视觉场景是由有语义意义的像素组构成。在深度学习的概念出现之前,业界就已经使用经典的视觉理解方法对像素分组和识别进行深入研究。自下而上分组的思想是:首先将像素组织成候选组,然后用识别算法模块处理每个分组。这种思路已经成功应用于超像素图像分割、以及目标检测和语义分割的区域构建。除了自下而上的推理,识别过程中自上而下的反馈信号,能够更好地完成视觉分组。
随着深度学习时代的到来,显式分组和识别的思想,在端到端的训练系统中已经不再那么泾渭分明,而是更紧密地耦合在一起。例如,语义分割通常是通过全卷积网络实现的,其中像素分组仅通过识别每个像素的标签在输出层显示。这种方法不需要对像素显式分组。虽然这种方法非常强大,并且性能是最好的,但它有两个主要的局限性:(1) 每像素的人工标签成本很高;(2) 学习的模型仅限于几个标记的类别,不能泛化到未知的类别。
从文本监督中学习视觉表达的最新进展在迁移到下游任务方面取得了巨大成功。学习到的模型不仅以零样本方式迁移到 ImageNet 分类中并实现最好的性能,还可以对 ImageNet 分类以外的未知对象类别进行识别。
受此研究方向的启发,来自加州大学圣圣地亚哥分校和英伟达的研究者提出这样一个问题:
我们是否也可以学习一个纯文本监督的语义分割模型,无需做任何像素标注,就能够以零样本方式泛化到不同对象类别或词汇集
?
![]()
论文链接:https://arxiv.org/pdf/2202.11094.pdf
为了实现这一点,他们提出
将分组机制加入深度网络
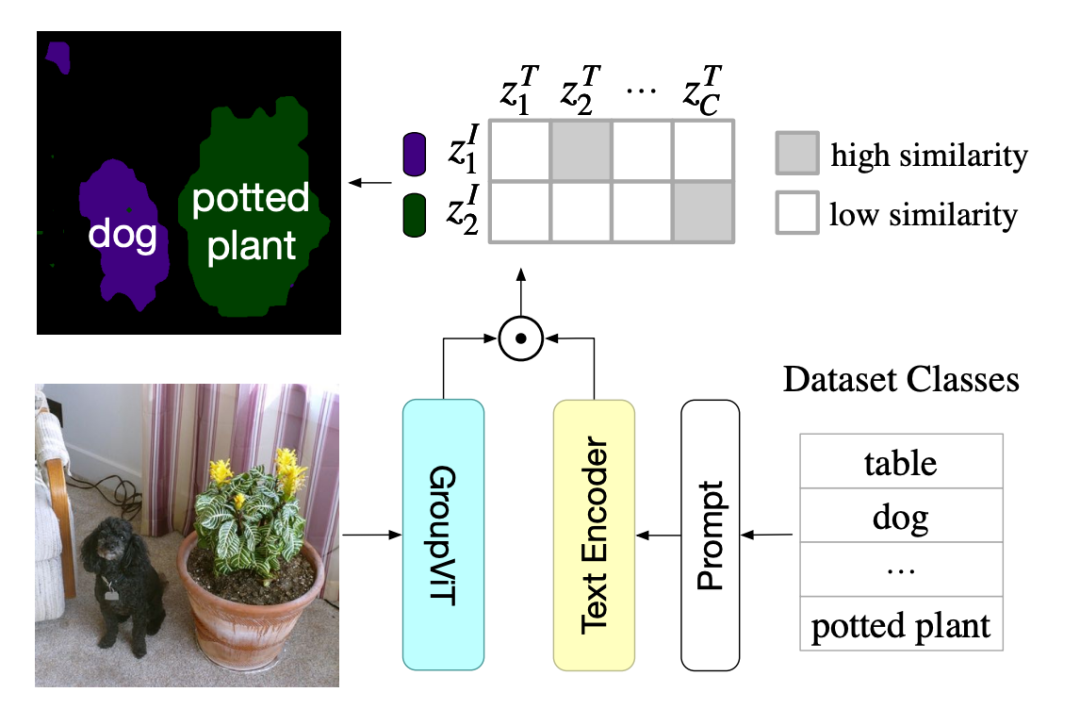
。只要通过文本监督学习,分组机制就可以自动生成语义片段。方法概览如下图 1 所示,通过对具有对比损失的大规模配对图文数据进行训练,可以让模型不需要任何进一步的注释或微调的情况下,能够零样本迁移学习得到未知图像的语义分割词汇。
该研究的关键思想是
利用视觉 Transformer(ViT)在其中加入新的视觉分组模块,研究者将新模型称为 GroupViT(分组视觉 Transformer)
。
![]()
图 1:首先使用成对的图像 - 文本数据联合训练 GroupViT 和文本编码器。使用 GroupViT,有意义的语义分组会自动出现,无需任何掩码注释。然后把训练好的 GroupViT 模型迁移到零样本语义分割任务。
GroupVit 的语义分割效果如下两个动图所示。
![]()
![]()
论文一作为 UCSD 计算机科学与工程系二年级博士生 Jiarui Xu,本工作是他在英伟达做实习生期间进行的。
超越深度网络中规则形状的图像网格:引入了一种新颖的 GroupViT 架构,将视觉概念分层自下而上分组为不规则形状的组
没有任何像素级标签,并且仅通过对比损失进行图像级文本监督的训练,GroupViT 成功地学会将图像区域组合在一起并以零样本方式迁移到多个语义分割词汇表;
第一个探索不使用任何像素级标签,完成从单独的文本监督到几个语义分割任务的零样本迁移的工作,也为这项新任务建立坚实的基础.
