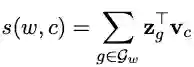先说结论,fastText 在不同语境中至少有两个含义: 1. 在文章 Bag of Tricks for Efficient Text Classification [1] 中,fastText 是作者提出的文本分类器的名字。与 sub-word 无关!也不是新的词嵌入训练模型!是 word2vec 中 CBOW 模型的简单变种。 2. 作为 Facebook 开源包,fastText [6] 是用来训练词嵌入或句嵌入的,其不仅包括 1 中论文的代码实现,还包括 Enriching Word Vectors with Subword Information[2] 及 FastText.zip: Compressing text classification models[3] 两文的代码实现。 本来觉得这些含义区别不重要,直到连我自己都被弄迷糊了。在写这篇解读前,我心中的 fastText 一直是第三种含义:用 sub-word 信息加强词嵌入训练,解决 OOV(Out-Of-Vocabulary)表征的方法。结果带着这个预先的理解读 Bag of Tricks for Efficient Text Classification,越读越迷惑。 为理清思路,第一小节我们就先讲讲 Bag of Tricks for Efficient Text Classification 中的 fastText,第二小节则围绕 Enriching Word Vectors with Subword Information。
如果没有重新读这篇文章,我也会下意识地往 character 级别想,但是必须要在此强调:这篇文章和 character 没有任何关系!文章中的 n-gram 出自 Character-level Convolutional Networks for Text Classification[4],是 word 级别的。与我在 word2vec 中提到的 phrases 类似。 在此梳理几个概念:
[1] Bag of Tricks for Efficient Text Classification https://arxiv.org/pdf/1607.01759.pdf [2] Enriching Word Vectors with Subword Information https://arxiv.org/pdf/1607.04606.pdf [3] FastText.zip: Compressing text classification models https://arxiv.org/pdf/1612.03651.pdf [4] Character-level Convolutional Networks for Text Classification https://papers.nips.cc/paper/5782-character-level-convolutional-networks-for-text-classification.pdf [5] FastText.zip: Compressing text classification models https://arxiv.org/abs/1612.03651 [6] https://fasttext.cc [7] Enriching Word Vectors with Subword Information https://www.aclweb.org/anthology/Q17-1010.pdf