Github项目推荐 | RecQ - Python推荐系统框架

【Python推荐系统框架(TensorFlow支持)】
RecQ: A Python Framework for Recommender Systems (TensorFlow Supported) by Coder-Yu
项目地址:(注:请点击文末【阅读原文】访问划线链接)
https://github.com/Coder-Yu/RecQ
最新消息
我们现在将RecQ转移到TensorFlow。 未来几周将提供基于GPU的版本。
10/09/2018 - 基于对抗训练的模型:APR已经实施。
10/02/2018 - 两个深度模型:DMF、CDAE已经实施。
07/12/2018 - TensorFlow支持的算法:BasicMF,PMF,SVD,EE(实现中......)
介绍
创建者: @Coder-Yu
主要贡献者:@DouTong @Niki666 @HuXiLiFeng @BigPowerZ @flyxu
由重庆大学软件工程学院发布
更多算法(基于排名和上下文感知)可以在我的另一个项目 Yue 中找到
RecQ 是用于推荐系统的Python库(Python 2.7.x)。 它实现了一系列最先进的建议。 为了轻松运行RecQ(无需逐个设置RecQ中使用的软件包),强烈建议使用领先的开放数据科学平台 Anaconda。 它集成了Python解释器,常见科学计算库(如Numpy,Pandas和Matplotlib)以及包管理器,所有这些都使它成为数据科学研究人员的完美工具。
RecQ的架构

特性
跨平台:作为Python软件,RecQ可以在任何平台上轻松部署和执行,包括MS Windows,Linux和Mac OS。
快速执行:RecQ基于快速的科学计算库,如Numpy和一些轻量级公共数据结构,使其运行速度比基于Python的其他库快得多。
轻松配置:RecQ配置推荐使用配置文件。
易于扩展:RecQ提供了一套精心设计的推荐接口,通过它可以轻松实现新算法。
数据可视化:RecQ可以在不运行任何算法的情况下帮助可视化输入数据集。
如何运行
1.将 **xx.conf** 文件配置在名为config的目录中。 (xx是你要运行的算法的名称)
2.运行项目中的 **main.py** ,然后在提示后输入。
如何配置
必选配置
| Entry - 输入 | Example - 示例 | Description - 描述 |
| ratings | D:/MovieLens/100K.txt | Set the path to input dataset. Format: each row separated by empty, tab or comma symbol. 设置输入数据集的路径。 格式:每行用空、制表符或逗号符号分隔。 |
| social | D:/MovieLens/trusts.txt | Set the path to input social dataset. Format: each row separated by empty, tab or comma symbol. 设置输入社交数据集的路径。 格式:每行用空、制表符或逗号分隔。 |
| ratings.setup | -columns 0 1 2 | -columns: (user, item, rating) columns of rating data are used (用户、项目、评级)使用评级数据列; -header: to skip the first head line when reading data 读取数据时跳过第一个头行 |
| social.setup | -columns 0 1 2 | -columns: (trustor, trustee, weight) columns of social data are used (委托方、受托方、权重)社交数据列; -header: to skip the first head line when reading data读取数据时跳过第一个头行 |
| recommender | UserKNN/ItemKNN/SlopeOne/etc. | Set the recommender to use. 设置推荐使用 |
| evaluation.setup | -testSet ../dataset/testset.txt | Main option(主要选项): -testSet, -ap, -cv -testSet path/to/test/file (need to specify the test set manually 需要手动指定测试集) -ap ratio ap比率(ap means that the ratings are automatically partitioned into training set and test set, the number is the ratio of test set. e.g. -ap 0.2 ap表示评级自动分为训练集和测试集,数字是测试集的比例。例如-ap 0.2) -cv k (-cv means cross validation, k is the number of the fold. e.g. -cv 5 -cv表示交叉验证,k是折叠的编号。例如-cv 5) Secondary option(次要选项):-b, -p, -cold -b val (binarizing the rating values. Ratings equal or greater than val will be changed into 1, and ratings lower than val will be changed into 0. e.g. -b 3.0 对评级值进行二值化。 等于或大于val的等级将变为1,低于val的等级将变为0。例如:-b 3.0) -p (if this option is added, the cross validation wll be executed parallelly, otherwise executed one by one 如果添加此选项,则交叉验证将并行执行,否则将逐个执行) -tf (model training would be conducted on TensorFlow if TensorFlow has been installed 如果已安装TensorFlow,将在TensorFlow上进行模型训练) -cold threshold 冷阈值 (evaluation on cold-start users, users in training set with ratings more than threshold will be removed from the test set 对冷启动用户的评估,评级超过阈值的训练集中的用户将从测试集中删除) |
| item.ranking | off -topN -1 | Main option: whether to do item ranking 主要选项:是否进行项目排名 -topN N1,N2,N3...: the length of the recommendation list. 推荐列表的长度。 *RecQ can generate multiple evaluation results for different N at the same time.* RecQ可以同时为不同的N生成多个评估结果 |
| output.setup | on -dir ./Results/ | Main option: whether to output recommendation results 主要选项:是否输出推荐结果 -dir path: the directory path of output results. 输出结果的目录路径。 |
基于内存的选项
| similarity - 相似 | pcc/cos | Set the similarity method to use. Options: PCC, COS; -设置要使用的相似性方法。 选项:PCC,COS; |
| num.shrinkage | 25 | Set the shrinkage parameter to devalue similarity value. -1: to disable simialrity shrinkage. -将收缩参数设置为贬值相似度值。 -1:禁用simialrity缩小。 |
| num.neighbors | 30 | Set the number of neighbors used for KNN-based algorithms such as UserKNN, ItemKNN. -设置用于基于KNN算法的邻居数,例如UserKNN,ItemKNN。 |
基于模型的选项
| num.factors | 5/10/20/number | Set the number of latent factors -设置潜在因素的数量 |
| num.max.iter | 100/200/number | Set the maximum number of iterations for iterative recommendation algorithms. -设置迭代推荐算法的最大迭代次数。 |
| learnRate | -init 0.01 -max 1 | -init initial learning rate for iterative recommendation algorithms 初始化迭代推荐算法的初始学习率; -max: maximum learning rate (default 1); 最大学习率(默认为1); |
| reg.lambda | -u 0.05 -i 0.05 -b 0.1 -s 0.1 | -u: user regularizaiton 用户正则化; -i: item regularization 项目正则化; -b: bias regularizaiton 偏倚正则化; -s: social regularization 社交正则化 |
如何扩展
1.让你的新算法泛化适当的基类。
2.根据需要重写以下一些函数。
readConfiguration()
printAlgorConfig()
initModel()
buildModel()
saveModel()
loadModel()
predict()
算法实现部分,请参阅项目查看
项目地址:https://github.com/Coder-Yu/RecQ
相关数据集
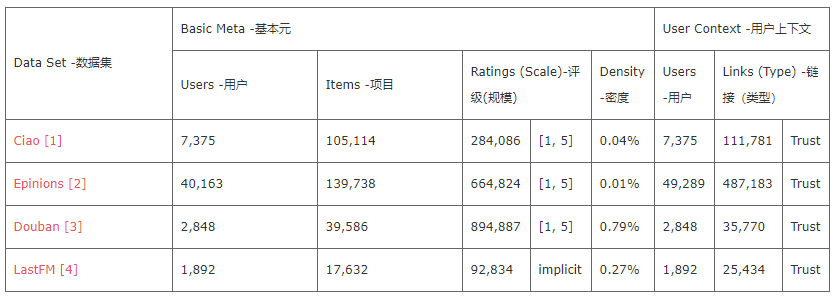
参考
[1]. Tang, J., Gao, H., Liu, H.: mtrust:discerning multi-faceted trust in a connected world. In: International Conference on Web Search and Web Data Mining, WSDM 2012, Seattle, Wa, Usa, February. pp. 93–102 (2012)
[2]. Massa, P., Avesani, P.: Trust-aware recommender systems. In: Proceedings of the 2007 ACM conference on Recommender systems. pp. 17–24. ACM (2007)
[3]. G. Zhao, X. Qian, and X. Xie, “User-service rating prediction by exploring social users’ rating behaviors,” IEEE Transactions on Multimedia, vol. 18, no. 3, pp. 496–506, 2016.
[4] Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2011. 2nd Workshop on Information Heterogeneity and Fusion in Recom- mender Systems (HetRec 2011). In Proceedings of the 5th ACM conference on Recommender systems (RecSys 2011). ACM, New York, NY, USA
【AI求职百题斩 - 每日一题】
赶紧来看看今天的题目吧!

想知道正确答案?
点击公众号菜单栏【每日一题】→【每日一题】或在公众号回复“0123”即可答题获取!
点击阅读原文,查看更多内容





