布朗大学华人统计30个会议,25年最佳论文:微软第一,清北排名30开外
![]()
新智元报道

新智元报道
编辑:LRS
【新智元导读】最近布朗大学的一位华人副教授纯手工统计30个会议,25年最佳论文奖,学习效率max!并且制作者还附上了一个仅供娱乐参考的排名:微软排名第一,北大清华排名30开外。
计算机会议上一般都会设置一个最佳论文奖,每次看到有大神获奖是不是都有一种膜拜和学习一番的冲动?

最近有研究人员整理了过去25年(1996-2021)里计算机科学领域的主要会议的所有最佳论文,包括AAAI, ACL, CVPR, KDD, SIGIR, WWW等30个会议,让你一次学个够!

网址:https://jeffhuang.com/best_paper_awards/
对于没有最佳论文奖的会议,如SIGGRAPH,CAV等,研究人员把优秀论文奖和杰出论文奖的论文放到了里面,但最佳学生论文和十年最佳论文没有包含在里面。并且一些开在2021年的会议也还没有进行更新,例如CVPR2022,AAAI2022。
下面就来一起来看看哪些华人论文能拿到最佳论文奖吧!
CVPR
CVPR
最近一篇华人得奖的CVPR论文为CVPR2020,由牛津大学的Shangzhe Wu摘得。

论文地址:https://www.semanticscholar.org/paper/2245620c912d669dd6ceb325c127ecbba01b1516
他目前是牛津VGG的四年级博士生,研究侧重于无监督的3D学习和反向渲染,设计无监督的算法,通过在没有明确标注数据的情况下训练无标注图像和视频上自动捕捉基于物理学的3D表示。

论文提出了一种从原始单视角(raw single-view)图像中学习三维可变形物体类别的方法,并且无需外部标注数据。该方法基于一个自编码器,编码器将每个输入图像分为深度depth、反照率albedo、视点viewpoint和光照illumination。为了在没有监督的情况下分解这些成分,需要利用到许多物体类别至少在原则上具有对称结构的事实。
研究结果表明,即使物体外观由于阴影导致看起来不是对称的,但由于光照的推理使得模型能够利用潜在的物体对称性。此外,研究人员通过预测对称性概率图对可能是,但不一定是对称性的物体进行建模,并与模型的其他部分进行端对端学习。
实验结果表明,这种方法可以从单视角图像中非常准确地恢复人脸、猫脸和汽车的三维形状,而不需要任何监督或预先的形状模型。在基准测试中,结果也证明了与另一种在二维图像对应水平上使用监督的方法相比,具有更高的准确性。
ACL
ACL
ACL2021的最佳论文来自字节跳动的Jingjing Xu。

论文地址:https://aclanthology.org/2021.acl-long.571/
代码:https://github.com/Jingjing-NLP/VOLT
token vocabulary的选择会影响机器翻译的性能。这篇论文旨在弄清楚什么是好的词汇,以及是否可以在不进行实验训练的情况下找到最佳词汇。为了回答这些问题,研究人员首先从信息论的角度对词汇进行了另一种理解,形式化vocabularization—寻找具有适当规模的最佳token vocabulary—表述为一个最优传输(optimal transport, OT)问题。
论文提出了一个简单有效的解决方案VOLT,经验结果表明,VOLT在不同的场景下的性能都比广泛使用的词表要好,包括WMT-14英德翻译、TED多语翻译。例如,VOLT在英德翻译中实现了降低70%的词汇量,并且提高了0.5的BLEU。此外,与BPE-search相比,VOLT将英德翻译的搜索时间从384个GPU小时减少到30个GPU小时。
KDD
KDD
KDD2019的最佳论文来自墨尔本皇家理工大学的Yipeng Zhang.
论文地址:https://dl.acm.org/doi/10.1145/3292500.3330829
研究人员提出并研究了在考虑到impression count的情况下优化户外广告的影响力问题。给定一个广告牌数据库,每个广告牌都有一个位置和一个非统一的成本,一个轨迹数据库和一个预算,其目的是找到一组在预算下具有最大影响力的广告牌。与广告消费者行为研究一致,在定义影响力度量时,研究人员采用逻辑函数来考虑放置在不同广告牌上的广告对用户轨迹的impression count。这也带来了两个挑战:
(1)对于任何ε>0的多项式时间,要在O(|T|1-ε)的系数内近似,这个问题都是NP-hard的;
(2)影响力测量是non-submodular的,这意味着直接的贪婪方法是不适用的。
因此,研究人员提出了一种基于切线的算法来计算一个submodular函数来估计影响力的上限。引入了一个具有θ终止条件的分支和边界框架,实现了θ2/(1-1/e)的近似率。
然而,当|U|很大时,这个框架很耗时。因此,研究人员用渐进式修剪上界估计方法进一步优化,实现了θ2/(1 - 1/e - ε)的近似率,并大大减少了运行时间。在真实世界的广告牌和轨迹数据集上进行的实验结果表明,所提出的方法在有效性上比基线要好95%。此外,优化后的方法比原来的框架要快两个数量级。
AAAI
AAAI
AAAI2021的最佳论文有两篇,其中一篇是来自北京航空航天大学的Informer模型。

