人脸注意机制网络
好久没有和大家进行学术交流,本平台也很久没有给大家推送最新的技术和知识,在此想所有关注我们平台的朋友说声抱歉,但是,我们一直在努力,为大家呈现最好的推送,今天我们推送的内容关于FACE++的一个先进技术,希望大家可以通过该技术得到很多启发,谢谢!
先看一小段视频(关于人脸检测技术视频):
主要内容:
文章提出一种新颖的人脸检测器,叫做人脸注意网络(FAN)。在不影响速度的情况下,可以显著提高遮挡情况下人脸检测问题的召回率。更具体地说,提出了一个新的anchor level的attention机制,这将突出脸部区域的特征。集成我们的anchor分配策略和数据增强技术,在公共人脸检测基准(WiderFace和MAFA)上获得最好的结果。
本文贡献:
提出了一个anchor level的attention机制,它可以很好地解决遮挡问题的人脸检测任务,如下图:

精心设计的anchor setting,可以获得快速计算的性能;
FAN在流行的人脸检测基准上,明显优于最先进的检测器,尤其在遮挡情况下。
相关工作:
从背景上来看,对于人脸的检测,跟General detection一脉相承。从是否需要提取proposal和是否需要对这个proposal进行二次操作的角度来简单划分的话,主要分为One stage detector和Two stage detector。
这两个方法总体来说是各有利弊。One stage detector主要的优势是快速,这个主要是从工程上来说,假如你在手机上从一个256甚至更高维度的1024的channel上直接crop一个feature出来,是一个相当耗时的工作,所以one stage天然就有很好的速度优势。但是one stage有也存在不足,它由于没有后面refine的过程,在两个人脸或者是两个物体挨得比较近,或者是难以辨认的情况下,one stage通常会在性能上会有一定的劣势。
Face detection的挑战:
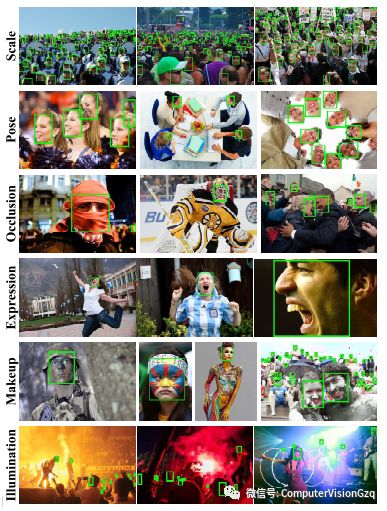
