专栏 | Bi-LSTM+CRF在文本序列标注中的应用
机器之心专栏
作者:触宝AI实验室Principal Engineer董冰峰
传统 CRF 中的输入 X 向量一般是 word 的 one-hot 形式,前面提到这种形式的输入损失了很多词语的语义信息。有了词嵌入方法之后,词向量形式的词表征一般效果比 one-hot 表示的特征要好。本文先主要介绍了LSTM、词嵌入与条件随机场,然后再从序列标注问题探讨 BiLSTM与CRF等的应用。
Word Embedding 和 LSTM
Word Embedding 简单的说是将高维空间(空间的维度通常是词典的大小)中的表示 word 的高维 one-hot 向量映射到低维(几十维)连续空间中的向量,映射后的向量称为词向量。
词向量可以包含很多 word 中的语义信息,有一些奇妙的性质,例如:v(queen)-v(king)=v(woman)-v(man)(用 v(x) 表示 word x 的词向量,参见图 1);不过 word embedding 更多地还是应用在 DNN 中作为高维离散特征的预处理(本应用中即是如此)。
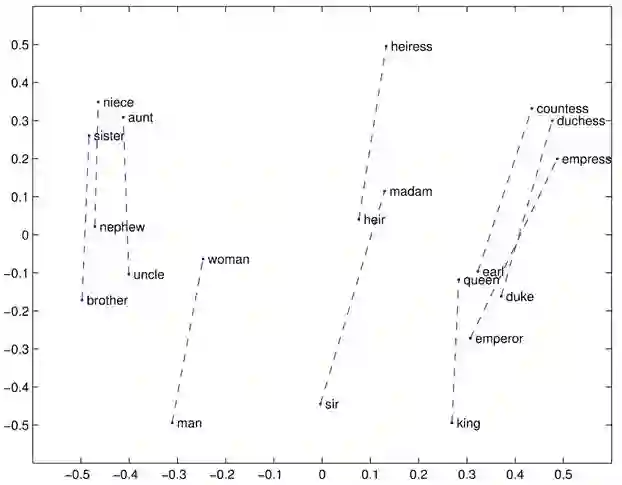
图 1 在二维空间中的一些词向量
词向量的详细说明和算法可以参考这篇文章:http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
LSTM(Long Short Term Memory),是一种特殊类型的 RNN(循环神经网络),能够学习长期的依赖关系。它由 Sepp Hochreiter 和 Jürgen Schmidhuber 在 1997 年提出,并加以完善与普及,LSTM 在各类任务上表现良好,因此在处理序列数据时被广泛使用。
一个典型的 LSTM 链具有如图 2 中的结构:
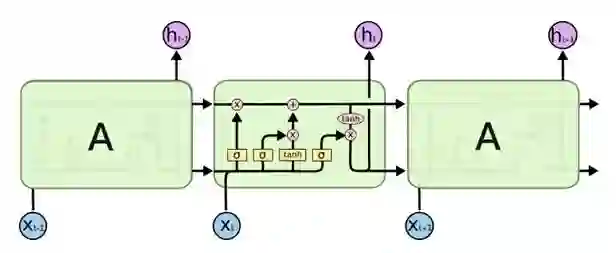
图 2 LSTM 网络结构,其中,X 表示输入的序列,h 表示输出。
LSTMs 的核心所在是 cell 的状态(cell state),也就是图 2 中上面的这条向右的线。Cell 的状态就像是传送带,它的状态会沿着整条链条传送,而只有少数地方有一些线性交互。信息如果以这样的方式传递,实际上会保持不变。LSTM 通过一种名为「门」(gate)的结构控制 cell 的状态,并向其中删减或增加信息。一个 LSTM 有三个这样的门:遗忘门,输入门和输出门,控制 cell 的状态。
以语言模型来举例:cell 的状态可能会需要考虑主语的性别,这样才能找到正确的代词。因此如果我们设定,如果看到了一个新的主语,「遗忘门」就用来忘记旧的主语所代表的性别。然后我们利用「输入门」将新主语的性别信息加入 cell 的状态中,以替换要忘记的旧信息。最后,我们需要确定输出的内容,当它只看到一个主语时,就可能会输出与动词相关的信息。比如它会输出主语是单数还是复数。这样的话,如果后面真的出现了动词,我们就可以确定它的形式了。
LSTM 相关的资料可以参考:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
如果能像访问过去的上下文信息一样,访问未来的上下文,这样对于许多序列标注任务是非常有益的。例如,在序列标注的时候,如果能像知道这个词之前的词一样,知道将要来的词,这将非常有帮助。
双向循环神经网络(Bi-LSTM)的基本思想是提出每一个训练序列向前和向后分别是两个 LSTM,而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。图 3 展示的是一个沿着时间展开的 Bi-LSTM。
