达摩院技术创新全景|懂你的语音AI

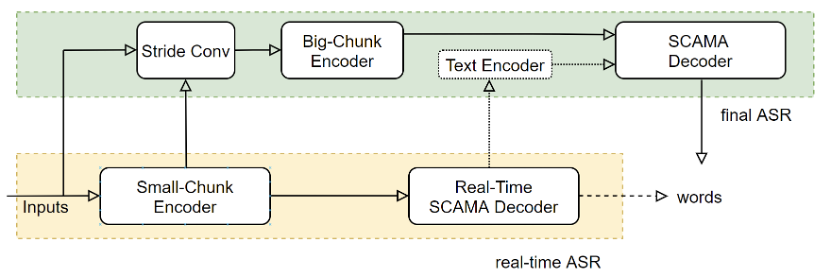
1.1 语音识别基础框架
-
低延迟实时听写:如电话客服,IOT语音交互等,该场景对于尾点延迟非常敏感,通常需要用户说完以后立马可以得到识别结果。
-
流式实时听写:如会议实时字幕,语音输入法等,该场景不仅要求能够实时返回语音识别结果,以便实时显示到屏幕上,而且还需要能够在说话句尾用高精度识别结果刷新输出。
-
离线文件转写:如音频转写,视频字幕生成等,该场景不对实时性有要求,要求在高识别准确率情况下,尽可能快的转录文字。
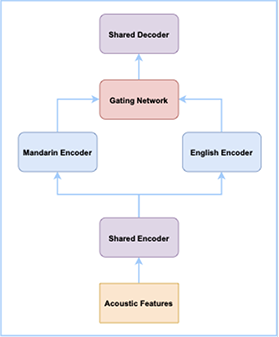
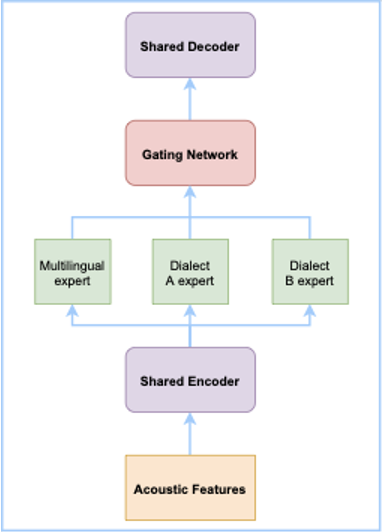