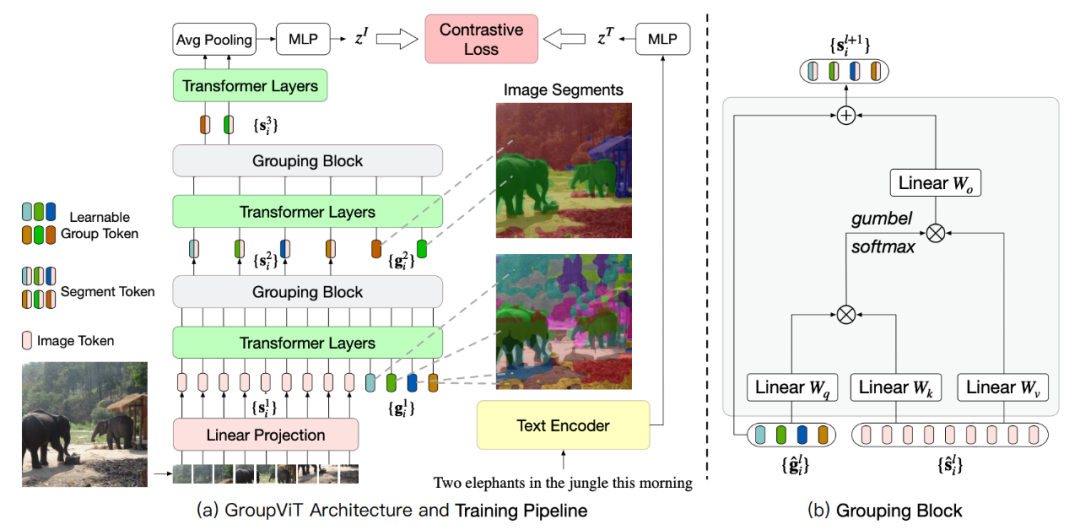
GroupViT 包含按阶段分组的 Transformer 层的分层结构,每个阶段会处理逐渐放大的视觉片段。右侧的图像显示了在不同分组阶段要处理的视觉片段。在初期阶段模型将像素分组为局部对象,例如大象的鼻子和腿。在更高的阶段进一步将它们合并成整体,例如整个大象和背景森林。
每个分组阶段都以一个分组块结束,该块会计算学习到的组标记和片段(图像)标记之间的相似度。相似度高的组会分配给同一组的段标记并合并在一起,并做进入下一个分组阶段的新段标记。
![]()
图 2:(a) GroupViT 的架构和训练流程。(b) 分组块的架构。
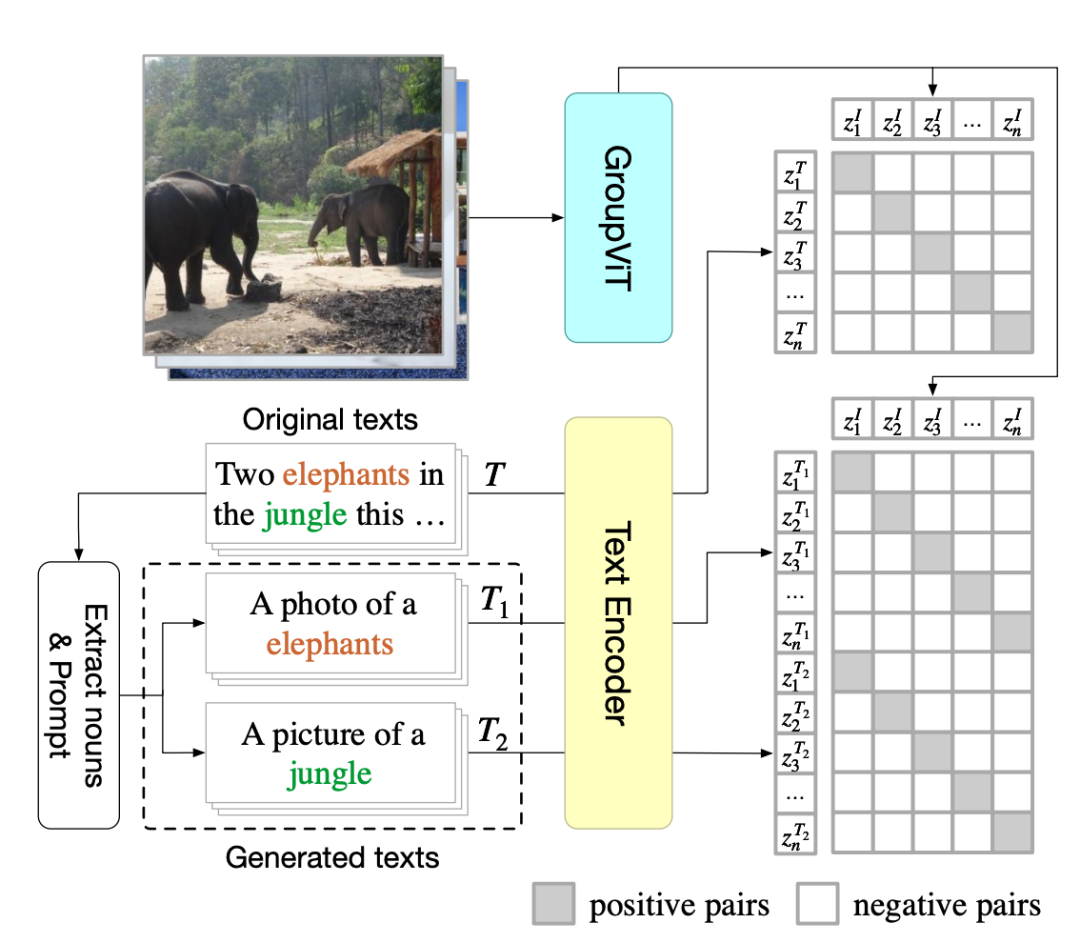
为了训练 GroupViT 进行分层分组,研究者在图像 - 文本对之间使用了精心设计的对比损失。
下图 3 为多标签图文对比损失。给定一个输入的图像 - 文本对,他们通过提取其名词并通过一些句子模板提示,来从原始文本中生成新文本。对于对比学习,只有图像和文本对匹配的被认定为正例。研究者训练 GroupViT 和文本编码器以最大化图像 - 文本对正例之间的特征相似性,并最小化负例对之间的特征相似性。
![]()
