在本文中,来自复旦大学的计算机博士生介绍了一些关于大规模预训练语言模型落地的思考。
在 BERT 之后,人们看到了大规模预训练的潜力,尝试了不同的预训练任务、模型架构、训练策略等等,在做这些探索之外,一个更加直接也通常更加有效的方向就是继续增大数据量和模型容量来向上探测这一模式的上界。
超大规模语言模型印象里大概从 GPT-3 开始,国内外诸多大厂都开始了大规模预训练的军备竞赛,Google 的 Switch-Transformer,国内智源的 CPM,百度的 ERNIE 3.0,华为的盘古,阿里的 PLUG,浪潮的源 1.0 等等。与此同时,相信也有很多人开始思考,花了几个亿训练的大模型该怎么用,难道就听个响吗?
在语言模型还不这么大的时候,一般是这么玩的:0. 下载某个开源的预训练模型或自研预训练模型,1. 收集特定任务的标注数据,2. Fine-tune 预训练语言模型,3. 上线推理。这种玩法我们叫小模型的玩法。
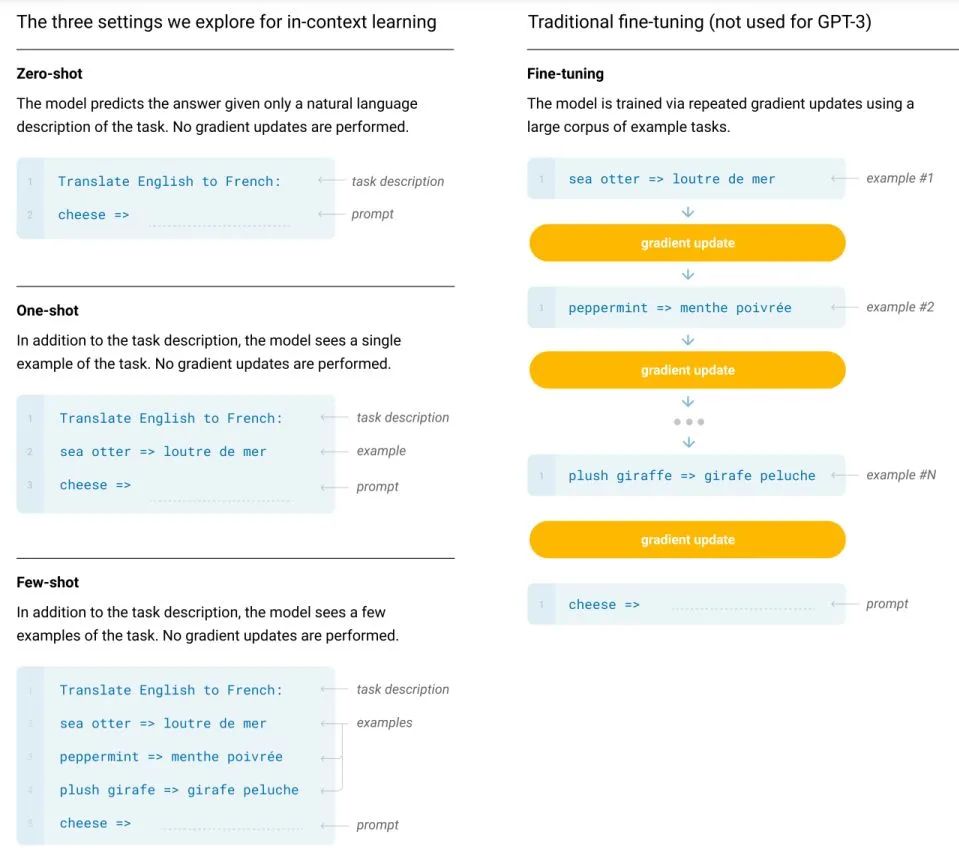
但大模型的预训练成本和 Fine-tuning 成本都是比较昂贵的,并且现在很多大模型出于成本和商业考虑都不再开源参数,因此大模型得有大模型的玩法。作为大模型的开路先锋,GPT-3 在他们的论文里给出的玩法就是 in-context learning. 如下图所示,不需要进行反向传播,仅需要把少量标注样本放在输入文本的上下文中即可诱导 GPT-3 输出答案。
GPT-3 in-context learning
这一玩法在当时是相当惊艳的,大家被 GPT-3 的这种玩法以及大规模预训练带来的 “质变” 感到震惊的同时,OpenAI 也开始了对大模型商业落地的尝试,开始开放 GPT-3 的推理 API 给开发者,出现了不少有趣的 APP,下面是其中一个例子,更多的 GPT-3 Demo 可以参见:300+ GPT-3 Examples, Demos, Apps, Showcase, and NLP Use-cases | GPT-3 Demo.(https://gpt3demo.com/)
![]()
类似的,悟道 2.0 也开展了 AI 创新应用大赛来鼓励基于大模型 API 开发好玩的 APP:https://www.biendata.xyz/wudao/.
