CVPR 2022 | 浙大&MSRA提出基于序列对比学习的长视频逐帧动作表示
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:FY.Wei | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/522600318

Frame-wise Action Representations for Long Videos via Sequence Contrastive Learning
单位:浙江大学CAG&CG实验室,微软亚洲研究院
论文:https://https://arxiv.org/abs/2203.14957
代码:https://github.com/minghchen/CARL_code
在过去几年中,基于深度学习的视频理解在视频分类任务上取得了巨大成功。I3D和SlowFast等网络通常将短视频片段(64帧,~3秒)作为输入,提取全局表征来预测动作类别。
但是这样的设定有两个主要的限制。第一,在一些应用中,我们需要每帧画面的表示来更精细地理解动作,而不只是一个全局动作表示。第二,现实世界中的大多数视频都具有较长的持续时间,因此我们需要对较长的上下文进行有效的建模。
为此,我们引入了长视频的逐帧动作表示学习任务。其有诸多应用,例如,我们可以执行细粒度的帧检索来搜索我们想要的确切帧。我们还可以执行阶段分类来识别复杂动作的每个阶段。此外,我们可以进行时间视频对齐来对齐描述相同过程的两个视频。其他一些研究领域也需要逐帧表示。例如,在机器人模仿学习中,模型需要对人类动作进行编码并指导机器人的动作。在手语翻译中,利用每一帧的表示来翻译手语。

然而,如果要标记每一帧以执行监督学习是很困难的,甚至是不可能的。为了减少对标记数据的依赖性,TCC、LAV和GTA等方法通过使用循环一致性损失或可微时间动态规划来进行弱监督学习。然而这些方法都依赖于视频层面的注释,并且需要用具有相同动作的成对视频进行训练。
