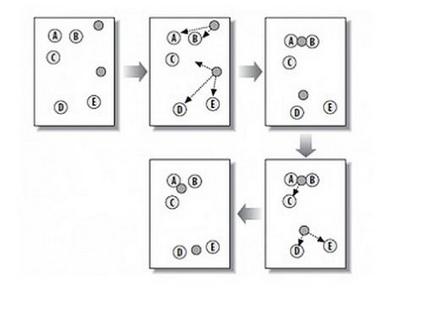
请说说Kmeans的优化?


今日面试题
请说说Kmeans的优化
解析一
k-means:在大数据的条件下,会耗费大量的时间和内存。
优化k-means的建议:
1、减少聚类的数目K。因为,每个样本都要跟类中心计算距离。
2、减少样本的特征维度。比如说,通过PCA等进行降维。
3、考察其他的聚类算法,通过选取toy数据,去测试不同聚类算法的性能。
4、hadoop集群,K-means算法是很容易进行并行计算的。
解析二
一、k-means算法简介
k-means是用来解决著名的聚类问题的最简单的非监督学习算法之一。
该过程遵循一个简易的方式,将一组数据划分为预先设定好的k个簇。其主要思想是为每个簇定义一个质心。设置这些质心需要一些技巧,因为不同的位置会产生不同的聚类结果。因此,较好的选择是使它们互相之间尽可能远。
接下来将数据中的每个点归类为距它最近的质心,距离的计算可以是欧式距离、曼哈顿距离、切比雪夫距离等。如果所有的数据点都归类完毕,那么第一步就结束了,早期的聚合过程也相应完成。
此时,我们根据上一步所产生的结果重新计算k个质心作为各个簇的质心。一旦获得k个新的质心,我们需要重新将数据集中的点与距它最近的新质心进行绑定。一个循环就此产生。作为循环的结果,我们发现k个质心逐步改变它们的位置,直至位置不再发生变化为止。
k-means算法是数值的、非监督的、非确定的、迭代的。
二、k-means算法流程
1、从所有的观测实例中随机取出k个观测点,作为聚类的中心点;然后遍历奇遇的观测点找到各自距离最近的聚类中心点,并将其加入该聚类中。这样,我们便有了一个初始的聚类结果,这是一次迭代过程。
2、每个聚类中心都至少有一个观测实例,这样,我们便可以求出每个聚类的中心点,作为新的聚类中心(该聚类中所有实例的均值),然后再遍历其他所有的观测点,找到距离其最近的中心点,并加入到该聚类中。
3、如此重复步骤2,直到前后两次迭代得到的聚类中心点不再发生变化为止。
该算法旨在最小化一个目标函数——误差平方函数(所有的观测点与其中心点的距离之和)。
三、k-means算法的优、缺点
1、优点:
①简单、高效、易于理解
②聚类效果好
2、缺点:
①算法可能找到局部最优的聚类,而不是全局最优的聚类。使用改进的二分k-means算法。
二分k-means算法:首先将整个数据集看成一个簇,然后进行一次k-means(k=2)算法将该簇一分为二,并计算每个簇的误差平方和,选择平方和最大的簇迭代上述过程再次一分为二,直至簇数达到用户指定的k为止,此时可以达到的全局最优。
②算法的结果非常依赖于初始随机选择的聚类中心的位置,可以通过多次执行该算法来减少初始中心敏感的影响。
方法1:选择彼此距离尽可能远的k个点作为初始簇中心。
方法2:先使用canopy算法进行初始聚类,得到k个canopy中心,以此或距离每个canopy中心最近的点作为初始簇中心。
Canopy算法:首先给定两个距离T1和T2,T1>T2。从数据集中随机有放回地选择一个点作为一个canopy中心,对于剩余数据集中的每个点计算其与每个canopy中心的距离,若距离小于T1,则将该点加入该canopy中;若距离小于T2,则将其加入该canopy的同时,从数据集中删除该点,迭代上述过程,直至数据集为空为止。
canopy算法会得到若干个canopy,可以认为每个canopy都是一个簇,只是数据集中的点可能同时属于多个不同的canopy,可以先用canopy算法进行粗聚类,得到k值和k个初始簇中心后再使用k-means算法进行细聚类。
③聚类结果对k值的依赖性比较大。目前并没有一个通用的理论来确定这个k值。一个简单常用的方法是:
从一个起始值开始到一个最大值,每一个值运行k-means算法聚类,通过一个评价函数计算出最好的一次聚类结果,这个k就是最优的k。
k-means算法的k值自适应优化算法:首先给定一个较大的k值,进行一次k-means算法得到k个簇中心,然后计算每两个簇中心之间的距离,合并簇中心距离最近的两个簇,并将k值减1,迭代上述过程,直至簇类结果(整个数据集的误差平方和)不变或者变化小于某个阈值或者达到指定迭代次数为止。