由于 GroupViT 自动将图像分组为语义相似的片段,因此其输出可以轻松地 Zero-Shot 迁移到语义分割,而无需任何进一步的微调。零样本迁移的流程参见下图 4。GroupViT 的每个输出段嵌入对应于图像的一个区域。研究者将每个输出段分配给嵌入空间中图像 - 文本相似度最高的对象类。
![]()
研究者选择部分组 token 并且突出 PASCAL VOC 2012 数据集中的注意区域。即使还没有分类,不同的组 token 正在学习不同的语义概念。
![]()
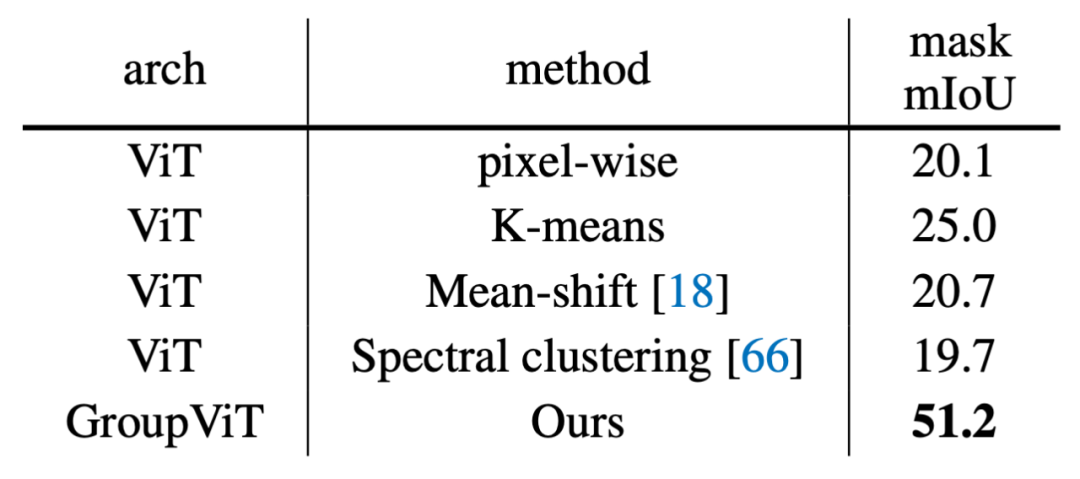
为了识别 GroupViT 的每个组件的贡献,研究者进行了消融实验。对于所有实验,除非另有说明,否则都默认使用 CC12M 数据集训练 1-stage 的 GoupViT。他们在 PASCAL VOC 2012 验证集上,记录预测的 mIoU 和分割掩膜。
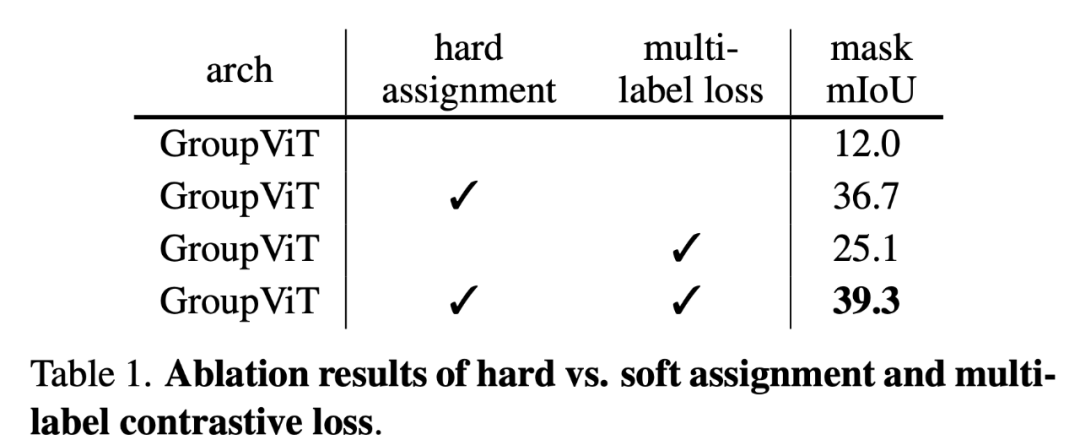
硬分配与软分配:在每个分组块中,研究者使用硬分配或软分配将图像片段标记分配给组 token(第 3.1 节)。对于软分配,他们使用原始的 A^l 矩阵而不是用于硬分配的
![]() 来计算公式 5。这样做的影响见下表 1 的第一列。
来计算公式 5。这样做的影响见下表 1 的第一列。
![]()
