开源!腾讯发布超大预训练系统派大星

10月29日,腾讯微信AI团队联合Tencent NLP Oteam在GitHub 上发布了开源项「PatrickStar」,用来解决如GPT、BERT等超大模型训练时产生的GPU内存墙问题,测试结果显示软件获得了超DeepSpeed的性能表现。

以BERT、GPT为代表的预训练模型(PTM)的出现是自然语言处理(NLP)领域的里程碑事件。NLP正进入预训练时代。PTM 使用一个堆叠了多个Transformer 结构神经网络在大量文本上预训练通用语言特征表示,然后在微调后将学到的知识转移到不同的下游任务。使用大量来自互联网的文本数据,PTM 可以捕获自然语言的细微特征,并在下游任务上获得非常惊艳的表现效果。因此, AI 社区的共识是采用 PTM 作为特定 NLP 任务的主干,而不是在与任务相关的数据集上从头开始训练模型。
PTM 的力量源泉是它拥有的数以亿计的参数规模,这对运行它的计算和内存资源都提出了巨大的要求。因此,PTM训练仍是一小部分人的游戏。所有发表百亿级模型训练成果的团队,所采用的的设备都是如DGX型号的AI超级计算机。它的一个节点就配置了8张GPU,1.5TB内存,3.84TB SSDs,还使用NVLink作为高速通信网络。目前最大的PTM Megatron-Turing包含5300亿参数,其预训练过程就是在560个DGX A100节点的集群上完成的。这种配置在大多数工业界数据中心都是遥不可及的。
而且PTM预训练的过程是极其烧钱和有害环境的。比如,从头训练一次万亿级别的预训练模型要烧掉154万人民币,消耗的电能制释相当于数十辆小汽车从出厂到报废的碳排放总和。出于社会利益最大化考虑,预训练技术未来的产业形态,应该是中心化的。即使少部分财力雄厚的机构用超大规模集群承担预训练阶段的计算和环境开销,大多数从业人员在小规模、相对简陋的硬件上针对自身业务进行微调,这只需要相对少量的计算和碳排放。而后者的诉求却被当前的预训练软件严重忽略。
微信AI团队开源的派大星(PatrickStar)训练框架,用更革命性的内存管理设计,不仅可以进一步突破PTM模型规模的极限,还可以让PTM的预训练成果在微调节到普惠每位NLP社区的参与者。旧时王谢堂前燕,飞入寻常百姓家。实验结果表明,派大星在 8xV100 和 240GB CPU 内存节点上训练了一个 120 亿参数的 GPT 模型,是当前最佳方案DeepSpeed模型规模上限的 1.5 倍,并且展现了明显高于DeepSpeed的计算效率。即使在 700 美元的个人游戏电脑上,它也可以训练一个 7 亿参数的 GPT 模型。
派大星的原理
由于模型数据无法再容纳在单个 GPU 的内存中,因此最常用的数据并行技术不适用于 PTM。GPU硬件的存储规模上限像一堵墙一样限制住了PTM的可训练规模,因此从业人员通常称之为"GPU内存墙"现象。近两年来,通过利用并行训练在多个 GPU 内存之间分配模型数据,例ZeRO-DP、模型并行,流水线并行尝试使 PTM 大小突破内存墙。但是,这些技术都需要不断扩大GPU规模,而异构训练技术的出现成为破局者。它不仅可以显著提升单GPU训练模型的规模,而且可以和并行训练技术正交使用。
异构训练通过在 CPU 和 GPU 中容纳模型数据并仅在必要时将数据移动需要计算设备上。其他方案如数据并行、模型并行、流水线并行都在异构训练基础上进一步扩展GPU规模。PTM 训练期间必须管理的两种类型的训练数据:模型数据由参数、梯度和优化器状态组成,其规模与模型结构定义相关;非模型数据主要由算子生成的中间张量组成。非模型数据根据训练任务的配置动态变化,例如批量大小。模型数据和非模型数据相互竞争 GPU 内存。
然而,目前最佳的异构训练方案DeepSpeed的Zero-Offload/Infinity仍存在很大优化空间。在不考虑非模型数据的情况下,DeepSpeed在CPU和GPU内存之间静态划分模型数据,并且它们的内存布局对于不同的训练配置是恒定的。这种静态分区策略会导致几个问题。
派大星以细粒度的方式管理模型数据,从而更有效地使用异构内存空间。派大星将存储模型数据的张量组织成块(Chunk),即相同大小的连续内存块。在训练期间,块在异构内存空间中的分布根据所包含的张量状态动态改变。通过重用不共存的块,派大星可以比SOTA 解决方案进一步降低模型数据的内存占用。派大星使用一次预热迭代来收集运行时GPU 内存的统计数据。基于收集到的统计数据,推导出高效的块驱逐策略和设备感知算子放置策略。这些优化可以减少 CPU-GPU 数据移动量,使系统保持很高的计算访存比例。最后,使用零冗余优化器(ZeroReduencyOptimizer),通过块的集合GPU通信,派大星的内存管理思想可以与数据并行有效地结合在一起。
派大星的效果
腾讯微信团队联合TencentNLP Oteam选择从头开始搭建了派大星的代码,而非对现有方案如DeepSpeed进行魔改。派大星框架是简单易用的,并可以其他并行方案兼容。比如,开发者可以使用几行代码端到端的加速PyTorch的训练过程。
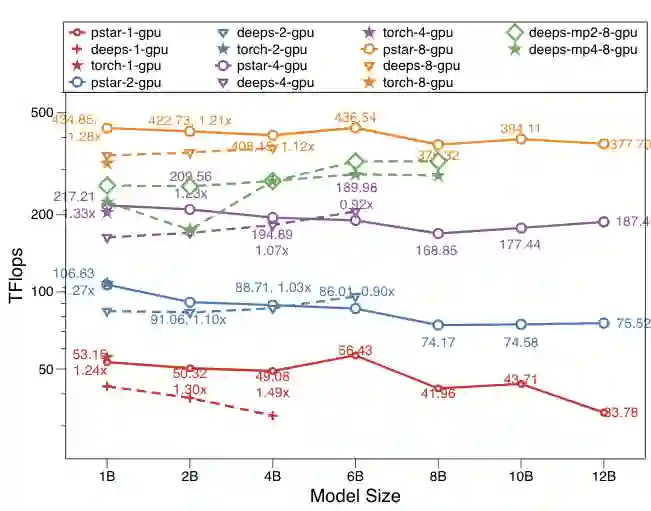
上图展示了DeepSpeed stage3,PyTorch系统在 1、2、4、8 个 GPU 上的性能。y 轴通过对数方式重新缩放。这些点代表在一个 GPU 上使用 4、8、16、32 和 64 批大小测试的最佳结果。圆点周围的值表示 派大星 在 Tflops 中的吞吐量及其对 DeepSpeed 的加速。deeps 是 DeepSpeed-DP,deeps-mpX 是 DeepSpeed使用X路的模型并行结果。模型的计量单位是B表示十亿Billon。
PyTorch 仅适用于 1B 模型大小的情况。派大星 在 8 个 GPU 上比 PyTorch 快 1.37 倍,在 1、2、4 个 GPU 情况下与 PyTorch 相似。使用相同的零Zero-DP 策略,派大星 在大多数情况下(14 个中有 12 个)优于 DeepSpeed-DP,并且是仅使用 DP 训练 8B 和 12B 之间模型大小的唯一解决方案。改进很明显(0.90x-1.49x),特别是对于小模型。在增加模型大小时,派大星不会显着降低计算效率。此外,派大星在增加 GPU 数量时显示出超线性可扩展性。
我们还将 PatrickStar 与模型并行解决方案进行了比较。上图还比较了 DeepSpeed 在 8 个 GPU 卡上使用 2路模型并行和 4路模型并行的性能。PatrickStar 在所有测试用例上实现了最大的模型规模120亿,以及最佳的性能效率。在模型并行的帮助下,DeepSpeed 将模型规模扩展到了 80亿。但是,MP引入了更多的通信开销;性能明显低于PatrickStar和 DeepSpeed-DP。
微信团队已经将派大星用于搜一搜、微信对话开放平台、小微智能音响等业务的研发工作中,显著降低了GPU卡使用数量,提升了机器的利用率。
参考链接
代码开源地址:https://github.com/Tencent/PatrickStar
论文预印本地址:PatrickStar: Parallel Training of Pre-trained Models via Chunk-based Memory Management
https://arxiv.org/abs/2108.05818
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。