而这一玩法后来也被发展成为如今大火的 prompt-based learning,即我们可以将下游任务转化为(M)LM 任务来直接用预训练语言模型解决,倘若模型规模越大从(M)LM 迁移到下游任务就越容易,那我们就可以用一个大规模通用语言模型来解决各种下游任务了。
由此来看,Prompt-based learning 起初的想法是很好的,但后来发展成为魔改输入输出后的加强版 fine-tuning,配以 MLM head 更好的初始化主攻小样本性能个人以为偏离了其初心。但后来发展又与包括 Adapter 在内的 parameter-efficient tuning 的工作类似,仅 fine-tune 连续的 prompt 而保持语言模型参数不变,能够做到 mixed-task inference,我觉得一定程度上又回归了原来的目标,即通用大模型的高效部署。然而,所有 in-context learning 之后的发展都需要梯度反向传播,这至少损失了 in-context learning 一半的魅力。试想,未来大厂会雇佣一大批调参师傅来对用户上传的训练数据进行 fine-tune 或者 prompt-tuning,甚至进行 template 和 verbalizer 的搜索?用户越多需要的调参师傅也越多,这不能规模化。
关于大模型的落地姿势,除了 OpenAI 之外,国内也有类似的看法,比如智源的张宏江博士就表示:“未来,大模型会形成类似电网的智能基础平台,像发电厂一样为全社会源源不断地供应‘智力源’”。这种把大模型作为一个在线的服务的模式我们称之为 Language-Model-as-a-Service (LMaaS).
可以看到,大模型的玩法更贴近个人用户和小 B 开发者,通过调用大厂开放的 API,就可以使用少量标注数据得到还不错的效果(这里指 in-context learning)。相比于之前小模型的玩法,LMaaS 当然要能够降低某一个或几个环节的成本才能够推行。我们粗略地从这几个方面去对比一下本地训练小模型的玩法和 LMaaS 的玩法:
预训练模型:小模型玩法可以是免费的(直接用开源预训练模型),而 LMaaS 需要支付一部分调用 API 的费用
数据标注:小模型需要的标注数据通常更多,因而标注成本更高
实际性能:对于复杂任务或对于有计算资源的用户,本地训练小模型通常能够超过使用 prompt 来调用大模型 API 的效果;对于简单任务或计算资源有限的用户,直接使用大模型 API 可能效果更好
经过粗略地对比我们发现有调用大模型推理 API 需求的用户主要是标注预算不高、处理简单任务、计算资源有限的个人用户或者小 B 开发者。那么,假设未来大规模预训练模型就是这样一种玩法,怎么使其更好地为更多的用户提供服务呢?或者说,怎么利用通用语言模型的推理 API 做好下游任务?再或者,怎么设计一个推理 API 能够惠及更多的下游任务?更进一步,大厂是否能够发布推理 API 的同时也发布一辅助使用工具?这些问题构成了我们最近工作的主要动机。
黑箱优化:仅调用模型推理 API 完成常见语言理解任务
接下来我们提供一个适用于上述 LMaaS 场景的方案:Black-Box Tuning.
