GANimation:基于解剖结构的面部表情转换(附GitHub地址)
编者按:说到GAN在人脸上的应用,就不得不提起去年高丽大学、Clova AI Research、新泽西大学和香港科技大学共同发表的一项成果:一个可以在多域图像间实现图对图转换的统一生成对抗网络——StarGAN。它不仅能调整图像中的发色、肌理、肤色、性别,还能合成各种生动有趣的表情。而就在上周,美国的一群研究人员基于解剖学上的肌肉运动方式,提出了一种转换表情的新方法。

近年来,生成对抗网络(GAN)已经在面部表情合成任务中取得了令人印象深刻的结果,这为包括电影工业、摄影、时尚和电子商务在内的商业领域打开了一扇新大门:如果GAN真的能实现表情的自然转换,企业、制片方不仅能进一步压缩成本,还能加快产品的产出效率。
在这个背景下,去年提出的StarGAN无疑是目前最成功的架构,它只用一对生成器和判别器就能实现多个域之间的映射,且能对各个域的图像进行有效训练。虽然论文较以往成果有巨大进步,也显示出了通用性,但它只是把以前的2个域扩展到现在的k个域,模型转换效果还是受数据集注释局限。
为了解决这个问题,近日,西班牙IRI和美国俄亥俄州立大学的研究人员提出了一种基于动作单元(AU)的新型GAN,它在连续流形中描述了解剖学意义上的人类面部表情。经过无监督训练后,只需控制每个AU的激活程度,并选取其中几个进行组合,模型就能实现生动形象的表情转换。
模型架构和方法
首先,我们来看这个GAN的具体构造。
对于任意表情,模型把输入的RGB图像定义为Iyr∈RH×W×3。通过把复杂表情解构成一个个动作单元(AU),我们可以用一组N个AU yr = (y1, . . . , yN)T对每个表情编码,其中yn已经经过归一化处理,取值在0到1之间。有了这种连续表征,我们就可以在不同表征之间进行自然插值,从而渲染各种逼真、平滑的面部表情。
简而言之,我们的目标是学习一个映射M,它能把输入图像Iyr转换成基于目标AU yg的输出图像Iyg。
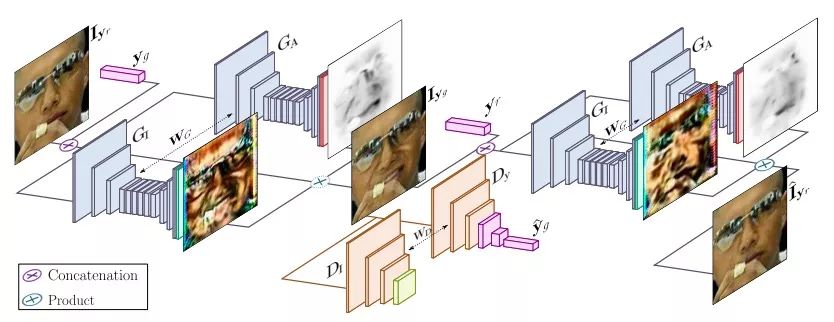
上图是GANimation的整体架构,可以发现,它主要由两部分组成:一个生成器G,一个判别器D。其中生成器负责回归注意力(GI)和生成色彩掩模(GA),判别器负责鉴别生成图像逼真与否(DI),并检查表情是否连贯(yˆg)。
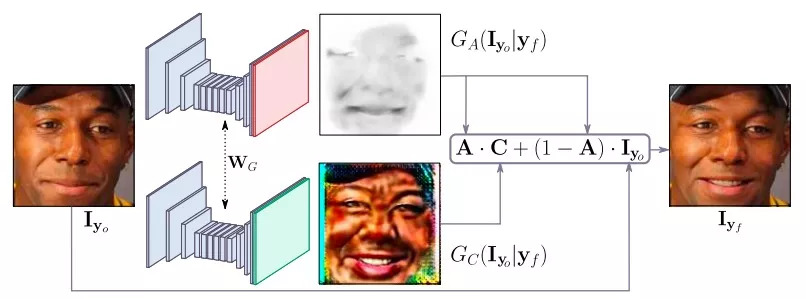
既然重点是AU,那么模型的一个关键自然是专注于图像中那些负责合成新表情的区域,换言之,我们需要弱化头发、眼镜、帽子或珠宝等其他元素对模型的干扰。为了实现这一点,如上图所示,研究人员在生成器中引入注意力机制,把输入图像分成注意力掩模A和RGB掩模C,完成表情转换后再合并渲染。
什么是AU
关于什么是AU,文中并没有仔细说明,所以这里我们来看它重点引用的另一篇论文。
这篇名为Compound facial expressions of emotion的论文来自俄亥俄州立大学哥伦布分校,它和GANimation有一个共同的作者:Aleix M. Martinez。根据他们的研究,人类的不同面部表情可能存在一定相关性,比如当一个人感到惊喜时,他的面部肌肉群运动其实结合了愉悦、惊讶两种基础情绪的肌肉运动方式。
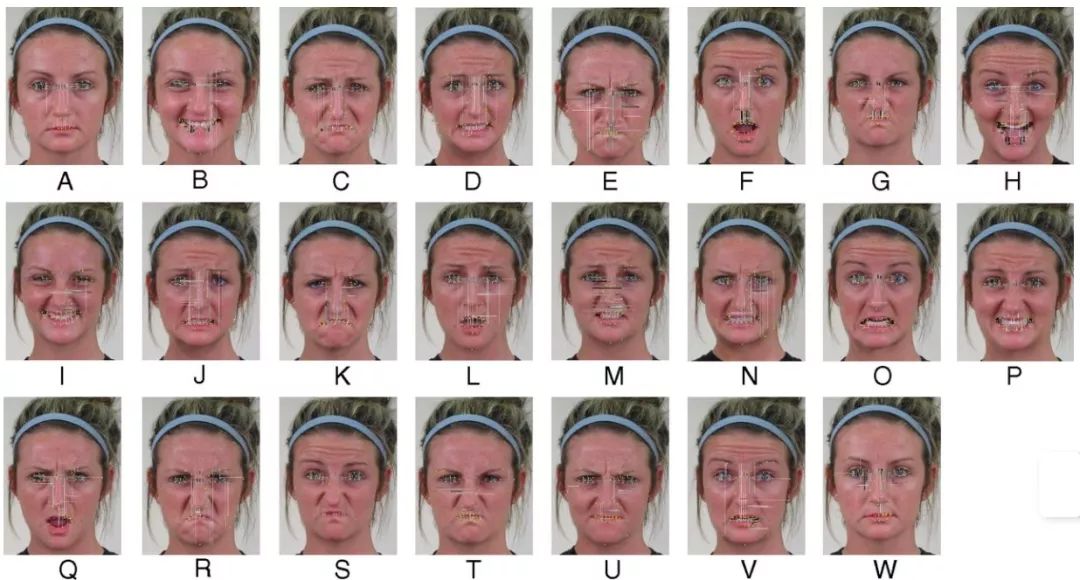
基于这个发现,他们提出了一种名为复合情感类别的重要表达式。通过采集230名人类受试者的面部表情样本图像,并进行观察实验,最终他们定义了21种不同表情类别,其中的差异可以被计算机用来区分不同人类情感。