多标签对比损失
。研究者研究了表 1 的第二列中,添加多标签对比损失的效果。将多标签对比损失添加到标准损失(公式 8)中,硬分配和软分配的性能分别提高了 13.1% 和 2.6%。使用多标签对比损失,训练和推理期间的输入文本采用类似的提示格式。他们推测这种一致性有助于 GroupViT 更好地将学习到的图像片段分类为标签的类别。
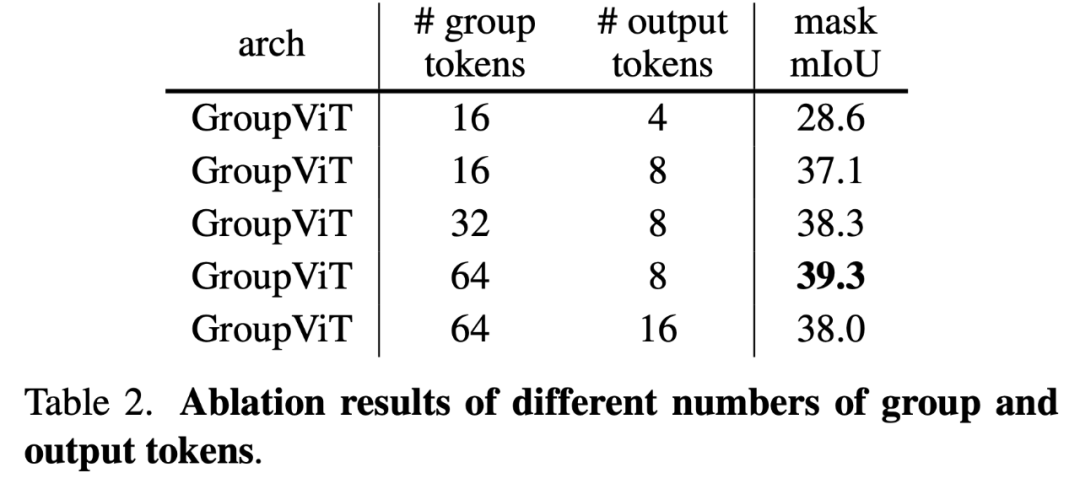
组 token
。在下表 2 中,研究者比较了不同的组 token 和输出 token。他们观察到,不断增加组 token 会持续提高性能。从概念上讲,每个组 token 代表不同的语义概念。所以更多的组 token 可能有助于 GroupViT 学习对更多的语义概念进行分组。尽管组 token 的数量远少于现实世界中的类别数量,但每个组 token 都是 384 维嵌入空间中的 1 个特征向量,但它可以表示比 1 更多的概念。他们还对不同的输出 token 进行了实验,发现 8 是最优的,类似于 [64] 中的发现。
![]()
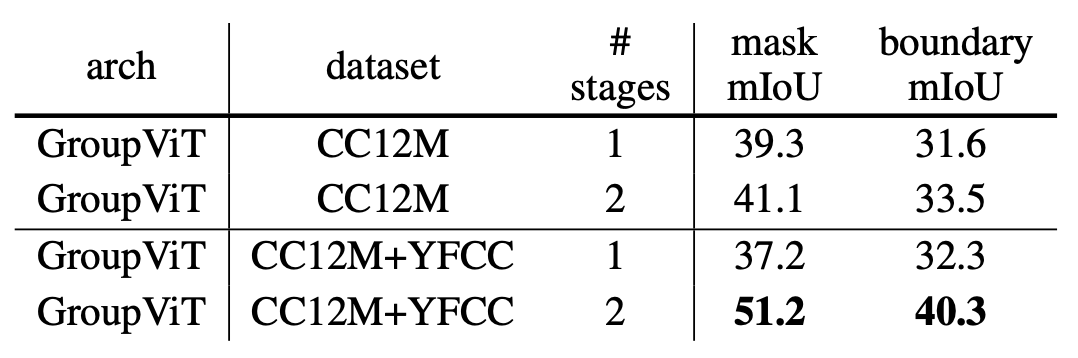
多阶段分组
。在下表 3 中,研究者比较了 1-stage 和 2-stage GroupViT 架构。
![]()