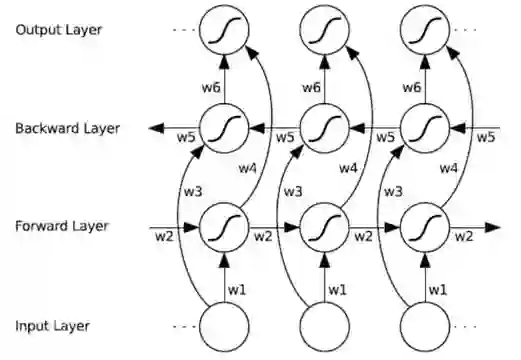
图 3 Bi-LSTM 示意图
CRF(条件随机场)
为了理解条件随机场,需要先解释几个概念:概率图模型、马尔科夫随机场。
概率图模型(Graphical Models):图是由结点及连接结点的边组成的集合,结点和边分别记作 v 和 e,结点和边的集合分别记作 V 和 E,图记作 G=(V,E),无向图是指边没有方向的图。概率图模型是由图表示的概率分布。设联合概率分布 P(Y), 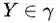
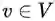
成对马尔可夫性(Pairwise Markov):设 u 和 v 是无向图 G 中任意两个没有边连接的结点,结点 u 和 v 分别对于随机变量 Y_u 和 Y_v。成对马尔可夫性是指给定随机变量组 Y_o 的条件下随机变量 Y_u 和 Y_v 是条件独立的,即:
图 4 成对马尔可夫性
局部马尔可夫性(Local Markov):设 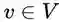
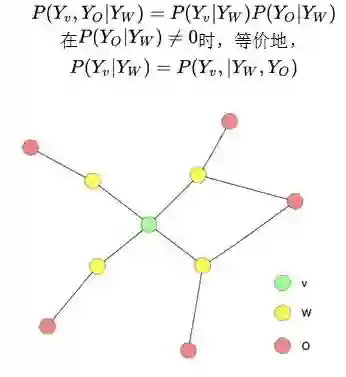
图 5 局部马尔可夫性
全局马尔可夫性(Local Markov):设结点集合 A,B 是在无向图 G 中被结点集合 C 分开的任意结点集合,结点集合 A,B 和 C 所对应的随机变量组分别是 Y_A、Y_B 和 Y_C。全局马尔可夫性是指给定随机变量组Y_C条件下随机变量组 Y_A、Y_B 是条件独立的,即
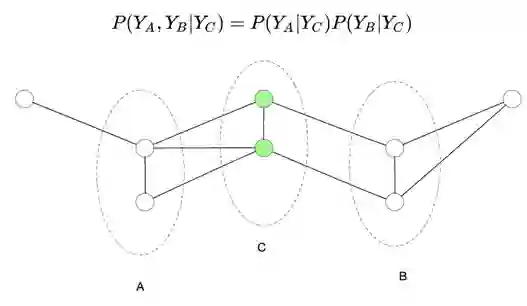
图 6 全局马尔可夫性
全局马尔可夫性,局部马尔可夫性和成对马尔可夫性三个性质可以证明是等价的。
马尔科夫随机场(Markov Random Field / MRF):设有联合概率分布 P(Y),由无向图 G=(V,E) 表示,在图 G 中,结点表示随机变量,边表示随机变量之间的依赖关系,如果联合概率分布 P(Y) 满足成对、局部或全局马尔可夫性,就称此联合概率分布为马尔可夫随机场。
团(clique):无向图 G 中任何两个结点均有边连接的结点子集称为团。若 C 是无向图 G 的一个团,并且不能再加进任何一个 G 的结点使其成为一个更大的团,则称此 C 为最大团。
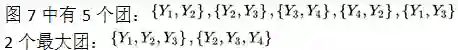
引入概率无向图的一个重要作用是可以将概率无向图表示的联合概率分布拆分成每个团的联合概率分布的乘积:
Hammersley-Clifford 定理:概率无向图模型的联合概率分布 P(Y) 可以表示为如下形式:
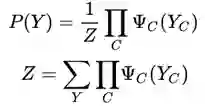
其中,C 是无向图的团,Y_C 是 C 的结点对应的随机变量,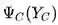
我们通常将势函数写成如下形式:
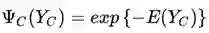
其中 E(Y_c) 成为团 C 的能量函数,受热力学中玻尔兹曼分布的「能量越小的状态概率越大」的性质启发而来。
进一步地,我们对团 C 的能量函数 E(Y_c) 进行建模,认为它是由 C 中的各个随机变量 Y_c 的一系列函数 f_k(Y_c) 的线性组合而来:
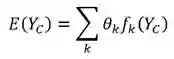
而 f_k(Y_c) 称为特征函数。
条件随机场(Conditional Random Fields)是给定一组输入随机变量条件下,另外一组输出随机变量的条件概率分布模型,其特点是假设输出变量构成马尔可夫随机场。
可以简单的将上面各个表达式中的 Y 替换为 Y|X,于是我们有:
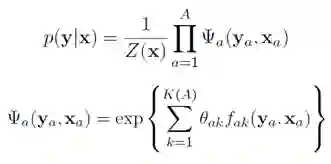
条件随机场可以用在不同的预测问题中,本文只讨论它在标注问题的应用。因此主要讲述线性链条件随机场(Linear Chain CRFs),对应的概率图 8 所示:
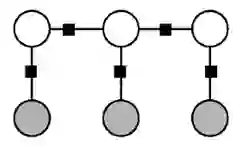
图 8 线性链条件随机场
其中白色节点表示输出随机变量 Y,灰色节点表示输入随机变量 X。在线性链条件随机场中,每个输出变量仅与相邻的两个输出变量以及输入变量 X 之间存在依赖关系。这个时候,我们可以将一般的 CRF 模型简化为:
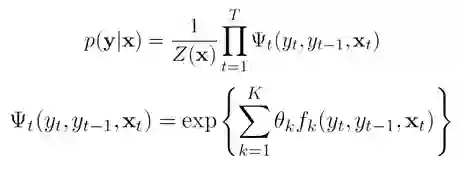
序列标注问题
这里的序列标注问题是将序列中出现的不同种类的命名实体(人名,地名,组织名)标记出来,例如:
John(B-PER) lives(O) in(O) New(B-LOC) York(I-LOC) and(O) works(O) for(O) the(O) European(B-ORG) Union(I-ORG).
括号中的内容是标注:PER 表示人名,LOC 表示地名,ORG 表示组织名称,O 表示非命名实体,B-X 表示命名实体的第一个词(B-PER 表示人名的第一个单词),I-X 表示命名实体第二个以后的词。
解决命名实体标注问题的一个简单的方法是将所有的这些命名实体都预先存在一个列表里面,然后将序列中出现的每个子序列从列表中匹配即可。这种方法的一个最大的问题是对于列表中没有的命名实体就无法进行识别。我们可以想象一下人类做命名实体识别的过程:除了用到先验的知识(New York 是地名),还会对没有先验知识的词根据上下文做出推测,比如上面的例子中如果我们不知道 European Union 是什么,可以根据首字母大写判断它可能是一个专名,然后结合前面的 works for 推测出它可能是一个机构名称。
序列标注模型
为了让机器达到这一目标,我们可以分以下几个步骤进行:
词向量表示:用低维连续空间的向量表示单个词。我们可以用训练好的 word embedding,还可以把词拆成单个字母的形式,这是由于两个原因:一是很多的专名很少出现,并没有对应的 word embedding,二是首字母大写的词可能会帮助我们判别专名(形态信息)。
上下文向量表示:每一个词的上下文需要用一个低维连续空间的向量表示,这里我们将会用到 LSTM。
命名实体标注:用词向量和上下文向量来得到预测的标注的结果。
词向量表示
首先将单个 word 拆分成单个字母组成的序列,并使用 Bi-LSTM 生成词向量 W(char),网络的结构如图 9 所示:
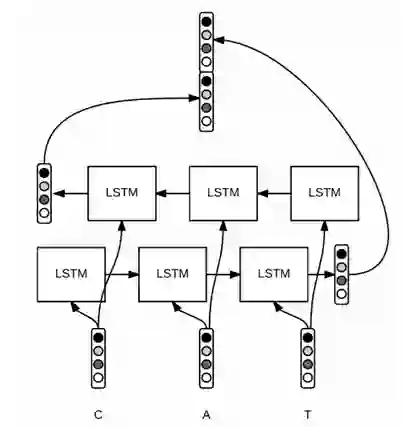
图 9 字符序列生成 word embedding
然后可以用基于 word 的 embedding 算法(例如 GloVe,CBOW 等)生成词向量 W(glove)。
将两个词向量拼接起来 W=[W(glove), W(char)],这样的词向量中包含了 word 的语义和形态信息。
上下文向量表示
我们用另一个 Bi-LSTM 来生成词在上下文中的向量表示,网络结构如图 10 表示。