1.2 鸡尾酒会问题
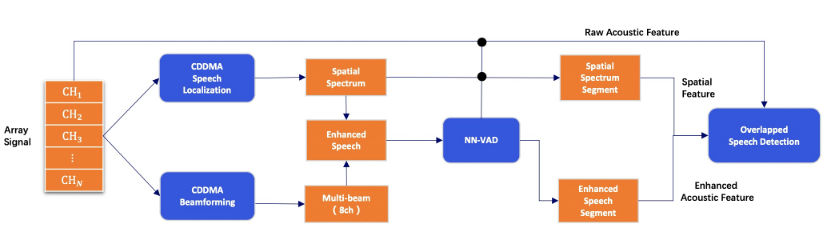
-
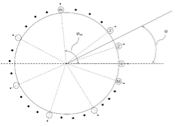
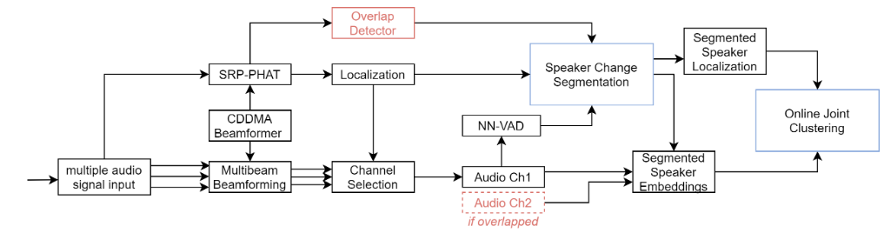
波束形成和声源定位:对于原始8通道阵列信号我们首先采用阵列信号处理算法来获得声源空间信息和增强的语音信号。
-
语音分割:对于增强后的语音信号,我们采用基于神经网络的语音端点检测模型来将语音分割成短的片段。同时切分的时间戳也会用于声源空间分布频谱的切分。
-
混叠语音检测:我们探索采用神经网络来进行混叠语音检测,验证了不同的输入特征对于系统性能的影响。
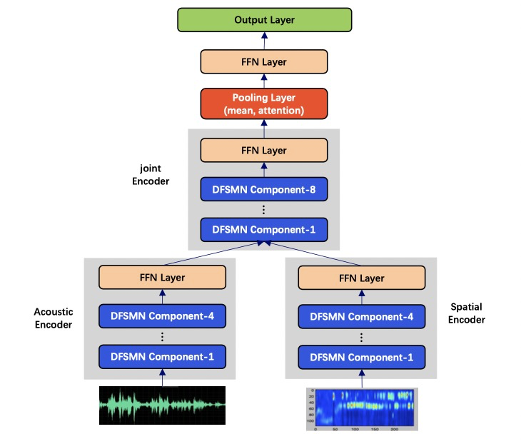