研究者还在下图 5 中比较了 1-stage 和 2-stage 的视觉零样本语义分割结果。
![]()
2-stage GroupViT 生成的分割图比 1-stage GroupViT 更平滑、更准确。
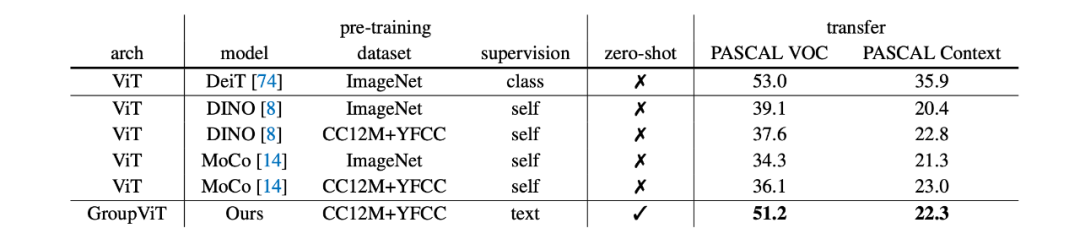
研究者在 Pascal VOC、Pascal Context 和 COCO 数据集上对 GroupViT 进行评估。GroupViT 在没有接受任何语义分割注释的训练情况下,可以零样本迁移到任何数据集的语义分割类,并且无需对模型微调。
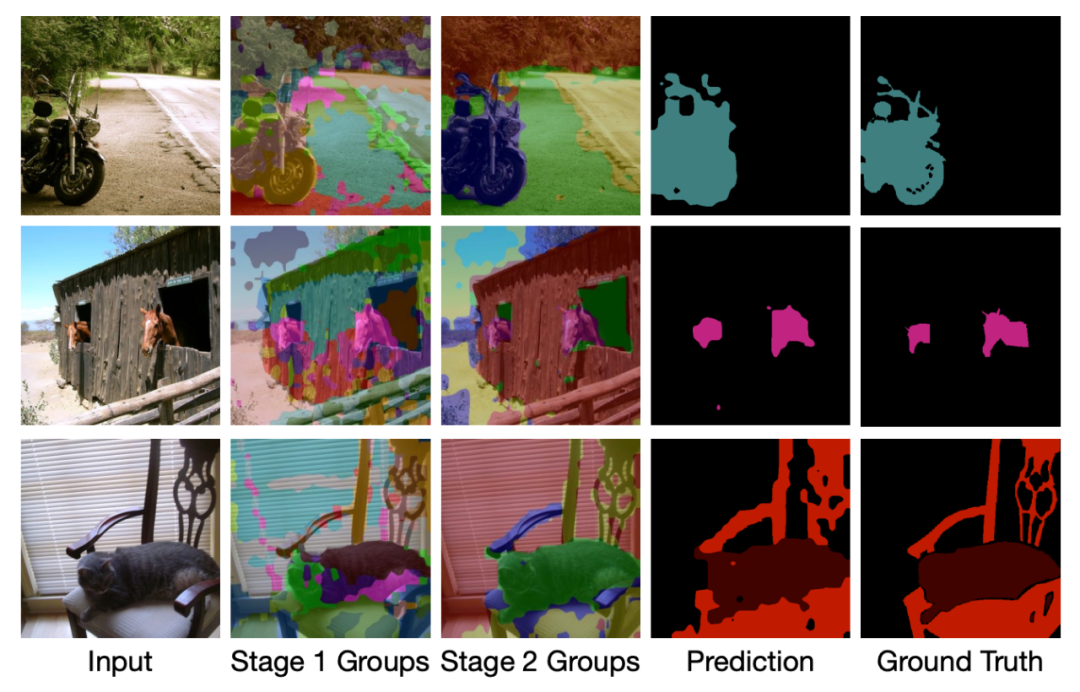
在 PASCAL VOC 2012 数据集上定性实验结果
。下图 6 展示了 GroupViT 的特定定性分割结果。他们选择具有单个目标(第 1 行)、同一类的多个目标(第 2 行)和不同类的多个目标(第 3 行)进行了实验。实验证明 GroupViT 可以生成合理的分割。
![]()
图 6:PASCAL VOC 2012 的定性结果。阶段 1/2 组在分配标签之前对结果进行分组。
通过组标记的概念学习。下图 7 中可以直观地看到组 token 学习的内容。研究者选择部分组标签并且突出 PASCAL VOC 2012 数据集中的注意区域。
他们发现不同的组 token 会学习不同的语义概念。在第一阶段,组 token 通常侧重于中级概念,例如如「眼睛」(第 1 行) 和「四肢」第 2 行)。有趣的是,如果图片中有人,组 token 36 会关注「手」,而如果有鸟和狗等动物,则会关注「脚」。第二阶段的组 token 更多地与高级概念相关联,例如「草」、「身体」和「脸」。图 7 还表明,第一阶段学习的概念可以在第二阶段聚合为更高级别的概念。
![]()
图 7:通过组标记的概念学习。研究者强调了组 token 在不同阶段所涉及的区域。
研究者将 GroupViT 的零样本语义分割性能与其它零样本基准、基于 ViT-S 的全监督迁移方法进行了比较。结果详见下表 4 和表 5。
![]()
![]()
表 5:与完全监督迁移模型的比较。零样本意味着在没有任何微调的情况下迁移到语义分割。研究者也记录了在 PASCAL VOC 2012 和 PASCAL 上下文数据集的 mIoU。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com





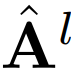 来计算公式 5。这样做的影响见下表 1 的第一列。
来计算公式 5。这样做的影响见下表 1 的第一列。