CS231n李飞飞CV课程辅导笔记(2):KNN

大家好,我是为人造的智能操碎了心的智能禅师。
计算机视觉,在人工智能领域的重要性,我想应该不用过多介绍了。
全球最大的专注于大数据分析、数据仓库和整合营销管理解决方案的供应商之一的Teradata, VP Atif Kureishy 预言人工智能的未来,是机器人和计算机视觉的双巨头时代。因为可供CV大展拳脚的领域,太多了。
计算机视觉领域,李飞飞的地位是毋庸置疑的。她在斯坦福的计算机视觉课程 CS231n,也成为学习计算机视觉的必看教材。

网易云课堂已经加上了中文字幕。大家可以点击文末阅读原文链接观看视频。
当然光看视频好像也还是缺点儿什么。于是禅师找到了一位“过来人”,分享他的课堂笔记,权当做课外辅导吧。大家可以看完视频后,回来看这些笔记。
全文大约2500字。读完可能需要2周时间

一个图像分类器如果用 Python 写出来的样子会是像这样的:

因此目标很简单,就是利用一系列的算法,把上面所谓的 magic processes 解开,最后实现目标识别的效果。传统的方式是我们人为的用很多条件约束去规范和描述一个物体属性的特征,然而这个方法既没办法普及,更没办法提升效率,因此我们使用“数据”去规范数据本身:
搜集图像里面的像素格和标签作为数据集里面的数据
用机器学习的技巧去训练分类器
使用新的图像资料去评估这个分类器的准确率
写出来的程式就像这个样子:
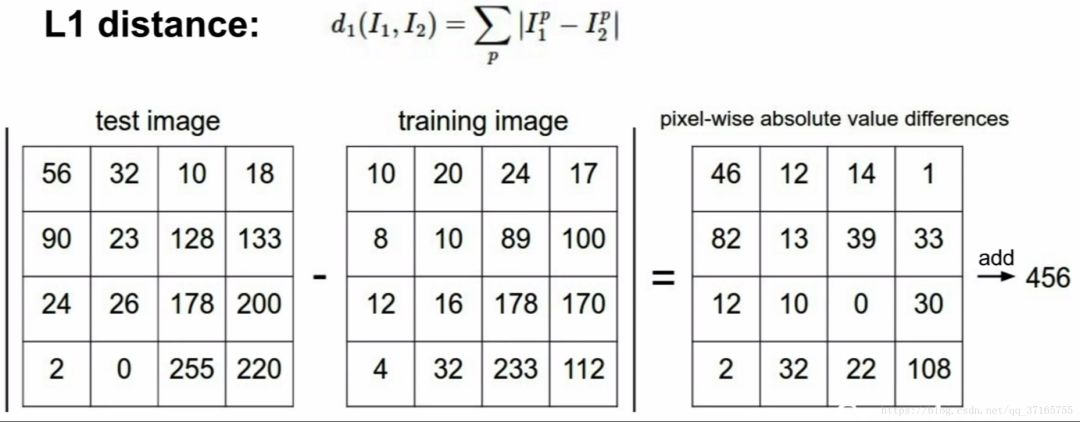
利用不同标尺之间的差值来比对图像

但是当我们在使用 K-Nearest 方法去辨识物体的时候,一般不挑临近只差“一个像素单位”的距离,距离比一还要大的话结果出来会更为平滑。不过这个方法到了现在已经没有被用在实际应用上了,其中的坏处很多,包含了:
计算时间特长
计算标尺与邻近特定距离标尺之间的关系并不会给我们带来什么太有用的讯息
这个方法就像以每个训练数据点为中心上放上一个对比图象,并用这个放上去的点的面积去分割原始图像,因此如果我们希望这个方法准确度高,放的点的“密度”就要足够大,不然就会失去这个方法的准确性

拿着张图当举例,虽然是同一个人的照片被动了不同的手脚,但是 K-Nearest Neighbor 结果出来的确实一样的。
有两个方法可以计算这个所谓“Distance Matrix”:
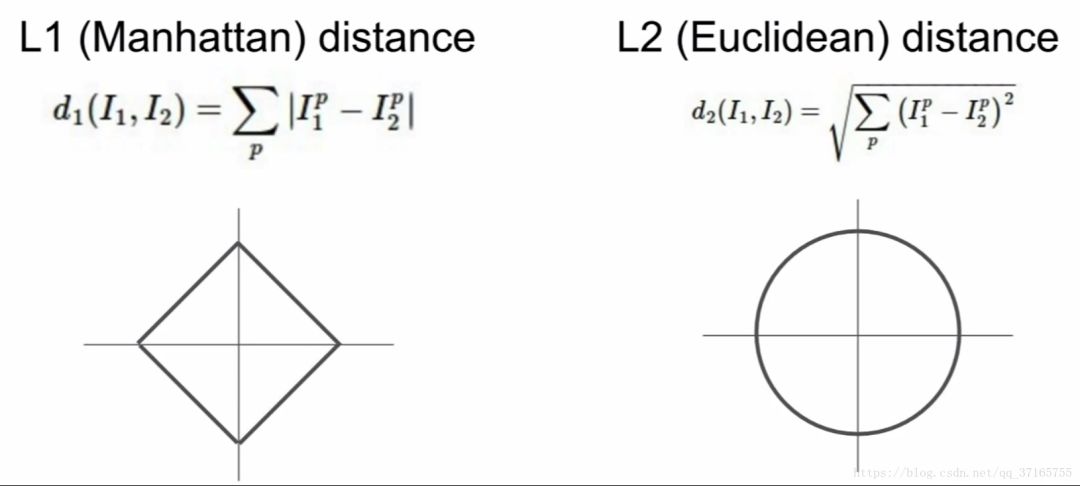
在 L1 的这个 case 里面,用这个方法判定的数据归类的边界会更趋向于贴近坐标系的轴来分割所属区域,而 L2 的话相对来说于坐标系的关联度没那么大,所以比较不会有这种情况。
Hyperparameter
在机器学习里面可能会有很多这种参数,他们不是通过重复的动作被“训练”出来的,而是根据设计者(我们人)的经验总结出来的一个可能会让整个效果更好的参数。因此我们一般设定他们之前会问自己两个问题:
什么样的 k 值能够被最好的使用得出最棒的结果(k 值指的是不同属性数据间最近的 k 个点的距离)
什么样的“步距”是最恰当的距离
以下几种方式可以设定 Hyperparameter(简称 HP)
找出一个 HP 是最为拟合已经有的数据的,有极高的准确率与重合性。但是结果显示,通常这样的结果都是过拟合的结果,在新来的数据面前,很难继续有好的拟合效果。e.g. 一个人被认定为有眼睛鼻子嘴巴的特征,过拟合白话地说就是机器“太较真”了,只认定展示给他看有眼睛鼻子嘴巴的那才是个人,今天来了个眼睛被头发遮住的人,于是机器就说这不是人,显然他过拟合了
把一大块数据分成训练用的和测试用的两部分,找出在训练中表现最好的 HP ,然后把这个结果套到测试集里面。但是一般而言这个结果也不怎么好,因为训练出来的 model 我们最主要关心的是它面向新的 data 时的表现,现有的只是一个我们用来预测的依据与手段
把一大块数据分成三份:训练,验证,测试。在训练集中找出最恰当的 HP,然后放到验证集做进一步确认与修改,最后得出的结果放到测试集去跑分看成绩。现实上这是一个比较好的解决方案