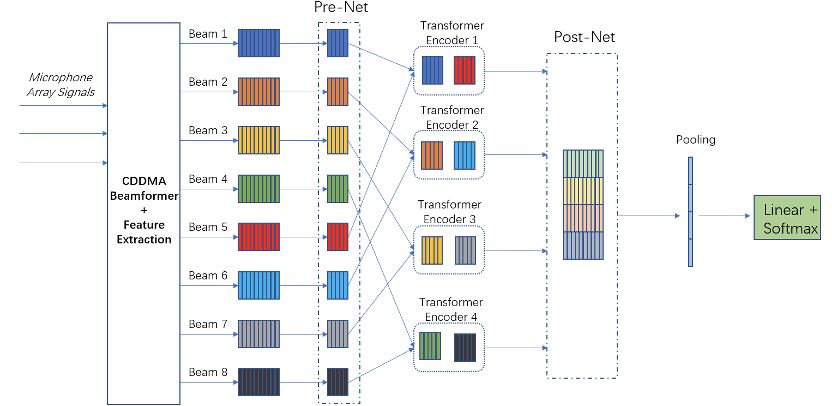
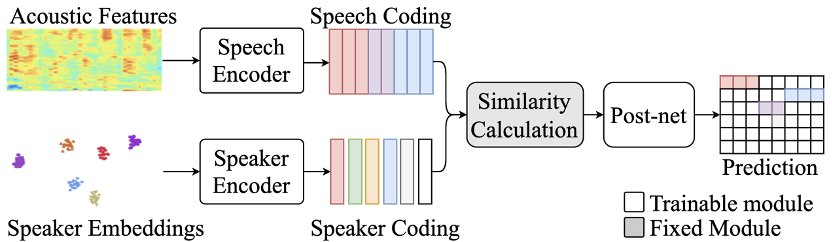
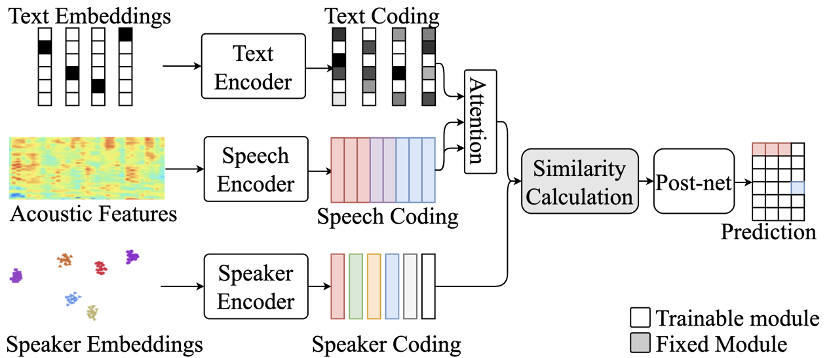
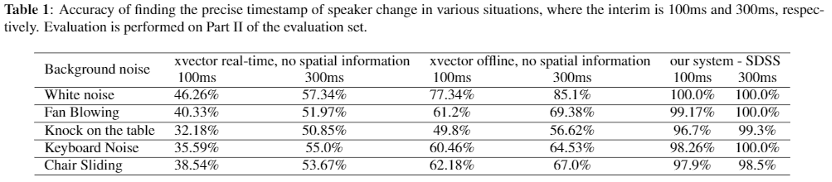
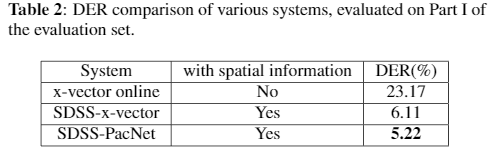
2.1 基于多通道会议场景的Speaker Diarization任务
2.2 嘈杂环境下的说话人自适应噪声过滤及说话人识别
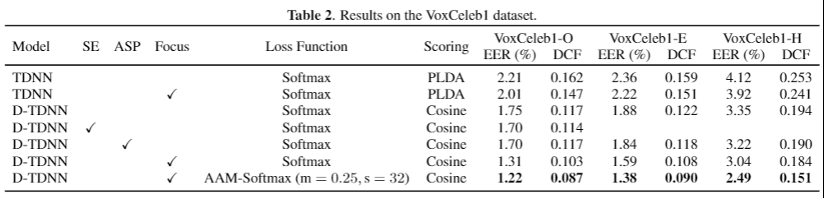

2.3 基于图神经网络的说话人无监督训练
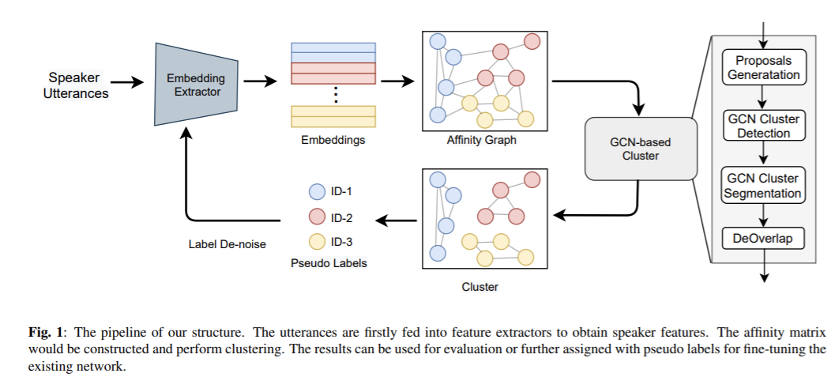
