【SIGIR2021】ScaleFreeCTR:超大规模Embedding推荐模型分布式训练系统

推荐系统广泛应用于在线服务,如搜索广告、新闻推荐和在线广告,提供个性化的预测和推荐来提高用户满意度和在线服务的收益。在推荐系统中,点击率(Click-Through-Rate,CTR)预测用于预测用户在特定上下文对不同商品点击的概率,直接影响到推荐系统的效果。近年来,由于深度学习技术在特征表示方面的良好性能,越来越多的深度点击率预测模型被提出和部署,如Google Play的Wide&Deep[3]、华为应用市场的DeepFM[1]和阿里巴巴的DIN[4]。主流的深度点击率预测模型由Embedding层和MLP层构成(如图1所示[5, 6]):Embedding层将推荐搜索数据中高维稀疏的id特征(商品id、用户id等)映射为低维稠密向量;MLP层捕捉特征之间的非线性组合关系以得到更为准确的点击率预测值。由于推荐数据十分高维,特征维度可达亿级甚至百亿级别,Embedding层参数量很容易达到百GB甚至TB。面对超大规模Embedding的推荐模型,需要在尽可能少的时间内使用海量数据训练推荐模型的海量参数,以保证模型的时效性和预测效果。因此,如何基于海量数据完成超大规模推荐模型的高效训练,对于推荐系统十分关键。
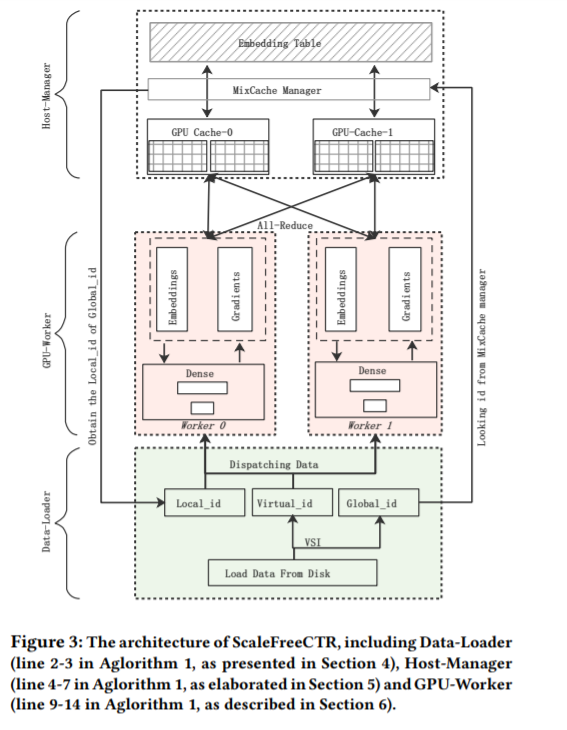
本文将介绍华为诺亚推荐搜索与AI系统工程联合团队最新发表在SIGIR2021上的研究成果:ScaleFreeCTR: MixCache-based Distributed Training System for CTR Models with Huge Embedding Table。ScaleFreeCTR针对超大规模Embedding的深度推荐模型,提出CPU-GPU协同训练系统,通过自研的MixCache缓存机制和高效的流水线设计,实现CPU-GPU数据传输延迟的降低,提升了并行效率。同等硬件下,训练性能超过HugeCTR的5倍,目前已在华为多个业务场景中应用,ScaleFreeCTR近期将在华为深度学习框架MindSpore进行开源。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SCTR” 就可以获取《【SIGIR2021】ScaleFreeCTR:超大规模Embedding推荐模型分布式训练系统》专知下载链接