论文地址:https://www.aaai.org/AAAI21Papers/AAAI-7346.ZhouHaoyi.pdf
现实世界的应用经常需要对长序列的时间序列进行预测,例如用电规划等。长序列时间序列预测(LSTF)要求模型具有高预测能力,即能够有效地捕捉到输出和输入之间精确的长距离依赖耦合关系。一些研究表明Transformer有潜力来提高模型预测能力,但Transformer有几个严重的问题使其不能直接应用于LSTF,例如二次时间复杂度,更高的内存消耗量,以及编码器-解码器结构的固有限制。
为了解决这些问题,研究人员设计了一个高效的基于Transformer的模型,命名为Informer,模型具有三个显著的特点:(i) ProbSparse Self-attention机制,该机制在时间复杂度和内存使用方面达到了O(Llog L),并在序列的依赖关系对齐上性能相当不错;(ii) 自注意力的提炼通过将级联层的输入减半来突出更重要的注意力,并能够有效地处理极长的输入序列;(iii) 生成式的风格解码器(sytle decoder),虽然在概念上很简单,但一次forward操作中就能预测出长时间序列的预测,而不是以逐步进行的方式,极大地提高了长序列预测的推理速度。
在四个大规模数据集上的实验结果表明,Informer的性能明显优于现有方法,并为LSTF问题提供了一个新的解决方案。
Microsoft夺冠
Microsoft夺冠
除了按照会议、年限来查看最佳论文外,制作者还对每篇最佳论文的作者研究机构进行了排序。
按照第一个作者获得1分,第二作者0.5分,第三作者0.33分等进行打分,然后把分数进行归一化。
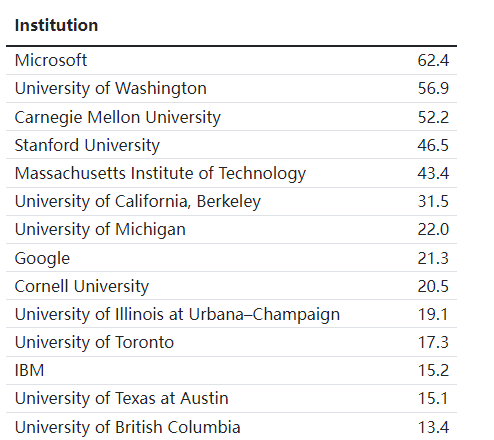
制作者表示,这个排名可能不准确或不完整,也可能不会反映最佳论文奖的当前状态,这也并非是一个官方列表,如果对此处列出的研究机构排名不满意,那请忽略它。

可以看到微软得分62.4,其次是华盛顿大学56.9和卡内基梅隆大学的52.2,相比之下Google得分只有21.3,还不到微软的三分之一。
中国的研究机构前两名分别是北京大学和清华大学,排名都在30位之后。
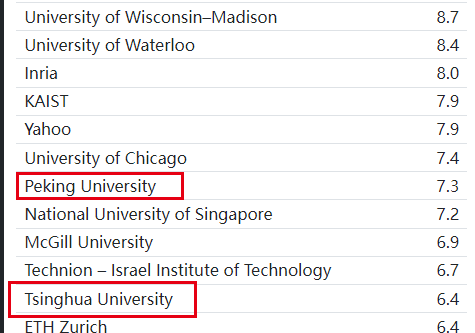
制作者信息
制作者信息
最佳论文集合的数据都是由制作者手动在网络上搜索整理而成,可以说是相当辛苦了!
表格的制作者是Jeff Huang,目前布朗大学计算机科学系的副教授,主要研究领域是人机交互和建立基于用户行为数据的个性化系统,并将系统应用于注意力、移动和健康领域,曾获得美国国家科学基金会CAREER奖、Facebook奖学金和ARO青年研究者奖。

Jeff Huang博士毕业于西雅图华盛顿大学的信息科学专业,在伊利诺伊大学厄巴纳-香槟分校(UIUC)获得计算机科学的硕士和本科学位。在入职布朗大学之前,曾在微软研究院、谷歌、雅虎和必应分析过搜索行为;还创办了World Blender公司,一家由Techstars支持的制作基于地理位置的手机游戏(geolocation mobile games)。
参考资料:





