融合外部知识的常识问答

作者:哈工大SCIR 孙月晴
1.摘要
2.正文
2.1常识问答数据集
(1) CommonsenseQA

(2) CosmosQA
CosmosQA数据集包含35600个需要常识阅读理解的问题,大约94%的问题需要常识,这是所有需要理解段落的QA基准中所见比例最高的。其专注于解决需要跨越上下文、而不是定位指定片段的推理问题。其主要特点为:
-
上下文段落中的任何地方都没有明确提到正确的答案,因此需要通过常识推断在各行之间进行阅读 -
选择正确的答案需要阅读上下文段落

(3) PIQA
(4)SOCIAL IQA

(5) OpenBookQA

2.2外部知识库
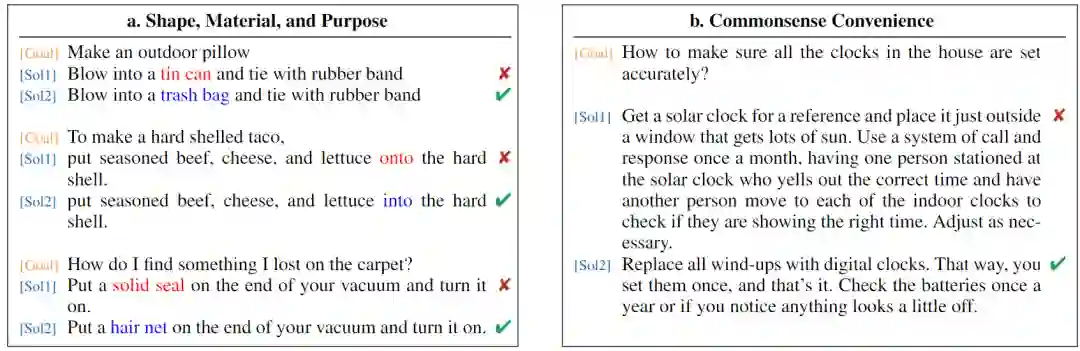
(1) ConceptNet
(2) ATOMIC
(3) GenericsKB

(4) Wikipedia
2.3融合外部知识的常识问答模型
(1)使用预训练融合常识知识
-
首先,从ConceptNet中挑选一些三元组:非英文去掉;调整RelateA和IsA关系三元组到正常比例,因为在ConceptNet中这两种关系占比较高;三元组中,至少有一个实体包含四个单词以上,或者两个实体之间的编辑距离少于4; -
然后基于每个三元组中的两个实体词去Wikipedia中搜索包含这两个词的句子;(align) -
在该句子中,使用[QW]遮掩两个实体中的一个,构成question,mask的词为标注答案;(mask) -
基于三元组中的mask之外的词去ConceptNet搜索,找4个包含这两个词的三元组作为干扰。如果大于4个,随机选4个,反之过滤掉;(select)