3.1 高表现力声码器——HIFI-TTS
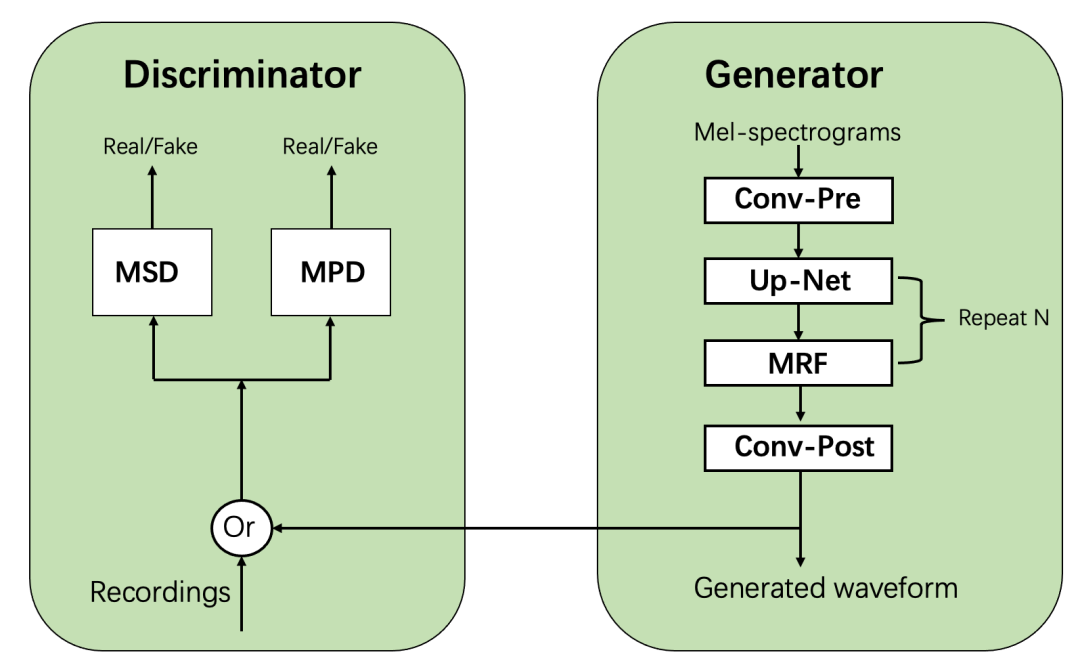
-
Hifi-TTS 引入基于生成对抗网络(GAN)的连续变量建模。不同于先前采用交叉熵训练的离散变量建模的 wavenet,wavernn,LPCNet,引入 Discriminator 区分真实录音/生成声音的分布来指导声码器(Generator)的训练。模型通过 MSD 建模语音中信号的平稳特性,通过 MPD 建模语音中不同频率成分的周期特性,从而达到对声音更好的还原效果。
-
为支持48k高采样率的声音生成,对 Discriminator, Up-Net, MRF 的结构进行相应改造,使其在48k采样率下有更稳定的合成效果。
|
|
|