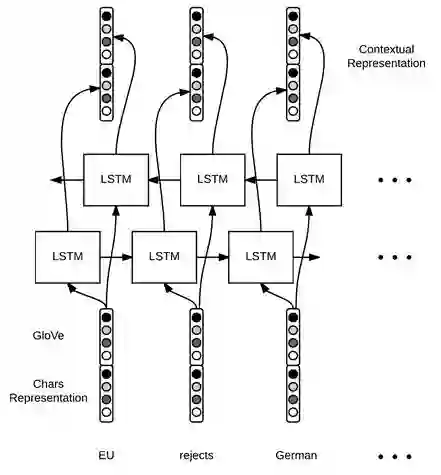
图 10 生成 word 在上下文中的向量表示
命名实体标注
对于给定的长度为 m 的序列 X,假设标注的结果为 [y1, …, ym],yi=PER/LOC/ORG/O,则命名实体标注问题可以表示在已知序列 X 的条件下,找出使得 [y1, …, ym] 的概率 P(y1, …, ym) 最大的序列 [Y1, …, Ym]。
这个问题适合用线性链条件随机场建立模型:
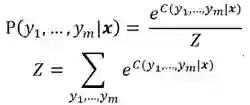
结合前面模型的一般形式,我们定义该问题的能量函数如下:
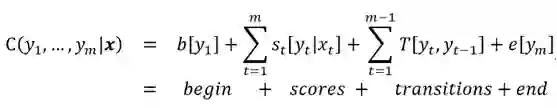
b[y_1]表示序列首位是标签 y1 的 score; e[y_m]表示序列末位是标签 y_m 的 score,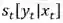
以上的四项也比较清楚的描述了在进行标注时我们考虑的几个因素:当前词相关信息及该标签出现的位置信息。
标注序列 y 的最优解 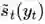
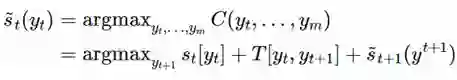
可以用 Viterbi 算法(动态规划)求解最优的标注序列。
Bi-LSTM 结合 CRF
传统的 CRF 中的输入 X 向量一般是 word 的 one-hot 形式,前面提到这种形式的输入损失了很多词语的语义信息。有了 word embedding 方法之后,词向量形式的 word 表示一般效果比 one-hot 表示的特征要好。
在本应用中,CRF 模型能量函数中的 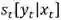
Tensorflow 中的 CRF 实现
在 tensorflow 中已经有 CRF 的 package 可以直接调用,示例代码如下(具体可以参考 tensorflow 的官方文档 https://www.tensorflow.org/api_docs/python/tf/contrib/crf):
labels= tf.placeholder(tf.int32, shape=[None, None], name="labels")
log_likelihood,transition_params = tf.contrib.crf.crf_log_likelihood(
scores, labels, sequence_lengths)
loss= tf.reduce_mean(-log_likelihood)
参考资料
Sutton, Charles, and Andrew McCallum. "An introduction to conditional random fields." Machine Learning 4.4 (2011): 267-373
https://zhuanlan.zhihu.com/p/30606513
https://guillaumegenthial.github.io/sequence-tagging-with-tensorflow.html
http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/
https://zhuanlan.zhihu.com/p/28343520
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