本研究的目的是以自监督方式学习长视频中具有时空上下文信息的逐帧表征。受最新的对比表征学习方法SimCLR的启发,我们提出了一个新框架——对比动作表征学习(CARL)。我们假设在训练期间没有任何可用的标签,并且训练和测试集中的视频都很长(数百数千帧)。此外,我们不依赖具有相同动作的成对视频进行训练,从而能够以更低的成本扩大训练集规模。
图2中我们对CARL架构进行了概述。首先通过一系列时空数据增强为输入视频构建两个增强视图。此步骤称为数据预处理。然后,我们将两个增强视图输入到帧级视频编码器(FVE)中,以提取密集表征。遵循SimCLR,FVE附加了一个小型投影网络,它是一个两层的MLP,用于获得潜在嵌入。由于时间上相邻的帧高度相关,我们假设两个视图之间的相似性分布遵循先验高斯分布。基于此,我们提出了一种新的序列对比损失(SCL)来优化嵌入空间中的逐帧表征。
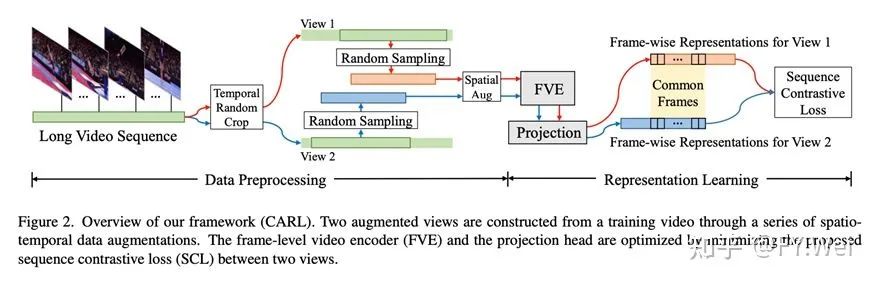
首先,我们引入了一系列时间-空间数据增强来生成两个视图。在时间维度上,我们先对视频进行时间随机裁剪,以生成两个不同长度的随机裁剪片段。在裁剪期间,我们还保证两个片段之间存在一定比例的重叠。然后我们从两个片段中随机采样 T 帧来生成两个视图。对于小于T帧的视频,在裁减之前会对空帧进行padding。最后,我们分别在两个视图上应用几种时间一致的空间数据增强,例如随机调整大小和裁剪、水平翻转、随机颜色失真和随机高斯模糊。
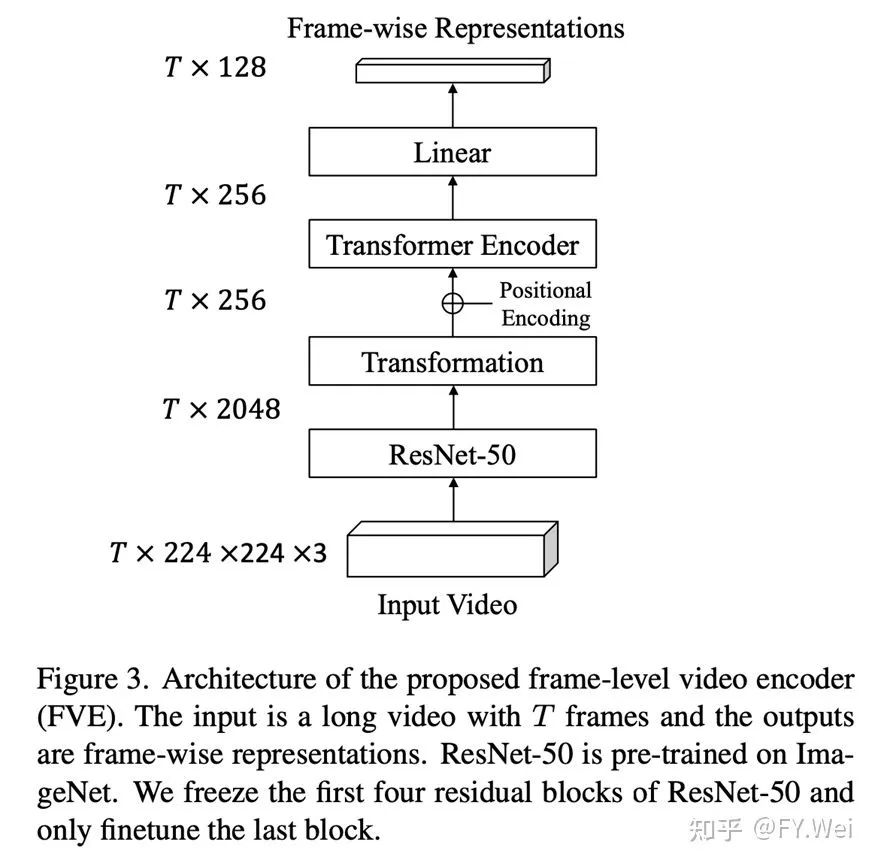
直接应用视频分类架构对数百帧的长视频序列进行建模,因其计算量巨大而无法实现。TCC提出了一种视频编码器,它将2D ResNet和3D卷积相结合,以生成逐帧特征。然而叠加太多3D卷积层会导致计算成本过高。这导致这种类型的设计可能只有有限的感受野来捕捉时间上下文。最近,Transformers在计算机视觉方面取得了巨大的进步。Transformers利用注意机制解决序列到序列任务,同时轻松处理远距离依赖关系。在本网络实现中,我们采用了Transformer编码器来建模时间上下文。