首先是scale,由于face自身的特殊性,不论是通用物体或者行人检测,通常情况下,只是在意比较近处的物体。scale的变化远远没有人脸这么大。其次是occlusion,也就是遮挡问题。遮挡问题简单的分为两部分:物体的遮挡和face的自遮挡。识别戴头巾或者口罩的人脸,这是一个典型的物体遮挡的问题,如果两个人挨得特别近,以至于把后面的人挡住了一部分,但是勉强还是可以看到另一部分,这就是face的自遮挡。
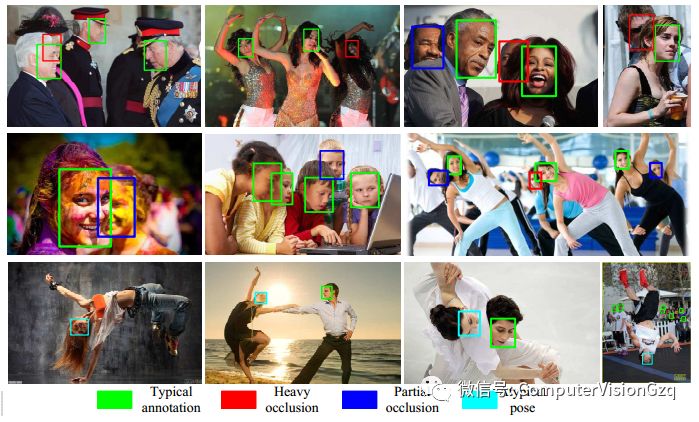
对于遮挡的物体,我们首先需要确定这是不是一个脸,或者是至少要确定这是不是一个头。这就需要context信息,例如能够看到更多的地方,能看到身躯或者是看到头的整个区域,这样就有助于判断。这些信息可以通过合理的Anchor setting或者是合理的大感受野去隐式地学到。此外,只看context信息也会产生一些误导,所以需要可见的部分来辅助确认这块区域真的是人脸,而不是其他的东西。这个时候可以考虑用segmentation或者是attention的机制去处理。
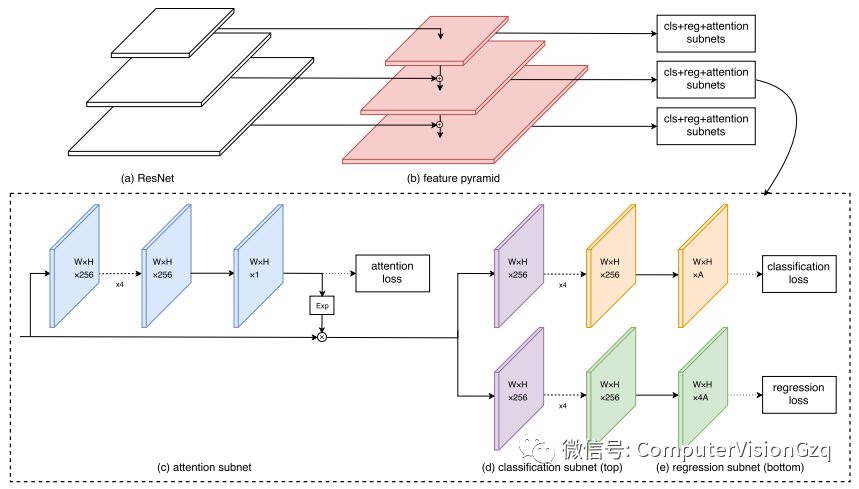
图1 FAN的主要框架
这张图是本文主要的网络设计构架。从网络设计构架上面来说,前面这个红色和这个白色的区域,可以理解为一个FPN的结构,可以复用多层的信息,通过合理的anchor设计,保证每个anchor都有较大的感觉野,隐式地学习了context信息。(c)这个部分是一个attention的子网络,我们在得到feature之后,会另开一支去学习attention,之后对attention做一个E指数的操作乘到原来的feature map上面,加强可见区域信息。后面是一个类似于fast R-CNN两支操作:一支做classification,一支做regression。Anchor setting设置可以保证每个人脸都有足够的感受野以及足够的context信息。底下这个attention的subnet,它可以通过有监督的信息,学到visible的information,也就能提高对遮挡物体检测的能力。
Attention Network
在不同的特征层中处理不同比例的人脸;
突出人脸区域的特征,减少无人脸区域;
生成更多遮挡人脸去训练。