④可能发生距离聚类中心最近的样本集为空的情况,因此这个聚类中心不变无法得到更新。
⑤对离群点和孤立点敏感。通过LOF(局部离群因子)检测算法对数据集进行预处理,去除离群点后再进行聚类。
⑥性能问题。原始的k-means算法,每一次迭代都要计算每一个观测点与所有聚类中心的距离,当观测点的数目很多时,算法的性能并不理想。时间复杂度为O(nkl),l为迭代次数,n为数据集容量。为了解决这一问题,我们可以使用kd树以及ball 树(数据结构)来提高k-means算法的效率。
四、k-means算法的优化
(一)kd tree
kd树是一种对k维空间中的实例点进行存储一遍对其进行快速检索的树形树形结构。kd树是一种二叉树,表示对k维空间的一种划分。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间进行划分,构成一系列的k维超巨型区域。kd树的每个节点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
说明:
△ 选择切分轴(即特征)的方法:坐标轴的维度=节点的深度(mod k)+1
△ 选择切分点的方法:观测点在选定坐标轴上的中位数。(这样会使建立的树非常的平衡)
△ 算法结束的条件:每个区域只包含两个观测点存在时划分结束。
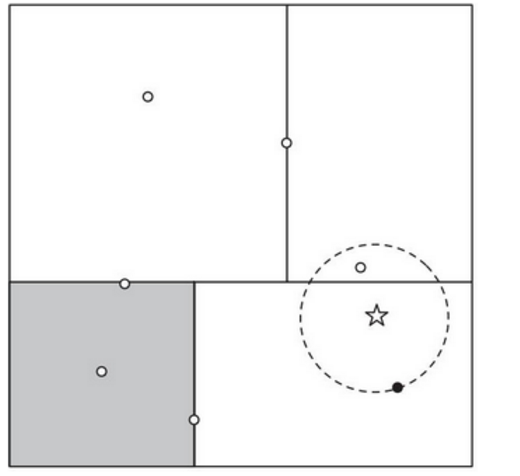
kd树的搜索(给定一个目标点,搜索其最近邻):首先找到包含目标点的叶节点;然后从该叶节点出发,依次退回到父节点;不断查找与目标节点最邻近的节点,当确定不可能存在更近的节点为止,这样的搜索就被限制在空间的局部区域上,效率大大提高。
kd树的优点:可以递增更新。
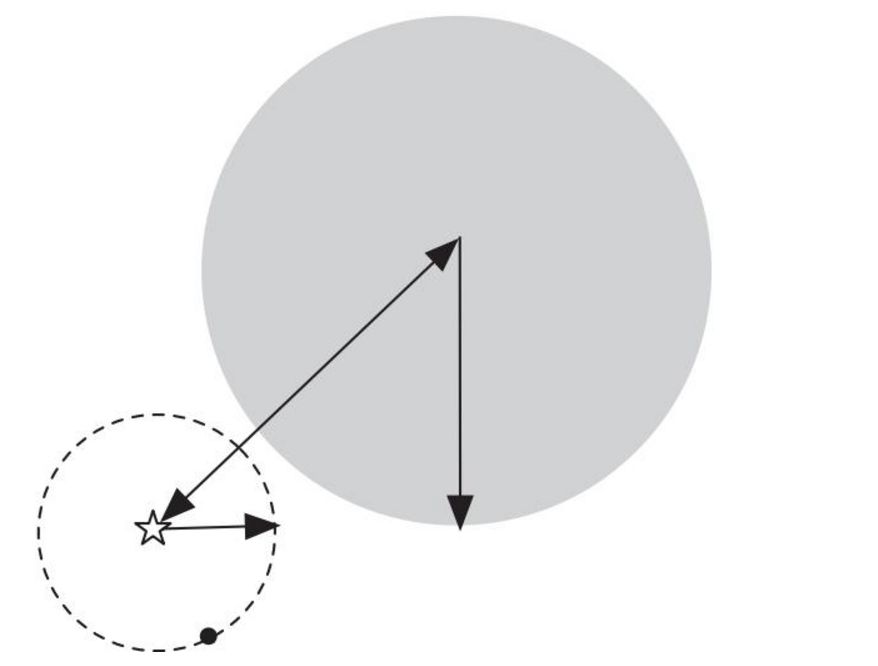
kd树的缺点:矩形并不是用到这里最好的方式。偏斜的数据集会造成我们想要保持树的平衡与保持区域的正方形特性的冲突。另外,矩形甚至是正方形并不是用在这里最完美的形状,由于它的角。如果图中的圆再大一些,即黑点距离目标点点再远一些,圆就会与左上角的矩形相交,需要多检查一个区域的点,而且那个区域是当前区域双亲结点的兄弟结点的子结点。为了解决这一问题,我们引入了ball tree。
(二)ball tree
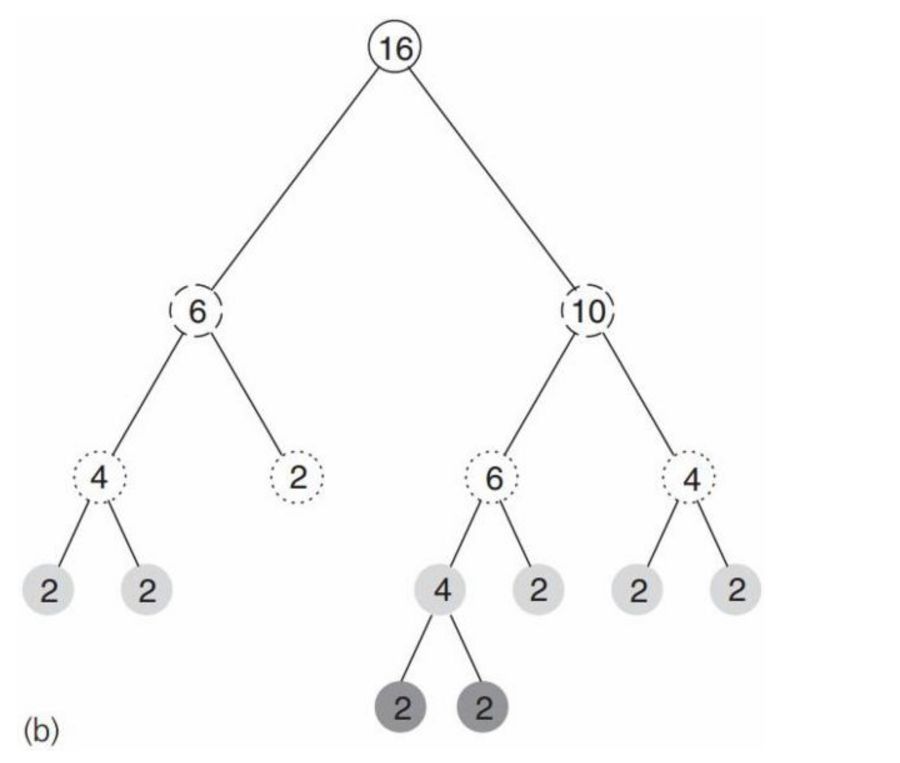
ball tree在划分的时候使用的是超球面而不是超矩形,使用球面可能会造成球面间的重叠,但是却没有关系。图2所示就是一个2维平面包含了16个观测实例的图,图3所示是其对应的ball tree,其中节点中的数字表示包含的观测点数。
树中的每个结点对应一个圆,结点的数字表示该区域保含的观测点数,但不一定就是图中该区域囊括的点数,因为有重叠的情况,并且一个观测点只能属于一个区域。实际的 ball tree 的结点保存圆心和半径。叶子结点保存它包含的观测点。
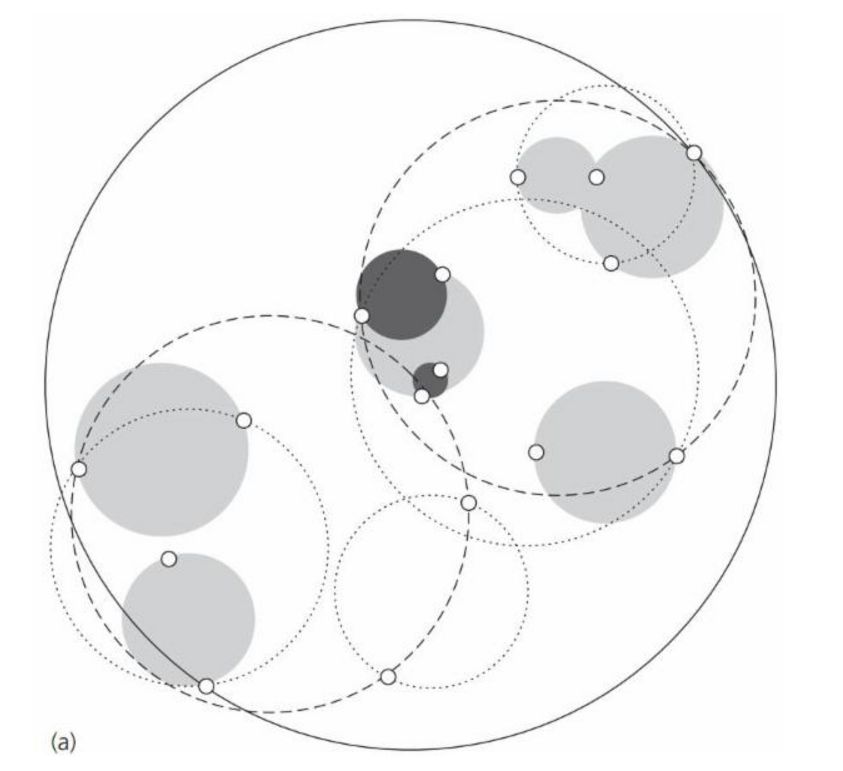
ball tree的搜索:先自上而下找到包含 target 的叶子结点,从此结点中找到离它最近的 观测点。这个距离就是最近邻的距离的上界。检查它的兄弟结点中是否包含比这个上界更小的观测点。方法是:如果目标点距离兄弟结点的圆心的距离大于这个圆的圆心加上前面的上界的值,则这个兄弟结点不可能包含所要的观测点(如图4)。否则,检查这个兄弟结点是否包含符合条件的观测点。
更多可以参见此文
从K近邻算法、距离度量谈到KD树、SIFT+BBF算法:https://blog.csdn.net/v_july_v/article/details/8203674
END

今日学习推荐
【机器学习集训营第八期】
火热报名中
2019年5月6日开课
前140人特惠价:15199
报名加送18VIP[包2018全年在线课程和全年GPU]
且两人及两人以上组团还能各减500元
有意的亲们抓紧时间喽
咨询/报名/组团可添加微信客服
julyedukefu_02
扫描下方二维码
免费试听
☟

长按识别二维码


扫描下方二维码 关注:七月在线实验室
后台回复:100 免费领取【机器学习面试100题】
后台回复:干货 免费领取【全体系人工智能学习资料】
后台回复: 领资料 【NLP工程师必备干货资料】