图3展示了我们的帧级视频编码器(FVE)。为了在表征性能和推理速度之间达到平衡,我们首先使用一个2D网络(例如ResNet-50)沿时间维度提取长度为T×224×224×3的RGB视频序列的空间特征。然后用一个转换块(该转换块由两个具有批量归一化ReLU的全连接层组成),将空间特征投影到大小为T×256的中间嵌入。遵循常规做法,我们在中间嵌入的顶部添加了正弦-余弦位置编码,以编码顺序信息。接下来,将编码后的嵌入输入到3层Transformer编码器中,以对时间上下文进行建模。最后,采用一个线性层来获取最终T×128的逐帧表征。
其中2D 的ResNet-50网络在ImageNet上进行了预训练。考虑到计算预算有限,我们冻结了前四个残差块,因为它们已经通过预训练学习了良好的低级视觉表征。值得注意的是,这个简单的模型在训练期间最多可以处理 1000 帧,在测试期间最多可以同时处理 6000 帧(大约 5 分钟)。
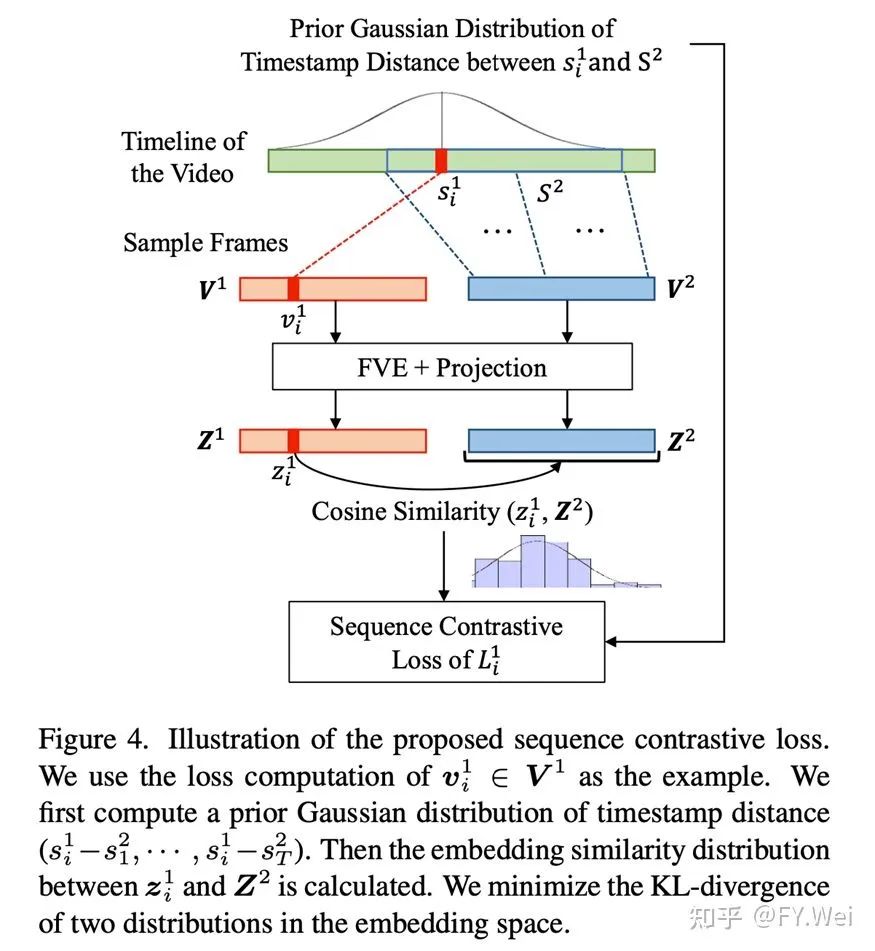
SimCLR通过最大化同一实例的增强视图之间的一致性,引入了一个叫做NTXent的对比损失。与图像的自监督学习不同,视频提供了丰富的序列信息,这是一个重要的监督信号。对于典型的实例判别,除了正面参考样本之外的所有实例都被判定为负样本。然而,参考帧附近的帧高度相关。直接将这些帧视为负样本可能会损害学习过程,因此我们应该尽量避免这个问题。为了优化逐帧表征,我们提出了一种新的序列对比损失(SCL),它通过最小化两个增强视图的嵌入相似性和先验高斯分布之间的KL散度来实现,如图4所示。我们假设每个视频帧的潜在嵌入和另一个视频序列的潜在向量之间的嵌入相似性遵循时间戳距离的先验高斯分布。具体来说,view1中帧的先验分布是以该帧为中心的高斯分布。另一方面,我们通过特征之间的余弦相似度来计算预测相似度。然后将序列对比损失(SCL)定义为预测相似性与先验分布之间的KL散度。
