用AI实现隔墙“透视”,准确率达97%,这家中国公司研究入选CVPR
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
试想一下,自动驾驶汽车行驶到了拐弯处,即使激光雷达再强大,也无法探测到建筑物后的有什么事情发生,如果是突然有行人冲出来,后果不堪设想。
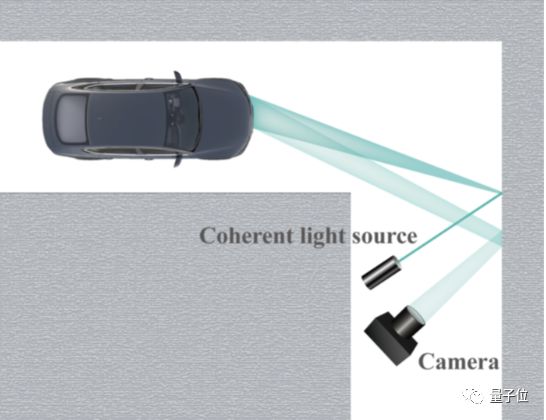
其实用激光结合强大的AI算法,可以帮你看到墙后究竟有没有人,甚至还能看出他的姿势。
最近,一家来自中国的AI创业公司合刃科技与华中科技大学、斯坦福大学等合作,尝试用墙壁散射的光去复原被遮挡数字,正确率最高能达到97%,整个过程不需要1秒,更适合用在需要实时处理的自动驾驶。
他们的论文《Direct Object Recognition Without Line-of-Sight Using Optical Coherence》已被CVPR 2019收录。
之前,量子位介绍过一种可以用墙面反射的复原屏幕内容的方法。而合刃科技提出的方法不需要复杂的图像重建过程,不仅能恢复简单的图像,甚至还能推测人体的姿势。
隔板猜物
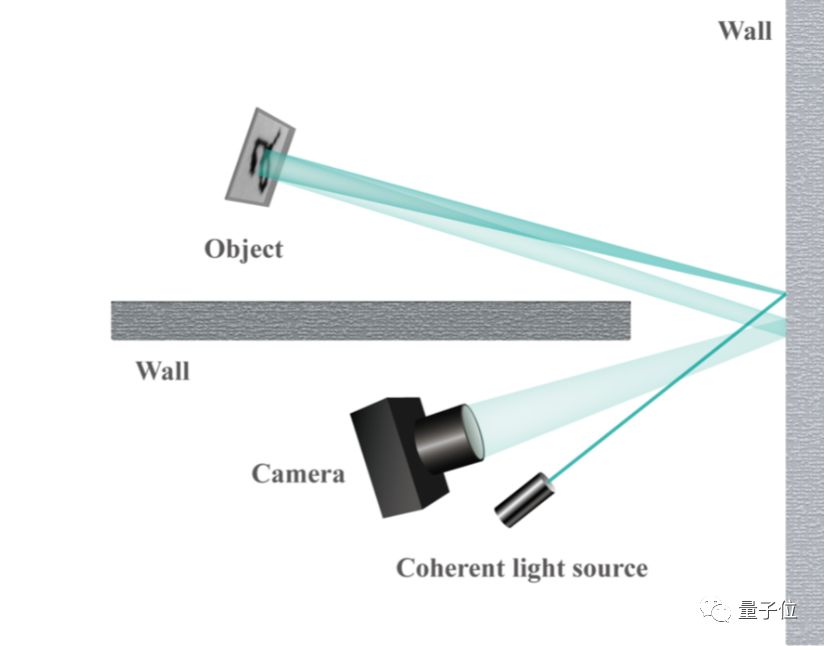
研究人员给算法出了道难题,让它从拍摄白墙上的画面,推测黑色挡板背后屏幕上的内容。由于被拍摄物体和相机之间有不透明的障碍物,因此相机只能采集到挡板上漫反射的光。