数据库中的22种常见表情
用线条进行肌肉运动分析
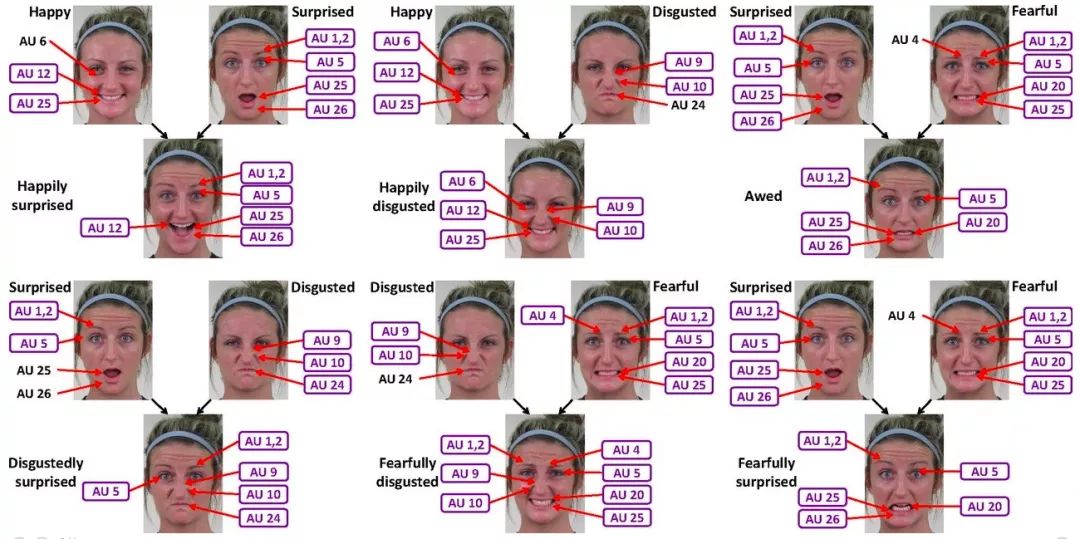
六种复合面部表情的AU组成
很可惜,仔细浏览了论文好几次,我还是没能从中找出AU对照表。下表是目前已知的几项内容:
不过不知道也没关系,这个GAN已经公开了自己的pytorch实现:github.com/albertpumarola/GANimation。如果有读者希望获得完整表格,建议直接联系作者,或者依照俄亥俄州立大学论文中的方法自己总结,里面详尽列出了数据来源、具体方法和操作细节。
实验
最后是实验对比,我们先来看看GANimation和DIAT、CycleGAN、IcGAN、StarGAN这些模型的性能区别。
如下图所示,前三种模型都出现了不同程度的扭曲和畸变,表现较差;而StarGAN虽然保留了更多人脸细节,生成表情也更自然,但牺牲了清晰度,输出图像比较模糊。相比之下,GANimation虽然在脸型上出现了一点小瑕疵,但它的综合表现是最好的。

下图是GANimation的一些成功和失败的例子。其中前两个例子(顶行)对应于类似人的雕塑和非现实主义风格绘画。在这两种情况下,生成器都能保持原始图像的艺术效果,并且忽略诸如眼镜遮挡之类的伪像。

第三行的示例显示了模型对于面部非均匀纹理的稳健性。可以看到,把微笑转换成不满后,女郎鼻翼两侧出现了下陷的法令纹,但模型并没有试图通过添加/去除头发来使纹理均匀化。
底部是一些失败案例。研究人员归纳了失败原因,认为这些很可能都是因为训练数据不足引起的。如红脸男子图所示,当模型输入极端表情时,RGB掩模没有及时调整权重,导致嘴部出现透明化。此外,如果输入图像的主体不是人类,那模型的表现也会很差。
小结
传统的方法,比如Face2Face,需要极度依赖3D面部重建模型,适用面非常小,也难以扩展到任意身份。相反地,这篇论文以解剖学意义上的肌肉运动为条件,在处理极端输入时更稳健,效果更好。总而言之,这是篇不错的论文,而且提出了全然不同的转换方法,它的思路值得学习借鉴。
最后再提一遍资源地址:github.com/albertpumarola/GANimation