CMOS gain |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
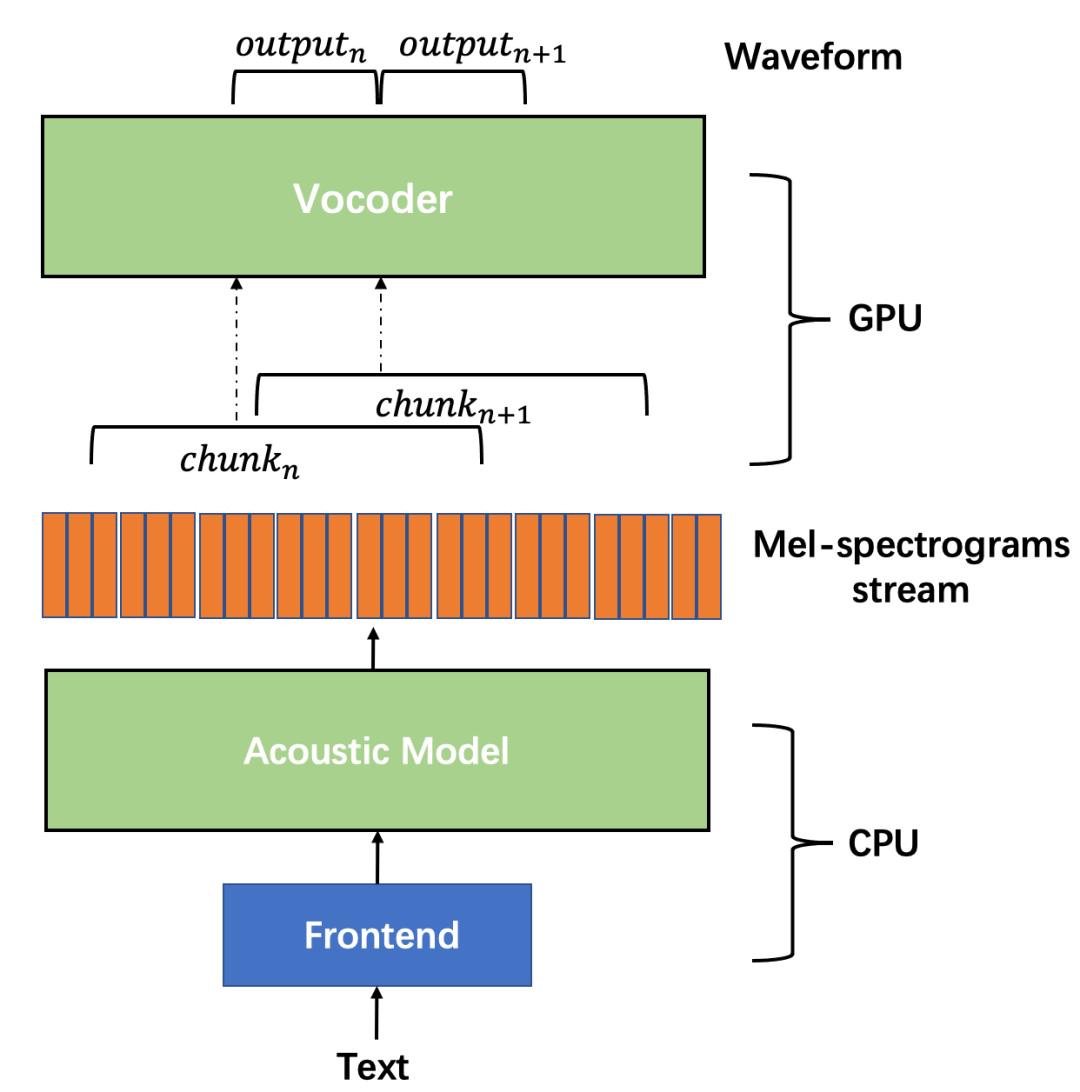
-
声码器 (vocoder)-on-GPU 的异构方案。不同于先前逐点生成的自回归声码器,新一代非自回归声码器可支持并行生成。并行生成效率更高,更适合发挥 GPU 本身的计算优势,从而提高整个语音合成系统的实时性。
-
非自回归声码器流式方案。通过声码器的 chunk 机制和声学模型 (Acoustic Model) 相配合,在显存占用、运行效率上优于非流式方案, 可支持 HIFI-TTS 系统在 GPU 下的高效流式服务。
3.2 高表现力声学模型
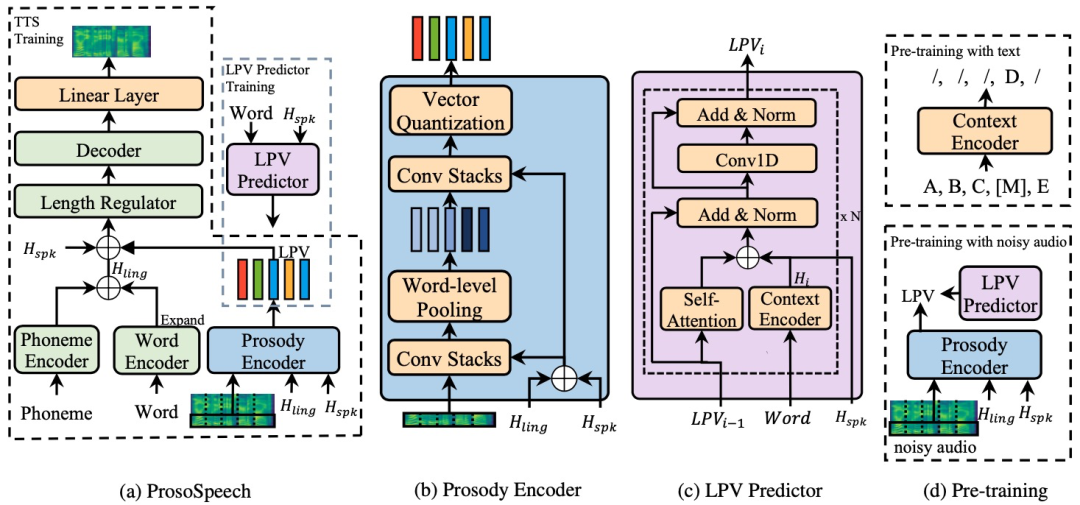