1)Anchor Assign Strategy
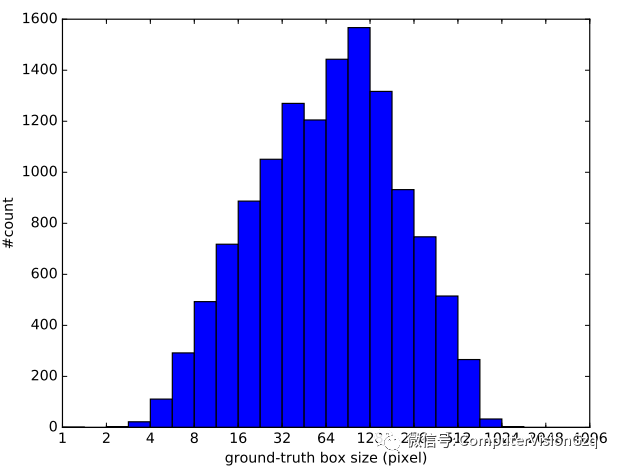
图2 WiderFace训练集目标尺寸大小分布
先统计一下Wider face训练集,大概80%以上的人脸其实都是集中在16像素到406像素这样的量级上面,还有约10%的人脸是在8像素到16像素。小尺寸的人脸缺乏足够的分辨率,因此包含在训练数据中可能不是一个好的选择。如果这个face在8pixel量级的情况下,我们把它放大出来,图像就很糊,基本上也已经没有什么纹理的信息。加入训练会引来大量的噪声,反而会导致detector性能的下降。就实验结果来看下降还是比较明显的,大概会下降2到3个点。因此,将anchors的区域在金字塔级别上选择16*16到406*406。
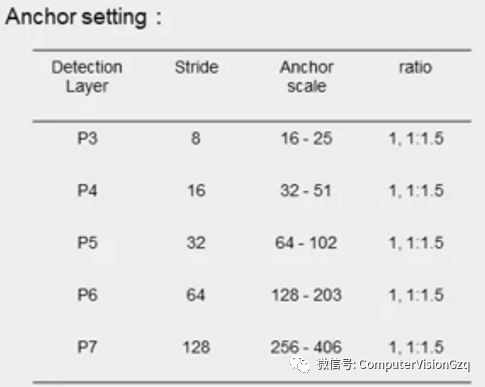
所以我们在设计上的时候,需要考虑到如何让anchor去覆盖这么大的一个区域。Ratio上的设置,我们选择了1和1:1.5,其实是潜在地考虑了正脸和侧脸两种情况,因为通常情况下一个face,在正脸的情况下,1:1都是可以接受的。侧脸的情况下,可以近似到1:1.5。
P3、P4、P5、P6、P7是分别是表示我们FPN的各个layer,P3表示的是一个浅层的信息,然后P7表示的是越深层的信息。在感受野上面,feature的感受野是anchor的4倍左右,例如P3层达到了接近100的水平,是P3 anchor的四倍大小。这样就可以提供足够的context信息来保证能够检测出轮廓。铺设密度上,没有选择传统的每一层只有一个anchor的铺设方式,采用每层3个scale,以2 ^ -1/3 步进。如果每层只铺设一个anchor,就会导致个别的ground truth分配不到一个很好的anchor。当然anchor也不是铺设得越密越好。如果把anchor铺设得更密一些,比如每层每个layer铺4个anchor,这样会导致的有很多的FP,最终导致性能下降。
2)Attention Function
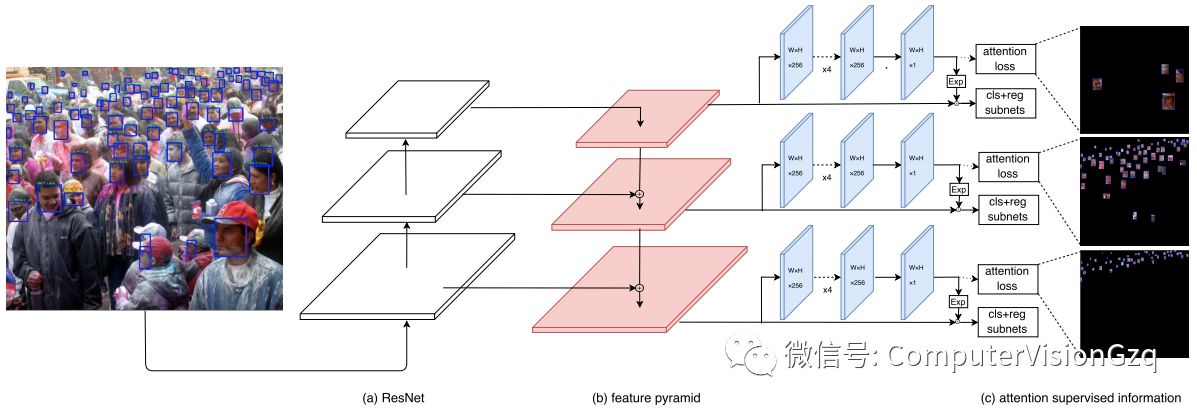
图3 注意机制用于训练的框架

图4 注意监督信息与在当前层上的anchors匹配的ground-truth相关联
不同的图层有不同的ground-truth的人脸尺寸。子图指的是:(a)具有ground-truth的原图,(b) p7层的关注监督信息,它关注大的人脸;(c)p6层的注意监督信息,它小于p7;(d)-(f)分配给P5至P3的ground-truth,分别侧重于较小的人脸。
这些层次注意图可以减少它们之间的相关性。与传统的注意力图不同,我们将注意力映射作为指数运算,然后用特征映射点。它能够保存更多的上下文信息,同时突出检测信息。考虑到遮挡面部的例子,大多数看不到的部分都是无用的,而且可能对检测有害,我们attention mask能增强面部特征映射。

图5 P7 to P3呈现的注意力图
Attention的操作:
我们之前说过,只有context的信息,很难分辨这个物体到底是不是一个被遮挡人脸。这个时候需要加入一些attention,或者是加入一些segmentation,把这些区域给学出来。
首先ground truth只有bounding box。那么我们就采用将bounding box的区域填1,直接作为segmentation去学。由于大量的ground truth是没有遮挡的,当发生遮挡时,最后学出来的segmentation会对于这些未遮挡的信息更加敏感。
其次还有一个细节,在我们的attention网络里面,做完attention之后,不是简单的点乘到原来的feature map上面,而是先做了一个E指数的操作,再去点乘到feature map上面。这样做就不是只保留attention高量的部分,而是对高量的部分做一些增强,这样能够很好地保留它原有的context信息,同时也能够突出它自身那个可见区域的信息。
然后是attention机制的整体框架。我们相比于其他的attention来说,attention不仅是有监督的,同时不同的层赋予不同的anchor level的监督信息。
3)Data Augmentation
采用随机复制策略,产生大量遮挡人脸去进行训练。更具体地说,基于训练集,随机从原始图像中裁剪出方形补丁,它的短边与原始图像之间的范围为[0.3,1]。此外,如果中心在采样块中,则保留ground-truth box的重叠部分。除了随机裁剪数据集增强之外,还采用了从随机翻转和颜色抖动的增强。
4)Loss function
采用了多任务的损失函数联合优化模型参数:
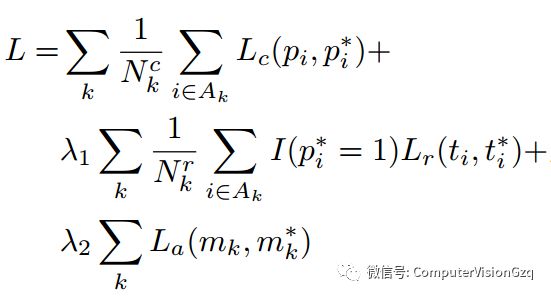
实验
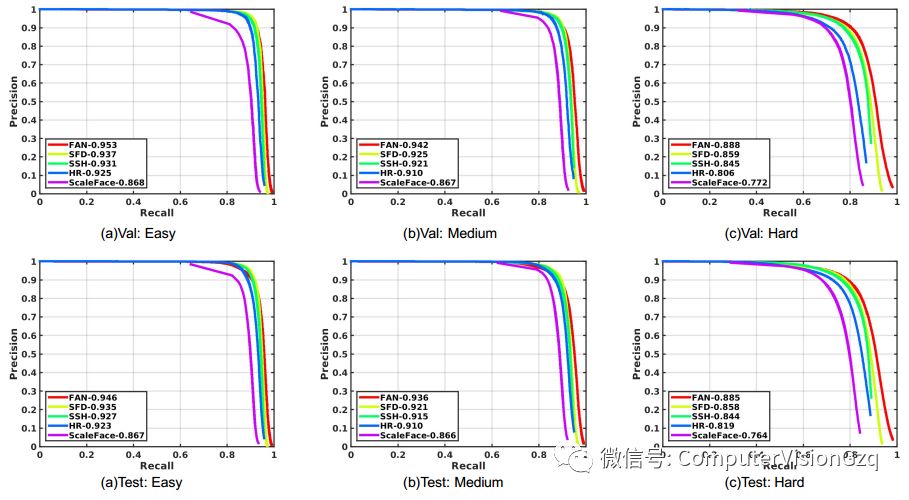
图6 在WiderFace验证集和测试集的精确度-召回率曲线
表1 FAN在WiderFace验证集上的实验结果

表2 FAN在MAFA上的实验结果

实验结果图:


在WiderFace数据集上的实验效果图
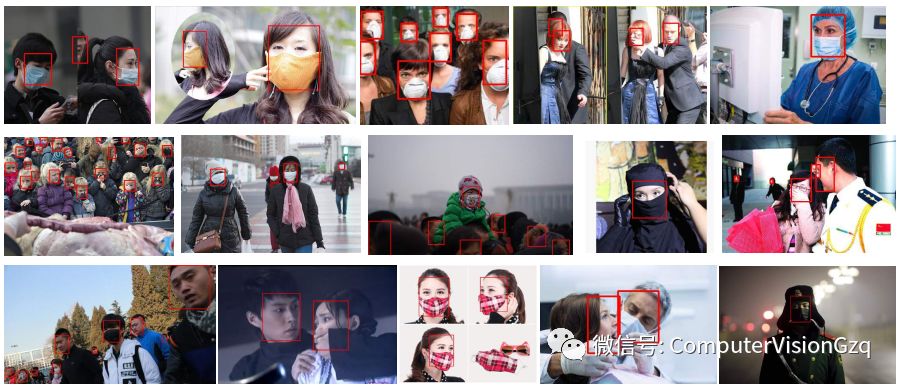

在MAFA数据集上的实验效果图
总结:
本文针对遮挡人脸的人脸检测问题进行了研究。提出了一种可以整合我们精心设计的单级基础网络和anchor-level的注意算法的FAN检测器。基于设计的anchor-level的注意机制,可以突出面部区域的特征,成功地减轻了假阳性的风险。在WideFaces和Mafa等测试基准上的实验结果验证了该算法的效率和有效性。


