目前最强性能的人脸检测算法(Wider Face Dataset)
最强性能的人脸检测

今天我们不说计算机视觉基础知识,接下来说说AAAI2019一篇比较新颖的Paper,其是中科院自动化所和京东AI研究院联合的结果,在Wider Face数据集中达到了较高的水准,比arxiv2019_VIM-FD的更好一些。今天要说的就是“Improved SRN”,现在开始一起学习吧!

人脸检测作为计算机视觉中的一个长期存在的问题,由于其实际应用,近几十年来一直受到人们的关注。
随着人脸检测基准数据集的广泛应用,近年来各种算法都取得了很大的进展。其中,Selective Refinement Network(SRN)人脸检测器有选择地将分类和回归操作引入到anchor-based的人脸检测器中,以减少假阳性同时提高定位精度。此外,它还设计了一个感受野增强块,以提供更多样化的感受野。
深度学习——感受野,如果进一步了解感受野,可以进入链接学习!
为了进一步提高SRN的性能,通过大量的实验,开发了现有的一些技术,包括新的数据增强策略、改进的backbone network、MS COCO预训练、解耦分类模块(decoupled classification module)、分割分支和压缩激励块(Squeeze-and-Excitation block)。
其中,一些技术带来了性能改进,因此,将这些有用的技术结合在一起,提出了一种改进的SRN人脸检测器,并在广泛使用的人脸检测基准的人脸数据集上获得了最佳的性能。
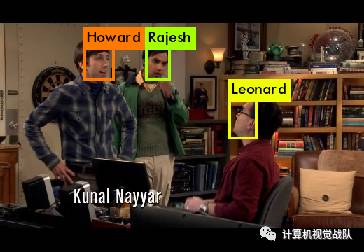
人脸检测其实比较简单,就是将图像输入算法框架中,最终返回输入图像中目标人脸的bounding box。
Review of Baseline
接下来,我们先简要回顾Selective Refinement Network(SRN)。如下图1所示,它包括选择性两步分类(STC)、选择性两步回归(STR)和感受野增强(RFE),这三个模块的详细说明如下。
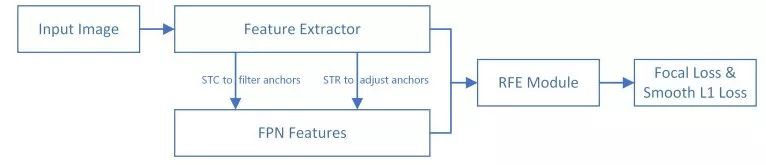
图1 SRN。它包括选择性两步分类(STC)、选择性两步回归(STR)和感受野增强(RFE)。
01
S T C
对于单级检测器,大量的正负样本比的anchor(例如,大约有300k个anchor,SRN中的正/负比约为0.006%)导致了相当多的假阳性。因此,它需要另一个阶段,如RPN过滤掉一些负样本。选择性两步分类是从RefineDet继承而来的,有效地拒绝了大量的负样本anchor,缓解了类不平衡问题。
STC作用于浅层Feature Map上,来过滤掉大部分比骄傲容易区分的负样本,来减少搜索空间。
02
S T R
像Cascade RCNN这样的多步回归可以提高Bounding Box位置的准确性,特别是在一些具有挑战性的场景中,例如MS COCO风格的评估指标。然而,将多步回归应用于人脸检测任务中,如果不仔细考虑,可能会影响检测结果。
STR作用于高层Feature Map上,用来粗略调整anchor的尺度、位置(类似于RefineDet中ARM的回归任务),并进一步为高层Feature Map上的回归器提供refined后的anchor位置初始化(类似于RefineDet中ODM的回归任务)。
03
R F E
当前网络通常都具有square感受野,这影响了对不同高宽比目标的检测。为了解决这个问题,SRN设计了一个感受野增强(RFE),在预测类和位置之前,将特征的感受野多样化,这有助于在某些极端姿势中很好地捕捉到人脸。
改 进 说 明
Improved SRN基于SRN的改进,如数据增强、特征提取、训练策略等。
01
数据增广
使用SRN的原始数据增强策略,包括光照扭曲、通过零填充操作进行随机扩展、从图像中随机裁剪块,并调整块的大小到1024×1024。另外,在概率为0.5的情况下,利用PyramidBox中的data-anchor-sampling,随机选择图像中的一个人脸,并基于子图像进行定位。这些数据增强方法对于防止过度拟合和构造鲁棒模型至关重要。
02
特征提取
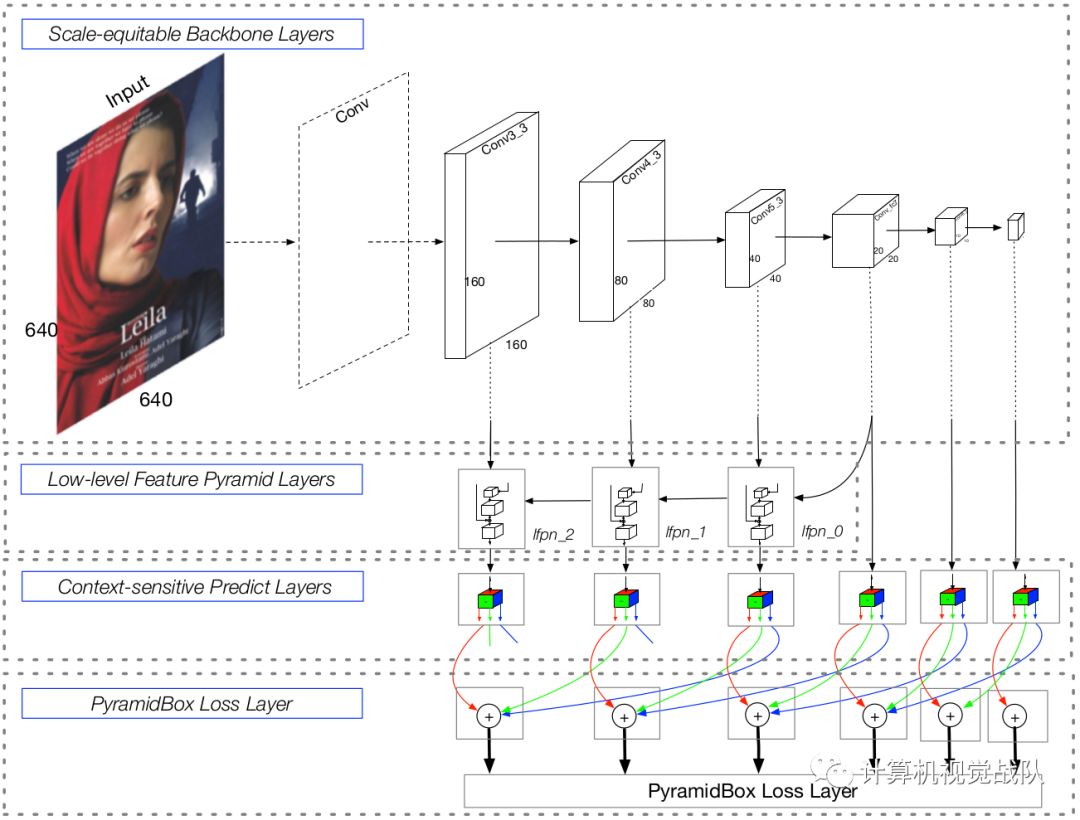
Wider Face内小尺度人脸特别多,SRN的主干网为:ResNet-50-FPN,可以进一步提升;ScratchDet提出了Root-ResNet,用于检测小尺度目标,但训练速度比原生态ResNet慢。

那么为了保证主干网性能好,训练速度快,Improved SRN融合了Root-ResNet+DRN的思路。
具体地,ResNet中第一个stride = 2的7 x 7 conv,丢失了很多图像的细节信息,对小尺度人脸检测不利,本次的改进如下图2,第一阶段的conv整体上stride = 1,channel = 16,而非64,并新增了2个residual blocks,一方面增强特征的表达能力,另一方面做下采样,通道数也少了很多;整体上就是,提特征能力强了,额外的计算开销也减少。
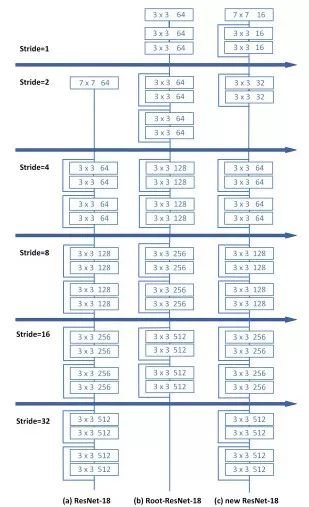
图2 网络结构图 (a)ResNet-18:原始结构,(b)Root-ResNet-18:用三层叠置的3×3卷积层取代7×7卷积层,并将步长2改为1,(c)New-ResNet-18:将DRN与Root-ResNet-18相结合,为SRN建立一个训练速度/精度折衷的网络骨干。
03
训练策略
由于RESNET-50-FPN主干网已经被修改,所以不能使用ImageNet预训练模型。一种解决方案是DRN,它在ImageNet数据集上训练修改后的主干,然后在更宽的面上进行细化。
然而,有人证明了ImageNet的预训练是不必要的。因此,将训练epoch翻了一番,达到260次,并从零开始用改进的骨干网络训练模型。从零开始训练的关键因素之一是标准化,由于输入量大(1024×1024),一个24G GPU只能输入5幅图像,导致批量归一化从零开始训练时效果不佳。为此,利用group=16的组规范化(Group Normalization )从零开始训练这个改进的ResNet-50骨干网。
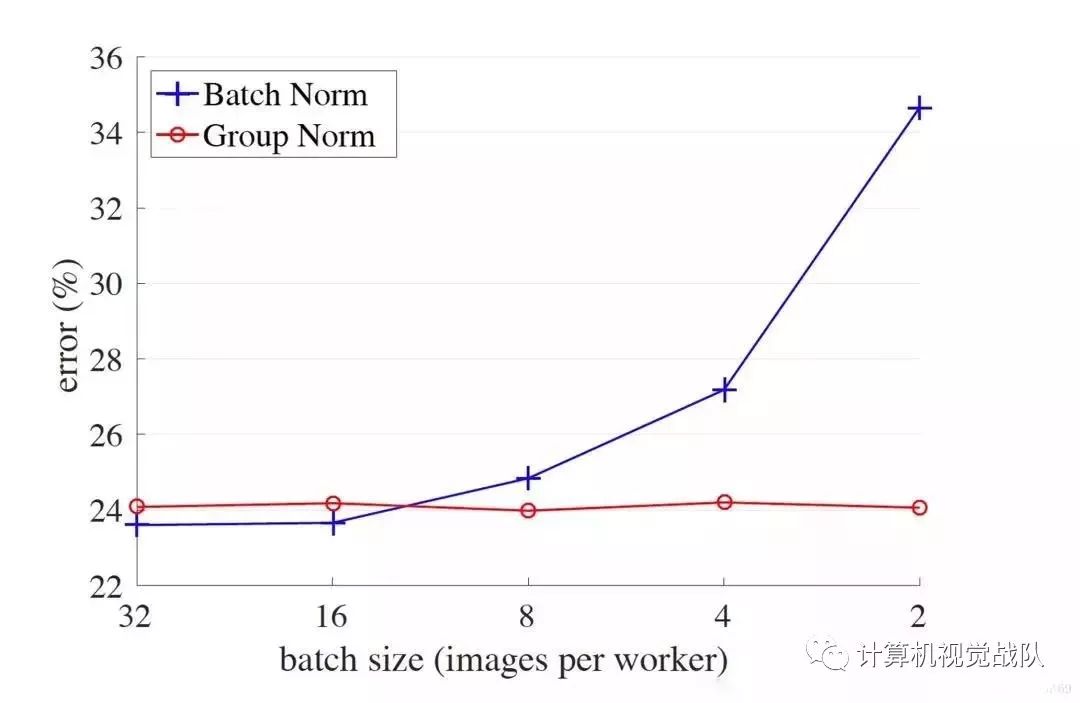
此外,最近的FA-RPN证明,人脸检测模型若先在MS COCO上训练一波,再在Wider Face上进一步训练,性能会更好,Improved SRN也使用了该方案。
总结:Improved SRN中,图2(c)中修改的主干网,不在ImageNet上预训练,而是直接把整个检测网络先在MS COCO上训练,再在Wider Face上进一步训练即可。
为什么MS COCO上训练后,效果会更好呢?
文中认为是MS COCO包含了people类,而且有特别多的小尺度目标,对模型性能提升是有帮助的。

图3 实验结果
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!