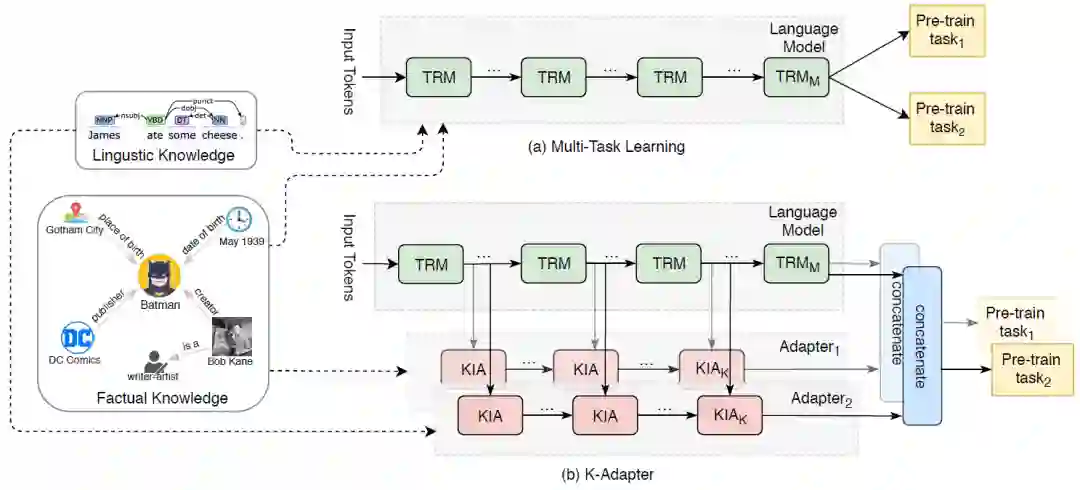
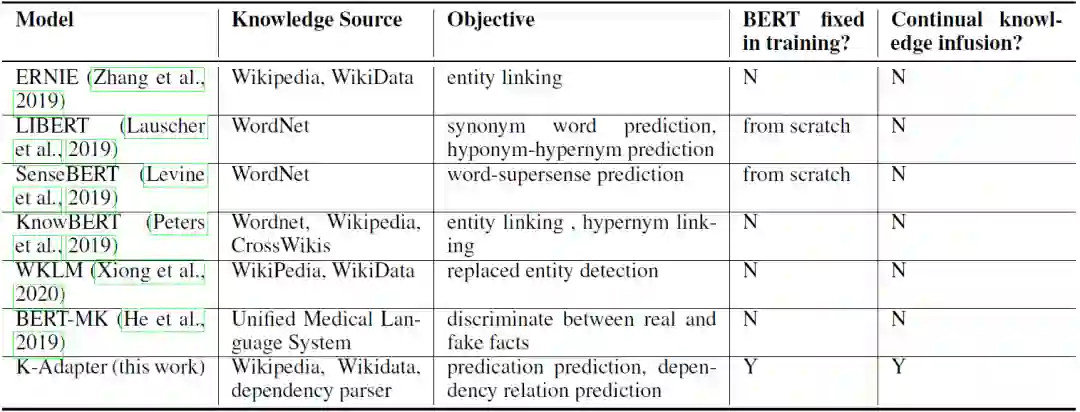
(2)使用关系网络融合常识知识
在自然语言处理QA任务设置中,RN也可以适应于多关系图编码,如下述公式所示,RN使用MLP编码知识图中所有一跳路径的三元组,然后池化三元组的编码得到关系路径的整体表示。
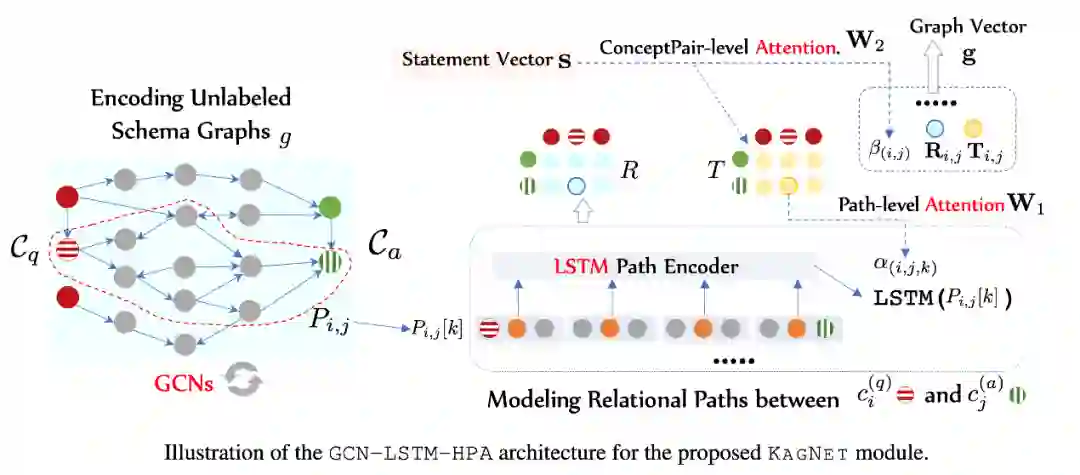
KagNet对RN进行了改进,可以看作知识增强的关系网络模块,使用LSTM编码从问题中的实体到答案中的实体的所有K跳的路径:

(3)使用图神经网络融合常识知识
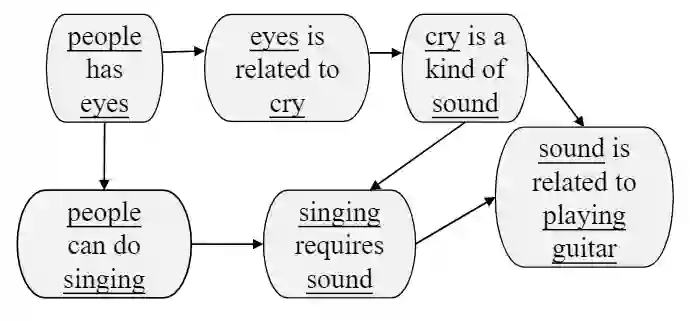
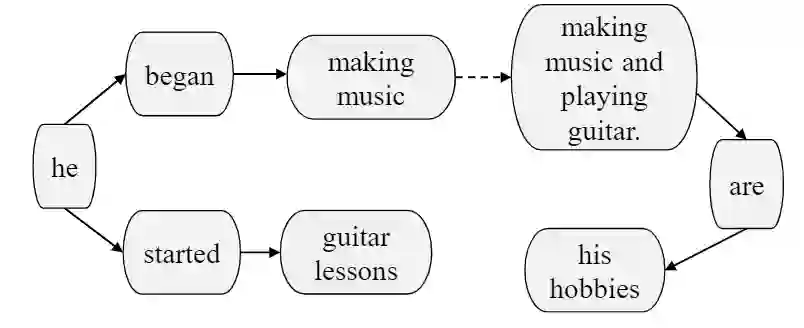
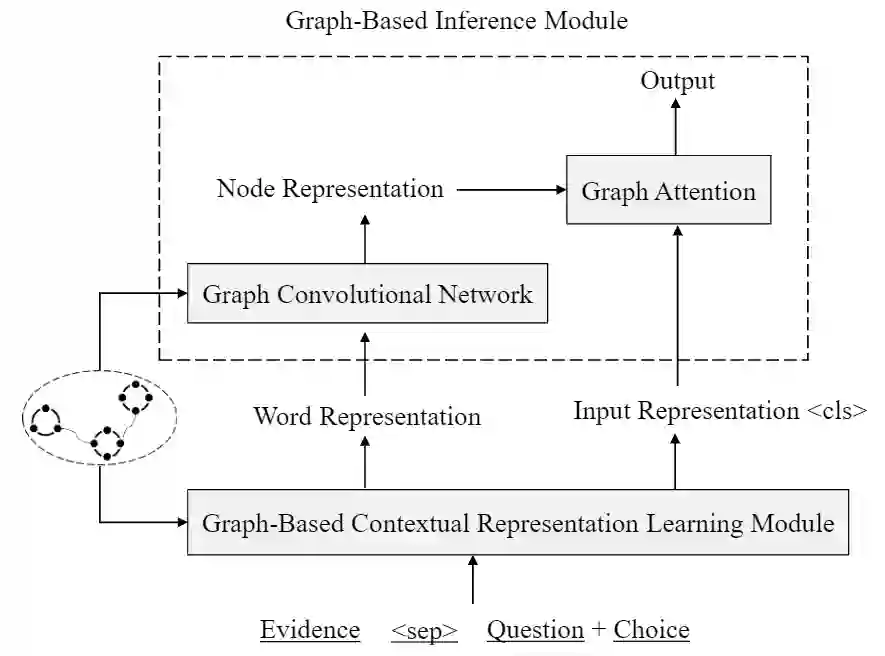
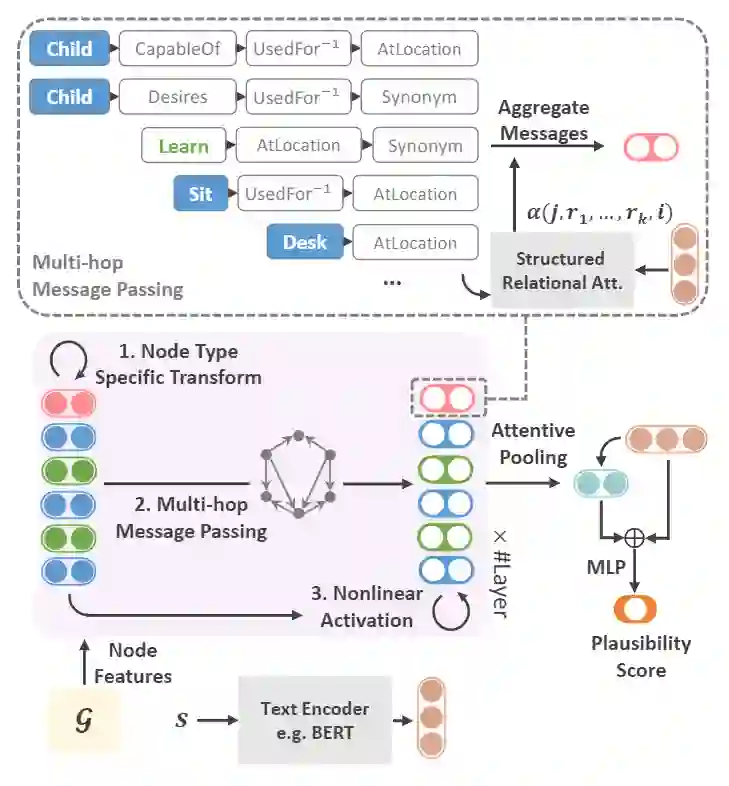
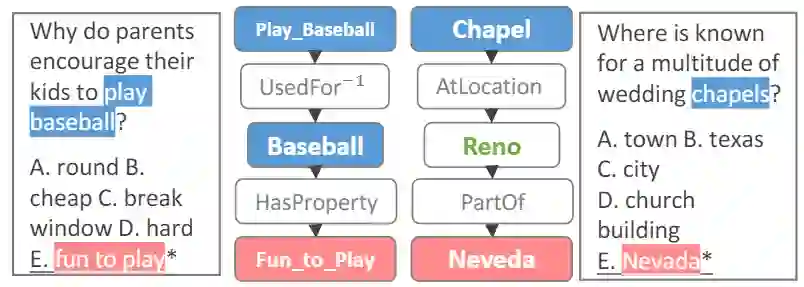
3.总结
参考资料
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Commonsenseqa: A question an-swering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the NorthAmerican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1(Long and Short Papers), pages 4149–4158.
[2]Lifu Huang, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. Cosmos qa: Machine reading compre-hension with contextual commonsense reasoning. InProceedings of the 2019 Conference on Empirical Methodsin Natural Language Processing and the 9th International Joint Conference on Natural Language Processing(EMNLP-IJCNLP), pages 2391–2401.
[3]Bisk, Y.;Zellers, R.; Le Bras, R.; Gao, J.; and Choi, Y. 2020.PIQA: Reasoning about Physical Commonsense in NaturalLanguage. InAAAI.
[4]Sap, M.; Rashkin, H.; Chen, D.; Le Bras, R.; and Choi, Y.2019c. Social IQA: Commonsense Reasoning about SocialInteractions. InProceedings of the 2019 Conference on Em-pirical Methods in Natural Language Processing and the 9thInternational Joint Conference on Natural Language Pro-cessing (EMNLP-IJCNLP), 4453–4463.
[5]Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity?a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methodsin Natural Language Processing, pages 2381–2391.
[6]Speer, R.; Chin, J.; and Havasi, C. 2017. Conceptnet 5.5: Anopen multilingual graph of general knowledge. In AAAI.