我们的文章标题叫 Black-Box Tuning for Language-Model-as-a-Service,又名 Forward is All You Need,又名 Make Zeroth Optimization Great Again,又名 Inference as Training
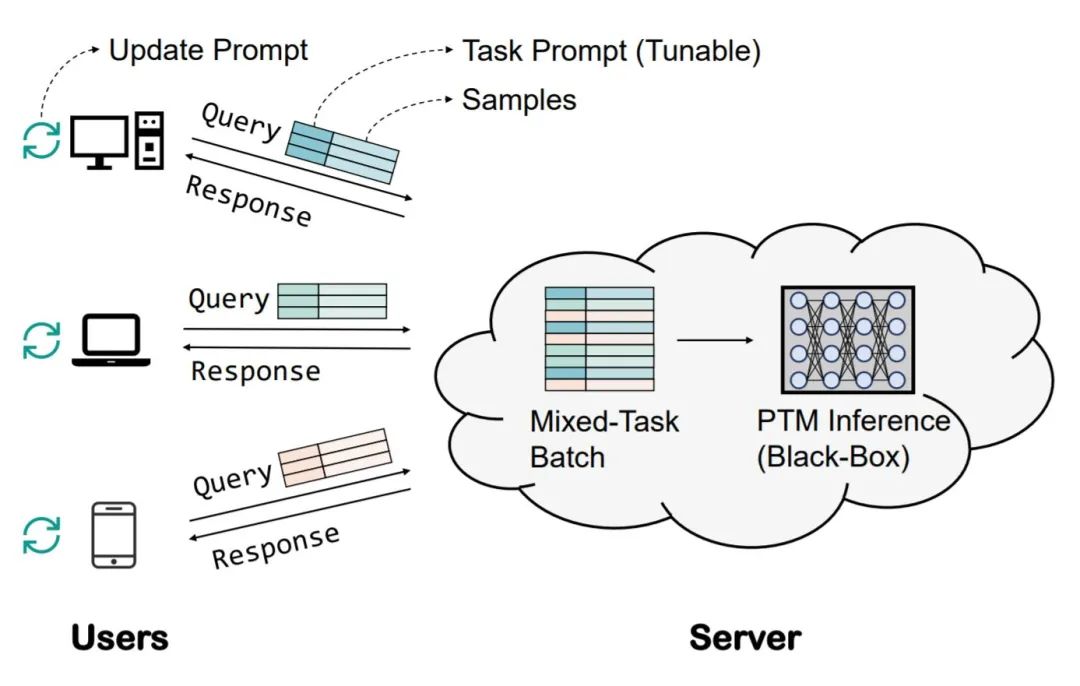
前面提到,LMaaS 是要把大模型当作发电厂,那自然不能给每家每户都派一个调电(调参)师傅过去,最好是每家每户能够自己把电器(任务)管理好,发电厂(大模型服务方)只需要确保供应电力(算力),这才是规模化的玩法。
为了做到大模型的高效部署,我们可以诉诸于 parameter-efficient tuning,即只 fine-tune 少量参数,如 adapter 和 prompt tuning,但仍然需要调参师傅在服务端帮你 tuning。自然地,我们想到可以让用户根据推理 API 的返回结果自己优化 adapter 或 prompt,比如用无梯度优化(Derivative-Free Optimization)去优化这些 “少量” 的参数。基于这个朴素的想法,我们有了下面的一张愿景图:
但无梯度方法本质上还是基于搜索的,即使对于 parameter-efficient tuning 也还是会有上万的参数量需要优化(例如 prompt tuning 优化 20 个 token,每个 token 1024 维,总共是 20480 维),这让非梯度优化很难做。
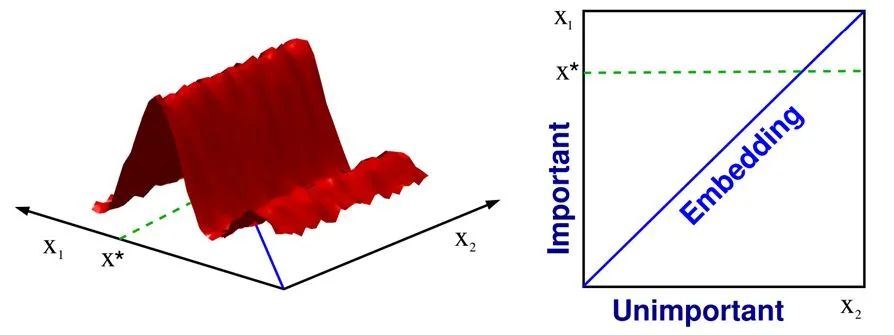
在非梯度优化中,如果要优化的目标函数原本维度很高,但只要本征维度很小,我们就可以使用非梯度优化方法来做,一种方法就是通过 random embedding. 例如在下图中,左边的目标函数是二维的,但其函数值实际上只跟一个参数( [x_1] )相关,那么我们就可以使用一个 random embedding 将要优化的参数映射到一低维子空间(如下图右边的 embedding 就是 [x_1=x_2] ),在这一子空间中进行优化便可以找到最优解 [x^*] .
幸运的是,最近的一些工作表明预训练模型参数越多,其本征维度反而越小。例如人们发现仅训练 RoBERTa-large 的 200 + 个参数,然后映射回原本参数空间就可以达到 fine-tuning 90% 的性能[1],这就使得非梯度优化方法变得可行了。
有意思的是,过去非梯度优化方法不用于神经网络的参数优化是因为其参数太多,而仅用于调节少数超参数,现在随着神经网络参数越来越多,梯度下降变得非常笨重,而非梯度优化方法反而正好可以拿来做。
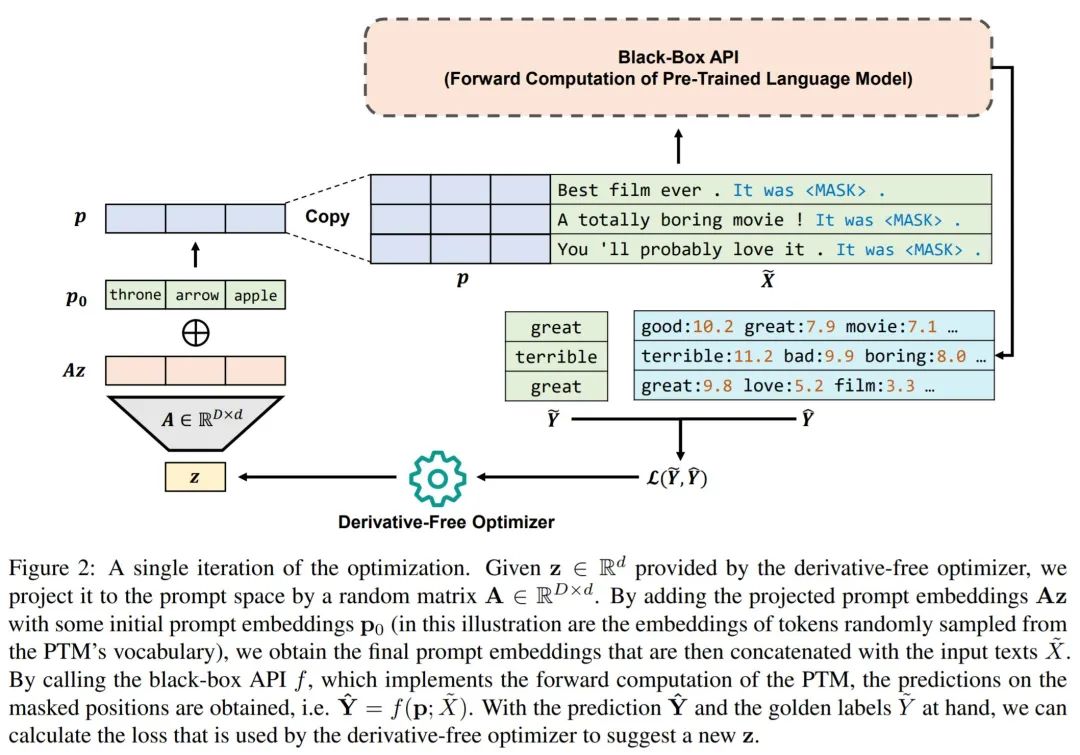
基于以上,我们大概可以得知,结合 parameter-efficient tuning 和基于 random embedding 的非梯度优化算法,就可以做到前文提到的使用推理 API 把下游任务做好(开除调参师傅)的愿景。下面我们给出了 black-box tuning 的一个具体实现,比较懒,请大家读 caption.
这样我们发现,大模型服务方仅需要执行模型推理(即提供算力),任务性能的优化由用户自己完成(即根据推理结果优化 prompt),这样就不需要调参师傅了。此外,prompt 的优化几乎是不耗费算力的,因此这一优化过程可以在任何终端设备进行,根本不需要 GPU,所有算力需求集中在大模型服务端。此外,这种优化方式还解藕了优化过程和模型前向传播的复杂度,原本的梯度下降中,反向传播的时间和内存占用与模型前向传播成正比,随着模型越来越大,优化也变得越来越昂贵;而 black-box tuning 的优化过程本身不耗费什么时间和内存,且复杂度仅依赖于本征维度 d 的大小,与前向传播的复杂度无关。
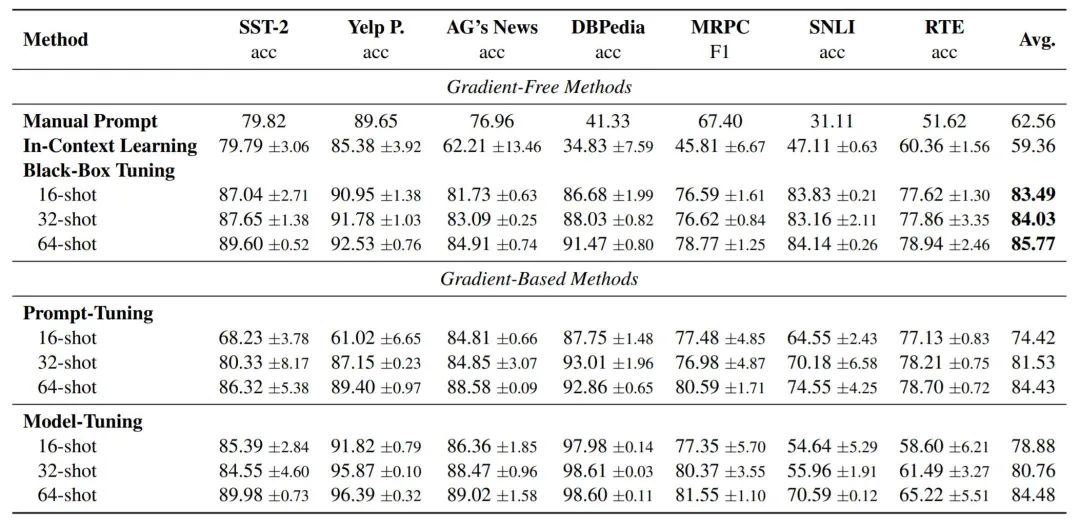
(说了这么多,效果还是最关键的,它得能 work,至少要比 manual prompt 和 in-context learning 好吧)于是,我们做了 true few-shot 的实验,他竟然不仅 work 了,还比基于梯度的 prompt-tuning 和 fine-tuning 还要 work,请看下图:
但既然这条路走通了,可以想到很多有意思的方向可以继续做,(出于本人毕业压力,这里还不能告诉你们,只能随便说几个)例如 inference as training:实际上我们的 black-box tuning 是可以和 fine-tuning 并存的,在 fine-tune 之后(调参师傅调完之后),你还可以一边推理 - 一边标注 - 一边继续优化你的 prompt,这样就不用再麻烦调参师傅了;再有一个就是可以做一个 Pre-Trained Optimizer for Pre-Trained Language Models,也就是前面说的几个问题里的“大厂是否能够发布推理 API 的同时也发布一辅助使用工具”。好了不能再说了,否则,我就成调参师傅了。
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning https://aclanthology.org/2021.acl-long.568.pdf
原文链接
:https://zhuanlan.zhihu.com/p/455915295
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com