
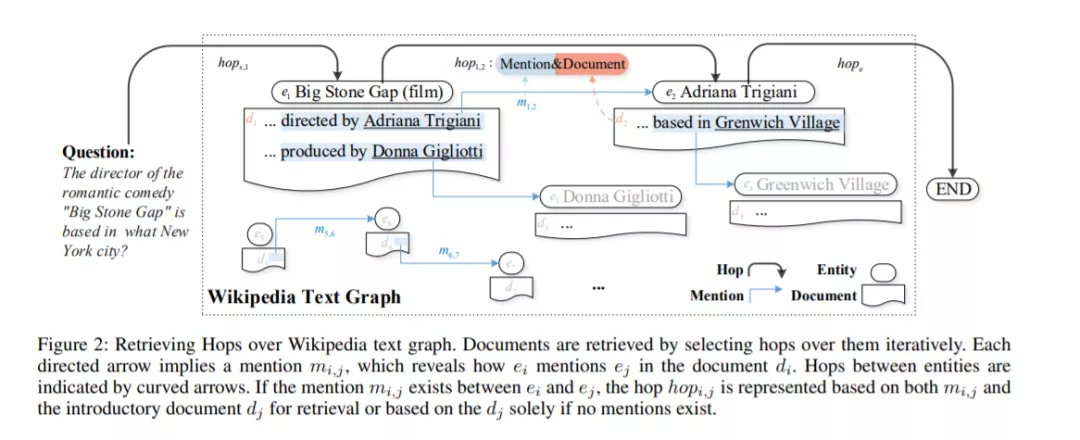
从大型文本语料库(如维基百科)中收集支持证据对开放域问答(QA)来说是一个巨大的挑战。特别是对于多跳开放域的QA,需要将分散的证据片段聚集在一起,以支持答案抽取。在本文中,我们提出了一种新的检索目标——hop,用于从维基百科中收集复杂问题回答中隐藏的推理证据。具体来说,本文将hop定义为超链接与相应的出站链接文档的组合。超链接被编码为提到嵌入,它对出站链接实体在文本上下文中如何被提及的结构化知识进行建模,而相应的出站链接文档被编码为表示其中非结构化知识的嵌入文档。因此,我们构建了hopretriver,它可以在Wikipedia上检索跳跃来回答复杂的问题。在HotpotQA数据集上的实验表明,hopretriver比以前发布的证据检索方法有更大的优势。此外,我们的方法还产生了证据收集过程的可量化解释。
https://www.zhuanzhi.ai/paper/ef7d860704608c5446360ad2a0d8cbce
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2021年3月2日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年3月2日