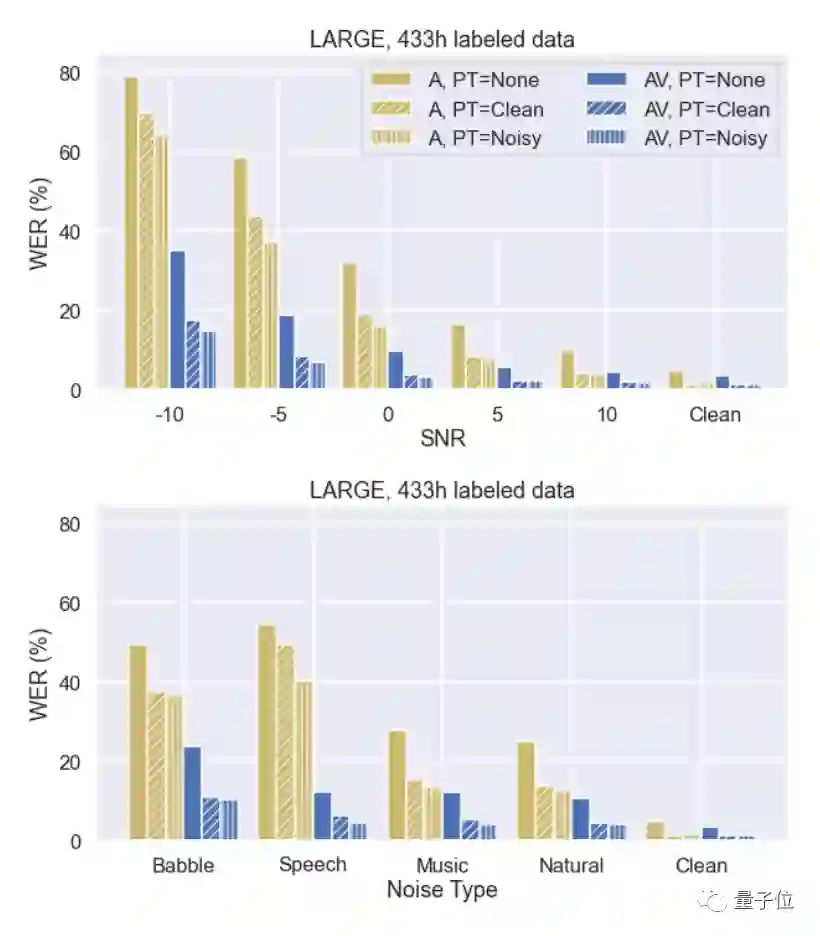
事实上,在有噪音的环境中,能读唇语的语音识别方法更能大显身手。
Meta研究人员表示,当语音和背景噪音同样音量时,AV-HuBERT的WER仅为3.2%,而之前的最佳多模态模型为25.5%。
仍存在弊端
显然,在各方面数据上,Meta新方法的表现着实让人眼前一亮。
但是基于现实使用方面的考虑,有学者提出了一些担忧。
其中,华盛顿大学的人工智能伦理学专家Os Keye就提到,对于因患有唐氏综合征、中风等疾病而导致面部瘫痪的人群,依赖读唇的语音识别还有意义吗?
对此,Meta方面研究人员回应称,AV-HuBERT方法更多关注于唇部动作,并非整个面部。
而且与大多数AI模型类似,AV-HuBERT的性能“与训练数据中不同人群的代表性样本数量成正比”。
论文地址:
https://arxiv.org/abs/2201.02184
https://arxiv.org/abs/2201.01763
GitHub地址:
https://github.com/facebookresearch/av_hubert
参考链接:
https://venturebeat.com/2022/01/07/meta-claims-its-ai-improves-speech-recognition-quality-by-reading-lips/
— 完 —
量子位招聘


量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !