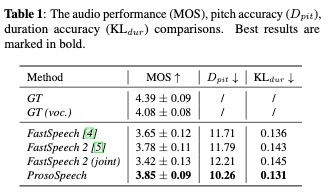
4.1 口语语言处理(SLP)
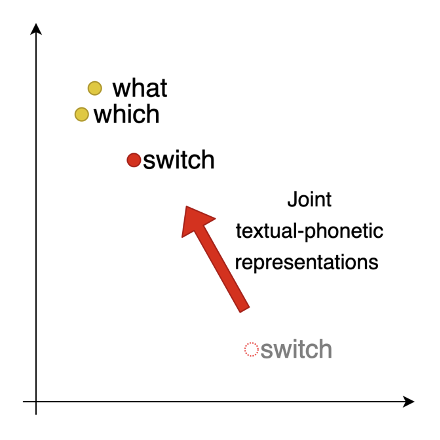
4.2 联合文本和音素表征学习
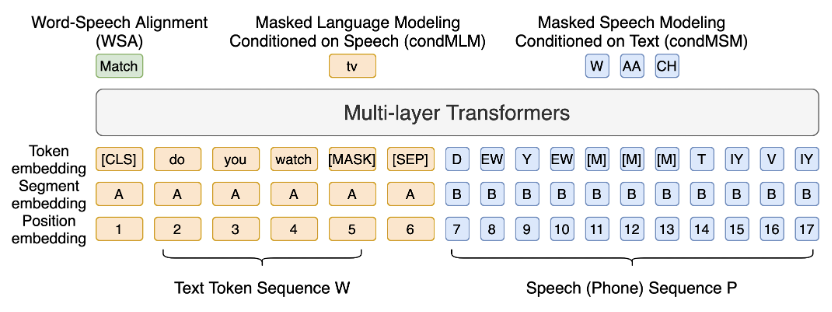
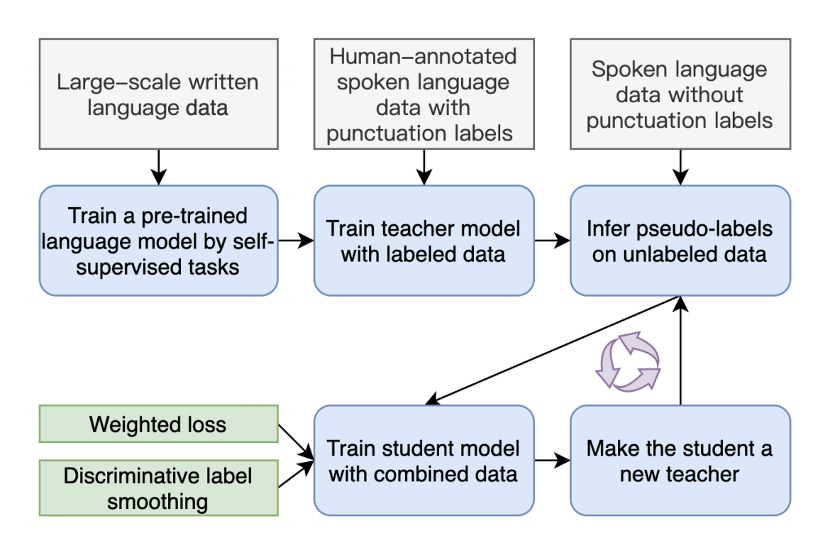
4.3 区分式自学习的标点技术
4.4 自适应滑窗的篇章分割技术
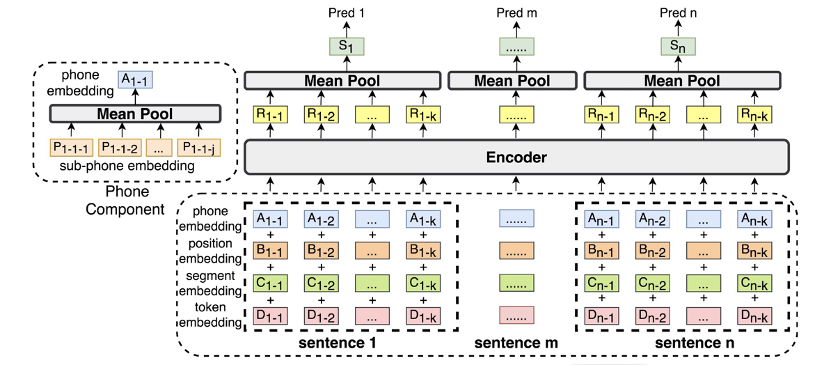
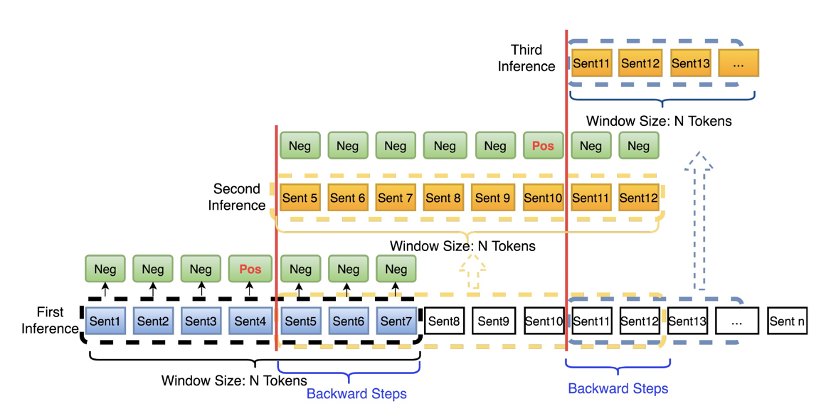
4.5 基于池化的长文本建模技术
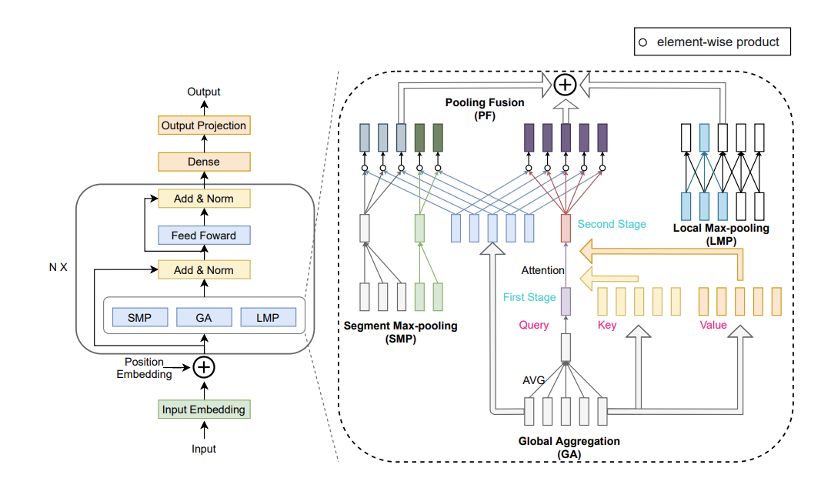
4.6 基于掩码的关键词抽取技术

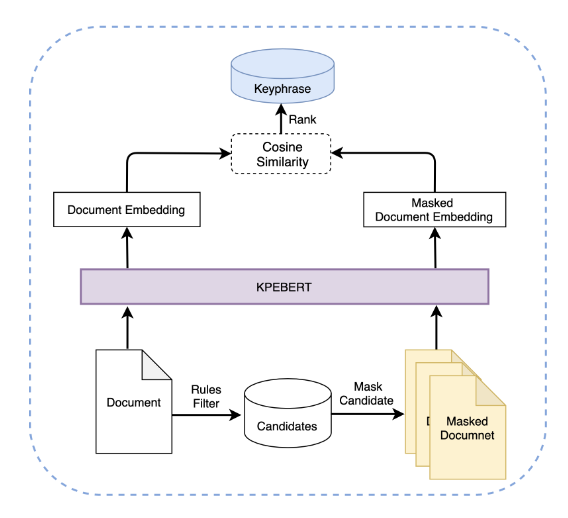
5.1 自适应麦克风阵列信号处理
5.2 引入关键词mask进一步提升在极低信噪比和散射噪声场景下的唤醒性能
5.3 完善的多通道远场数据模拟工具, 可在训练阶段引入完全的数据匹配
5.4 基于关键词检测模型的多路信息融合和通道选择机制,提升关键词检测性能,降低计算量
5.5 推理阶段的前后端反馈联动
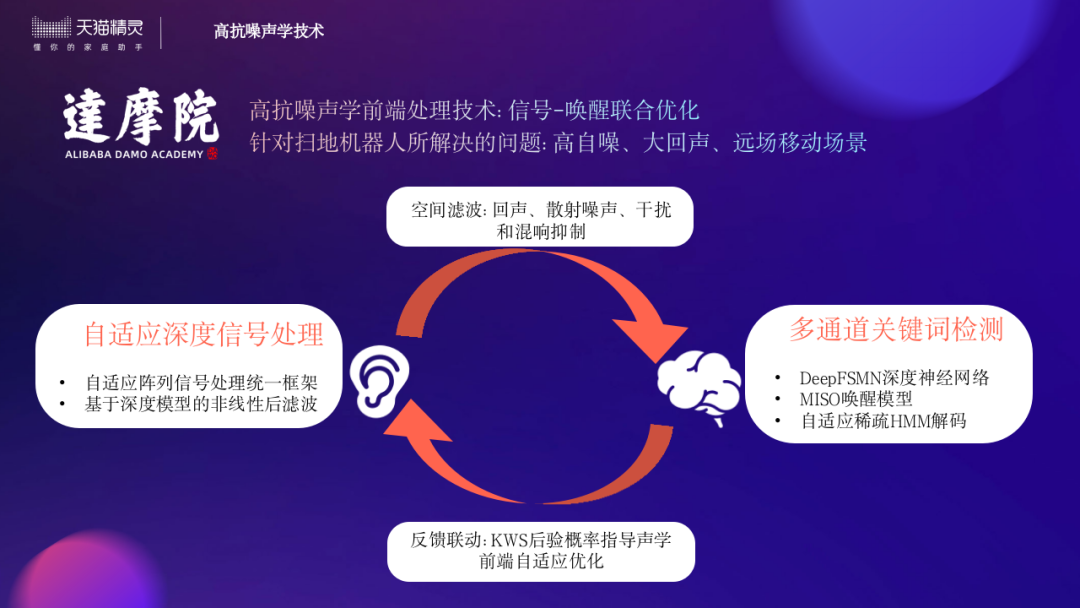
对行进间的扫地机器人直接进行语音交互操作所面临的问题是高自噪、大回声、移动远场和低算力,每一项都具有超出一般家居智能硬件产品的难度。基于信号处理和唤醒的联合优化算法方案,我们与天猫精灵共同合作推出高性能木星模组,有效地解决了以上问题,大幅提升了移动高噪场景下的语音交互效果,在业界树立了新标杆。初版6mic算法支持了业界首款语音交互扫地机;通过信号处理和唤醒的联合优化,唤醒率较语音增强+多路关键词检测的基线系统相对提升近10%,且虚警率下降了30多倍,关键词检测模块的计算量相对下降50%多,并经离线验证mic个数降为3/4mic时,性能下降幅度也在可接受范围之内,进一步提升了性价比和降低装配难度。经内部严谨的对比测试,经过算法升级某客户的唤醒率指标在相同噪声声压级下均高于后期出现的竞品。
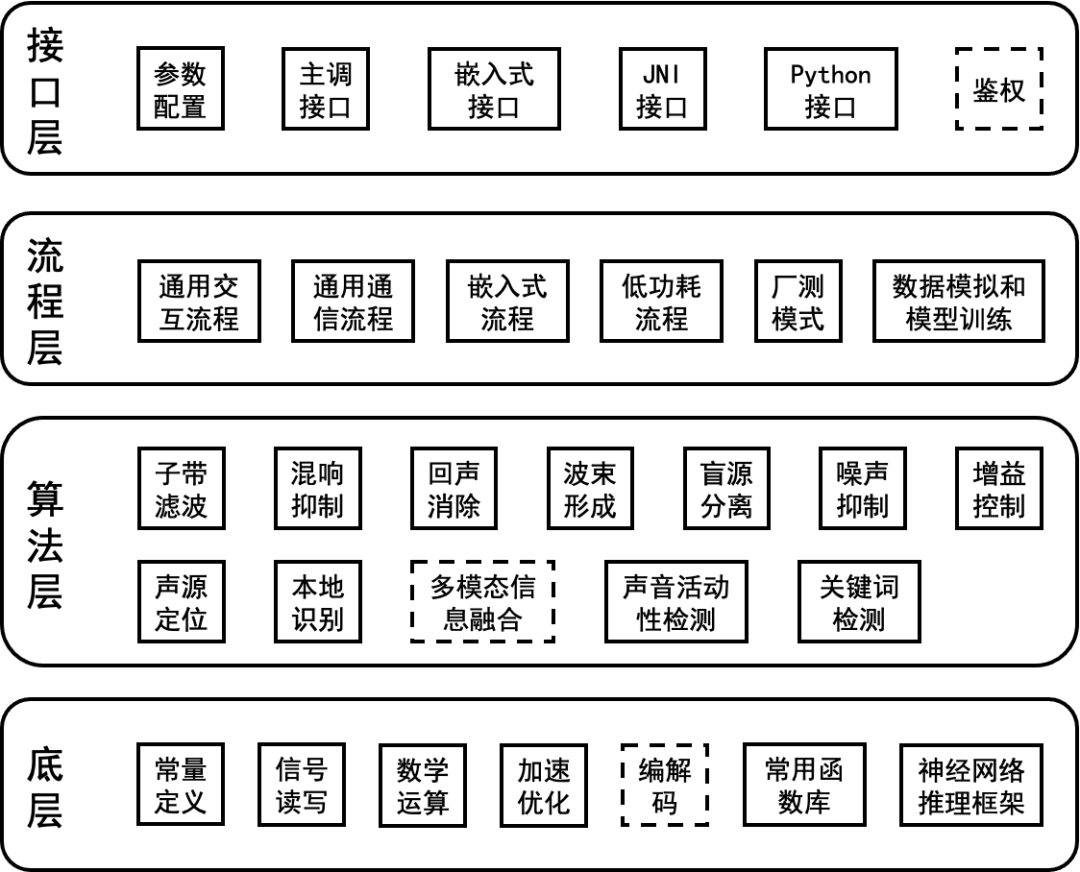
5.6 面向嵌入式低资源的信号处理与神经网络极致加速
开源微服务最佳实践
点击阅读原文查看详情。
登录查看更多
相关内容

相关VIP内容
相关资讯
相关论文