【实践】BiLSTM上的CRF,用命名实体识别任务来解释CRF(1)
作者:CreateMoMo
编译:ronghuaiyang
看了许多的CRF的介绍和讲解,这个感觉是最清楚的,结合实际的应用场景,让你了解CRF的用处和用法。
该系列文章将包括:
-
介绍 — 在BiLSTM顶层上使用CRF层用于命名实体识别任务的总体思想 -
详细的例子 — 一个例子,解释CRF层是如何逐步工作的 -
Chainer实现 — CRF层的Chainer实现
预备知识
你需要知道的惟一的事情是什么是命名实体识别。如果你不知道神经网络,CRF或任何其他相关知识,请不要担心。我会尽可能直观地解释一切。
1. 介绍
对于命名实体识别任务,基于神经网络的方法非常普遍。例如,这篇文章:https://arxiv.org/abs/1603.01360提出了一个使用词和字嵌入的BiLSTM-CRF命名实体识别模型。我将以本文中的模型为例来解释CRF层是如何工作的。
如果你不知道BiLSTM和CRF的细节,请记住它们是命名实体识别模型中的两个不同的层。
1.1 开始之前
我们假设,我们有一个数据集,其中有两个实体类型,Person和Organization。但是,事实上,在我们的数据集中,我们有5个实体标签:
-
B-Person -
I- Person -
B-Organization -
I-Organization -
O
此外,x是一个包含5个单词的句子,w0,w1,w2,w3,w4。更重要的是,在句子x中,[w0,w1]是一个Person实体,[w3]是一个Organization实体,其他都是“O”。
1.2 BiLSTM-CRF模型
我将对这个模型做一个简单的介绍。
如下图所示:
-
首先,将句子x中的每个单词表示为一个向量,其中包括单词的嵌入和字符的嵌入。字符嵌入是随机初始化的。词嵌入通常是从一个预先训练的词嵌入文件导入的。所有的嵌入将在训练过程中进行微调。 -
第二,BiLSTM-CRF模型的输入是这些嵌入,输出是句子x中的单词的预测标签。
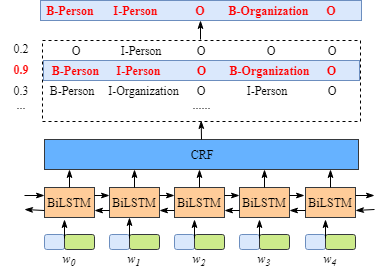
虽然不需要知道BiLSTM层的细节,但是为了更容易的理解CRF层,我们需要知道BiLSTM层输出的意义是什么。
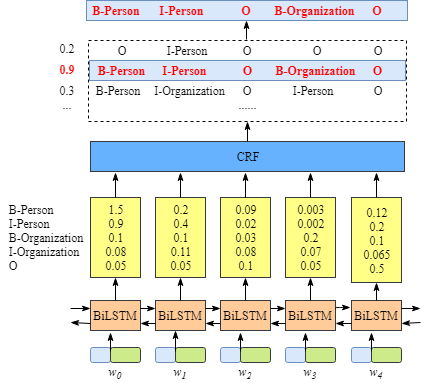
上图说明BiLSTM层的输出是每个标签的分数。例如,对于w0, BiLSTM节点的输出为1.5 (B-Person)、0.9 (I-Person)、0.1 (B-Organization)、0.08 (I-Organization)和0.05 (O),这些分数将作为CRF层的输入。
然后,将BiLSTM层预测的所有分数输入CRF层。在CRF层中,选择预测得分最高的标签序列作为最佳答案。
1.3 如果没有CRF层会怎么样
你可能已经发现,即使没有CRF层,也就是说,我们可以训练一个BiLSTM命名实体识别模型,如下图所示。
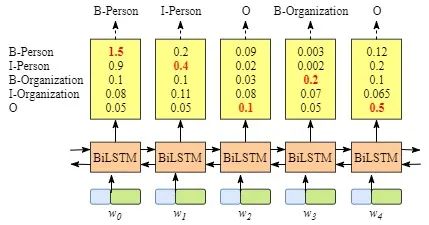
因为每个单词的BiLSTM的输出是标签分数。我们可以选择每个单词得分最高的标签。
例如,对于w0,“B-Person”得分最高(1.5),因此我们可以选择“B-Person”作为其最佳预测标签。同样,我们可以为w1选择“I-Person”,为w2选择“O”,为w3选择“B-Organization”,为w4选择“O”。
虽然在这个例子中我们可以得到正确的句子x的标签,但是并不总是这样。再试一下下面图片中的例子。
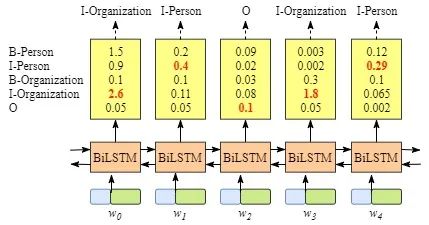
显然,这次的输出是无效的,“I-Organization I-Person”和“B-Organization I-Person”。
1.4 CRF层可以从训练数据中学到约束
CRF层可以向最终的预测标签添加一些约束,以确保它们是有效的。这些约束可以由CRF层在训练过程中从训练数据集自动学习。
约束条件可以是:
-
句子中第一个单词的标签应该以“B-”或“O”开头,而不是“I-” -
“B-label1 I-label2 I-label3 I-…”,在这个模式中,label1、label2、label3…应该是相同的命名实体标签。例如,“B-Person I-Person”是有效的,但是“B-Person I-Organization”是无效的。 -
“O I-label”无效。一个命名实体的第一个标签应该以“B-”而不是“I-”开头,换句话说,有效的模式应该是“O B-label” -
…
有了这些有用的约束,无效预测标签序列的数量将显著减少。
后续
在下一节中,我将分析CRF损失函数,以解释CRF层如何或为什么能够从训练数据集中学习上述约束。

英文原文:https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/