我们的自监督方法在三个密集标注的视频数据集,即PennAction、FineGym和Pouring上评估本方法。我们在三个数据集上的性能远超之前相关工作。
如表1和表2所示,我们报告的结果在4个指标上:细粒度动作分类,动作阶段完成程度预测,衡量两个视频匹配程度的Kendall’s Tau,以及细粒度帧检索的平均精度@K。我们的方法不仅优于其他使用联合训练的方法,而且在不同的评估指标下也大大优于per-action(对每个动作类别使用特定网络的)训练策略的方法。而且出乎意料的是,尽管我们的模型没有经过成对数据的训练,但它仍然可以从其他视频中成功地找到具有相似语义的帧。对于所有的AP@K,我们的方法优于以前的方法至少11%。
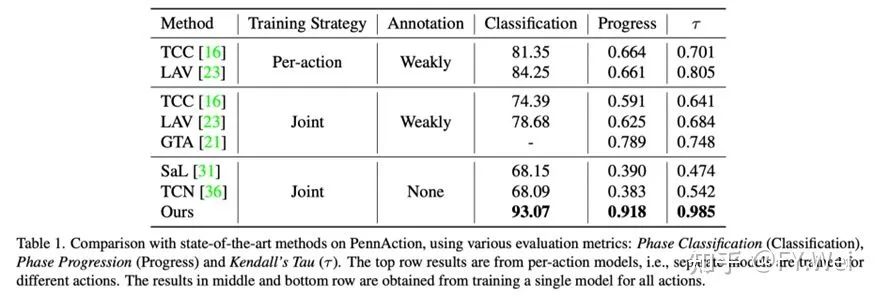
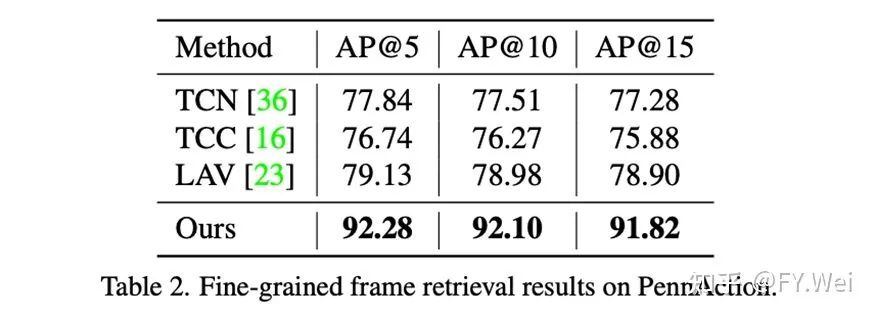
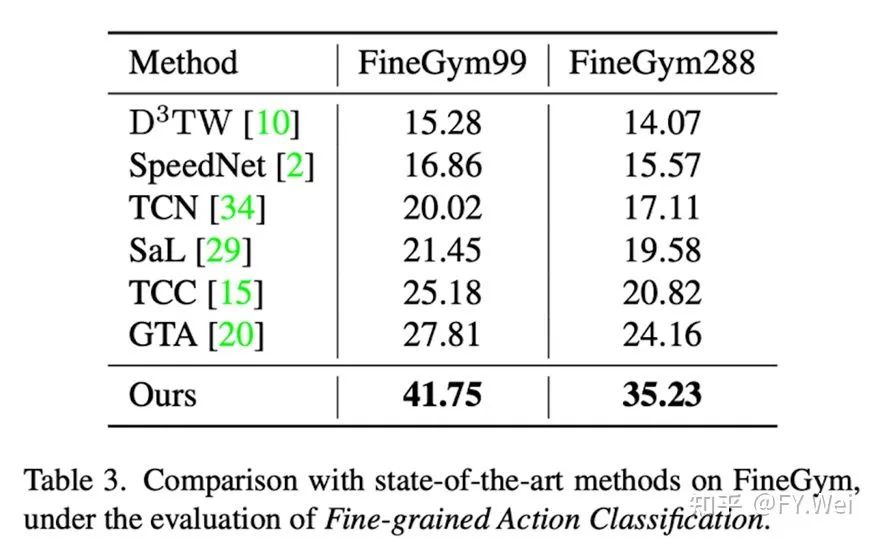
表3总结了FineGym99和FineGym288上细粒度动作分类的实验结果。结果显示我们的方法优于其他自监督和弱监督方法。我们的方法在FineGym99和FineGym288上的性能比之前最先进的方法GTA分别高出+13.94%和+11.07%。如TCC、TW和GTA等弱监督方法假设训练集中的两个视频之间存在最佳对齐。然而,对于FineGym数据集,即使在描述同一动作的两个视频中,子动作的设置和顺序也可能不同。因此,这些方法找到的对齐可能不正确,因而会阻碍学习。我们的方法在两个指标上有很大的提高,从而验证了我们框架的有效性。
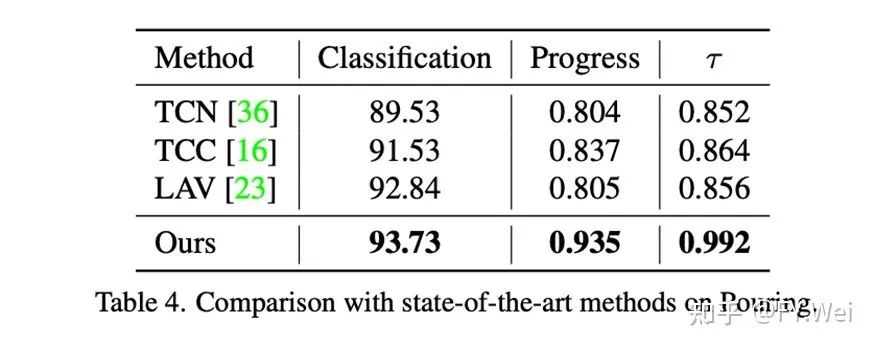
如表4所示,在一个相对较小的数据集Pouring上(记录了第一人称和第三人称视角倒水动作的视频集),我们的方法性能也是最好的。这些结果进一步证明了我们的方法具有很强的泛化能力。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看