交叉验证法(也是最有公信力,准确性的一种方法),但是不适用于深度学习框架,因为数据量太大了。把整块数据分成若干份留一块给测试集,然后随机取一块作为验证集,剩下的 n-2 块全部作为训练集找最好的 HP,找到后放到验证集去,剩下的步骤如第三种方法,最后等所有的块都当过验证集后,把所有结果取平均得到最后的结果。虽然这个结果准确,但是耗费太大的计算资源,是个只有理论上可行的方法
K-Nearest Neighbors 方法总结
图像分类器的建立过程中,我们从图片训练集与标签开始,预测测试集的图像该是什么样子
他预测的方法是根据邻近的训练样本
标尺的距离与 k 值都是一种 Hyperparameters
从验证集中被测试好的 HP只在最后放到测试集测试一次
线性分类器 Linear Classification
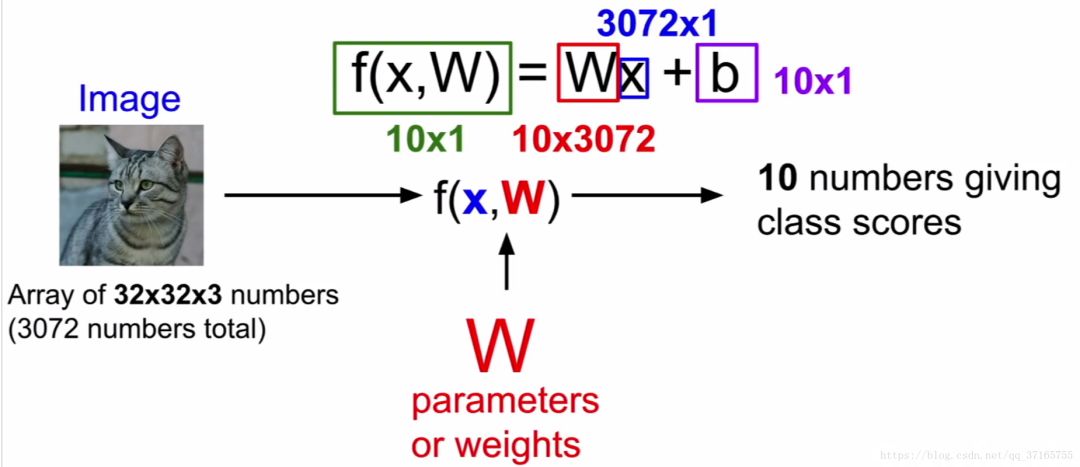
这就是现在主流被广泛应用到 CNN的方法, f(x, W) = Wx + b。 一个图像信息被看作是一个“图片的长”“图片的宽”“光的三原色的量”的三维矩阵,每一个像素点作为一个信号源放入到 x 的位置,经过一个权重 W 把 x 的重要性凸显出来,加上一个独立的修正量 b ,最后得出一个值用来评分。就像下面这张图所显示的意思。
然而,线性分类器在一个类别里面只能学习一个模板,例如一个类是用来分辨汽车的,就不能再训练它来分辨动物。如果这种情况出现的话,那新加入的动物图像数据就会和已有的汽车数据宗和起来,最后得出一个他们共同的四不像答案,一般来说是不好的。
缺点
当遇到高维度向量的时候,线性分类器就会失去原有厉害的分类魔力。
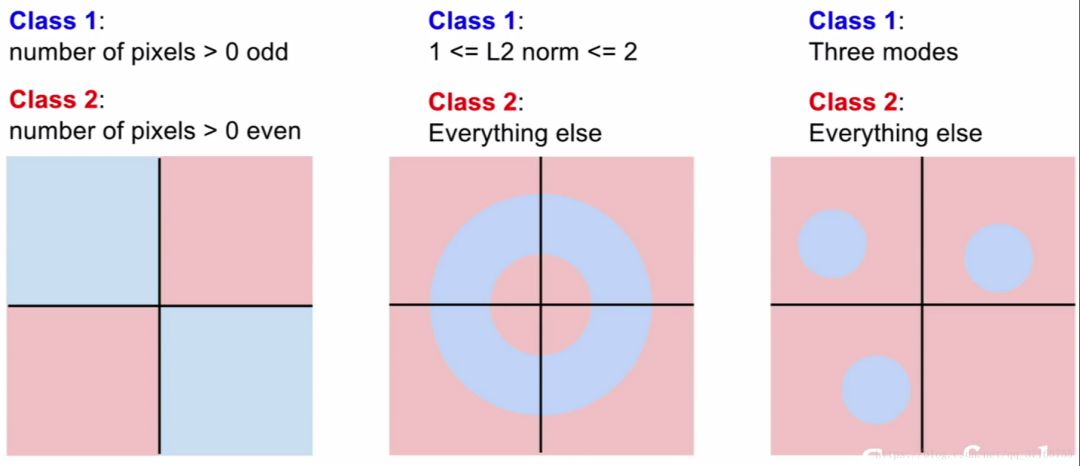
每次只要遇到可以分布在不同区域的数据的时候,例如上面的例子,没有一张图里面的数据分布是可以靠直接用一条线切开左右两边数据达到分类效果的,那么线性分类器就会陷入难题。