上面的布局太复杂,简化后的示意图如下:
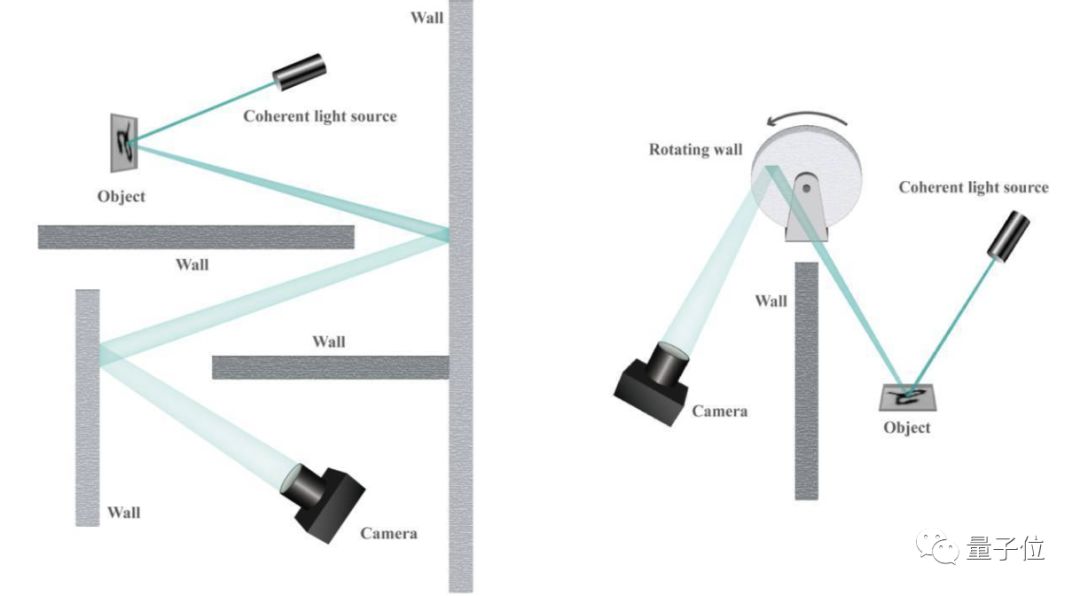
除了这种比较简单的情形,研究人员还给算法出了两道附加题:让激光来回反射绕过两堵墙,甚至还设计了一种“旋转的墙壁”。
由全息照片猜数字
激光与我们日常见到的日光、灯光不同,不仅能记录强度,还能记录相位信息,通俗地说就是能记录被拍物体的立体信息,与全息照相类似。
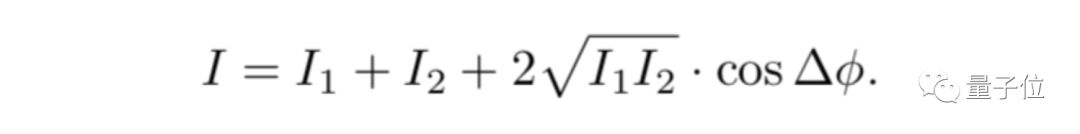
当携带MNIST数字信息的相干光经过挡板漫反射后,形成散斑图。虽然由散斑图复原物体有困难,但是可以用AI算法,对障碍物后面的数字变化进行实时识别。