[7]Maarten Sap, Ronan Le Bras, Emily Allaway, ChandraBhagavatula, Nicholas Lourie, Hannah Rashkin, Bren-dan Roof, Noah A Smith, and Yejin Choi. Atomic: anatlas of machine commonsense for if-then reasoning. InAAAI, volume 33, pages 3027–3035, 2019.
[8]Sumithra Bhakthavatsalam, Chloe Anastasiades, and Peter Clark. 2020. Genericskb: A knowledge base of generic statements. arXiv preprintarXiv: 2005.00660.
[9]WikiData官网:https://www.wikidata.org/wiki/Wikidata:Main_Page
[10]Zhi-Xiu Ye, Qian Chen, Wen Wang, and Zhen-Hua Ling. Align, mask and select: A simple method for incorporating commonsense knowledge into language representation models. CoRR,abs/1908.06725, 2019. URL http://arxiv.org/abs/1908.06725.
[11]Ruize Wang, Duyu Tang, Nan Duan, Zhongyu Wei, Xuanjing Huang, Jianshu Ji, Guihong Cao, Daxin Jiang,and Ming Zhou. 2020b.K-adapter: Infusing knowledge into pre-trained models with adapters.CoRR,abs/2002.01808.
[12]Adam Santoro, David Raposo, David G Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia,and Timothy Lillicrap. A simple neural network module for relational reasoning. InAdvances in neuralinformation processing systems, pp. 4967–4976, 2017.
[13]Lin, B. Y.; Chen, X.; Chen, J.; and Ren, X. 2019. KagNet: Knowledge-Aware Graph Networks for Commonsense Rea-soning. In EMNLP/IJCNLP.
[14]Shangwen Lv, Daya Guo, Jingjing Xu, Duyu Tang, Nan Duan, Ming Gong, Linjun Shou, Daxin Jiang, GuihongCao, and Songlin Hu. 2019. Graph-based reasoning over heterogeneous external knowledge for commonsensequestion answering.In AAAI.
[15]Feng, Y.; Chen, X.; Lin, B. Y.; Wang, P.; Yan, J.; and Ren, X. 2020. Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering. In EMNLP.
[16]https://www.zhihu.com/question/312388163/answer/600712686
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