仅仅能识别数字图像还不行,研究人员还尝试从散斑图找到中得到墙后面隐藏的人,已经他正处在什么姿势。

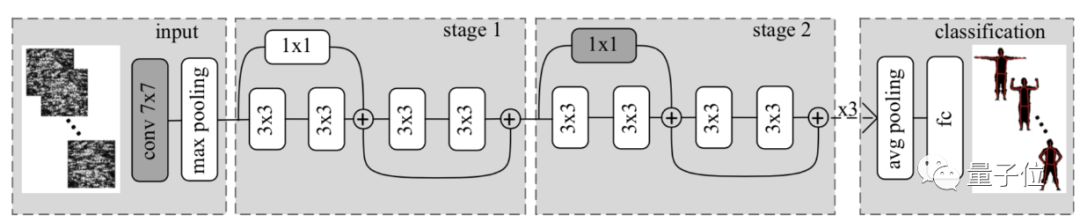
在处理图像时,AI算法用了两个网络:
1、SimpleNet,它用来对10个数字图像进行分类,包含4个卷积层,完全连接层中由1024个神经元。
由于全息图像的每个区域都包含被拍摄物体的全部信息,为了减小计算量,研究人员只选取照片中200×200的一小块区域,从拍摄的1万张照片中选取95%作为训练集,5%作为数据集。
2、ResNet-18,它用来对人体姿势进行分类。输入图像被裁剪至224×224。
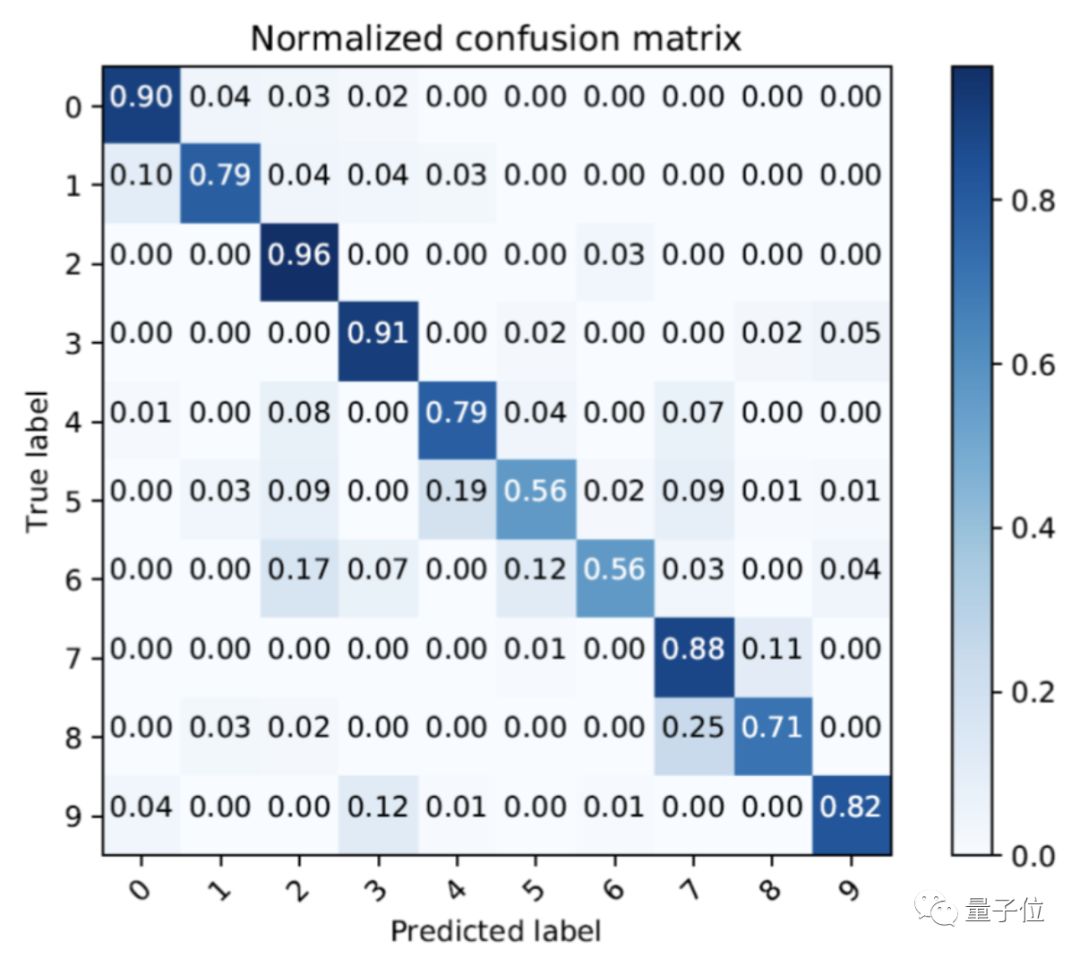
准确率最高97%
在识别MNIST手写数字的实验中,算法的平均识别准确率均在91%以上,最高可达97%。

通过深度学习的AI算法处理,研究人员对12个人不用的10种姿势进行识别,得到的平均识别准确率为78.18%。
论文链接:
https://arxiv.org/abs/1903.07705
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
订阅AI内参,获取AI行业资讯

加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !




