SIGIR2022 | SimGCL: 面向推荐系统的极简图对比学习方法

论文:https://arxiv.org/abs/2112.08679
代码:https://github.com/Coder-Yu/QRec
Highlight
本文最大贡献在于通过实验证明了,面向推荐的图对比学习中,图增强不是必须的。而对比学习对于推荐效果的提升主要来自于学习到更均匀的表征分布。基于此,本文提出了一个极简的图对比学习方法,在推荐性能,训练/收敛速度以及去偏能力等多个方面具有非常好的性能。
1. 引言
对比学习作为当下的热点技术被广泛用于推荐系统以缓解数据稀疏问题。一种典型的对比学习流程为:首先对原始的用户-商品二部图进行结构扰动(以一定概率随机丢弃节点/边)以获得图增强 (graph augmentation),然后训练图模型最大化不同graph augmentations之间的互信息,以此提升模型的泛化能力(见图1)。尽管这种基于dropout的对比学习范式被证明是有效的,但其有效的原因尚不明确。直觉上,我们认为通过对比不同的graph augmentations,模型可以提炼原始图的本质信息。然而,一系列最近的工作发现,即便非常稀疏的graph augmentations仍然能为模型带来不错的性能提升。这一现象非常出乎意料,因为一个高度稀疏的graph augmentation与原始图的语义已经相去甚远。由此引出一个问题,对于基于对比学习的推荐模型来说,graph augmentations真的是不可或缺的吗?
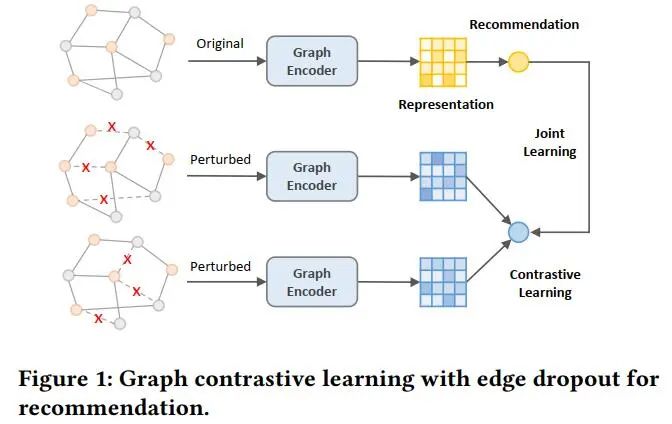
在本文中,作者首先通过实验验证了:不论使用或不使用图增强,对比学习都能带来相当的性能提升。通过将学习到的embedding可视化,作者发现:对于基于对比学习的图推荐模型来说,对比损失函数才是性能提升的关键点,而图增强只起到了次要的作用的。优化InfoNCE这一对比学习损失函数,会让学习到的用户与商品表征分布更加均匀,间接的起到了去除流行性偏差的效果。与此同时,作者认为,基于dropout的图增强构造耗时且有一定几率丢弃关键边/节点,造成极大语义偏离。基于此,作者提出了一种简单高效的面向推荐的图对比学习方法。即,放弃基于结构扰动的图增强,转而向学习到的embedding添加均匀随机噪声来获得表征层面的数据增强。由于添加的噪声粒度是可控的,该方法可以构造与原始表征不同的embedding,同时保留原始表征中可学习的信息。与图增强相比,该方法实现了平滑的调节学习到的表征的均匀性,并且对于模型性能提升更加有效。
2. 推荐中的图对比学习调查
本文作者在这一部分首先调查了一种经典图对比学习方法SGL(论文:Self-Supervised Graph Learning for Recommendation)的各种变体对于推荐效果的提升。在表1中,作者报告了四种变体SGL-ND(node dropout),SGL-ED(edge dropout),SGL_RW(Random Walk), SGL-WA (without augmentations),backbone模型LightGCN以及只优化对比学习损失(CL Only)的结果。可以看出,在不使用图增强的情况下(SGL-WA),其模型性能甚至好于基于node dropout和random walk的图增强,跟最佳的SGL-ED非常接近。
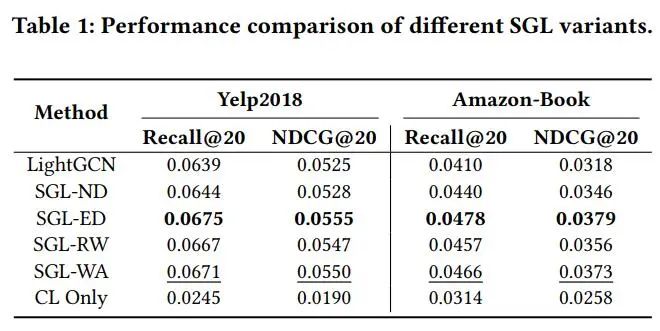
作者接下来利用t-SNE可视化几种方法学习到的用户embedding(图2),发现作为backbone的LightGCN学习到的embedding呈现出簇的特征,而相比之下,各种SGL的变体学习到的embedding的分布会均匀很多,只优化InfoNCE损失则几乎学习到完全均匀的分布。作者认为,图模型中的消息传递机制以及推荐数据中的商品流行性偏差导致了LightGCN的呈现簇特征的embedding分布,而SGL优于LightGCN的主要原因在于优化对比损失函数可以学习到更均匀的分布,缓解流行性偏差,提升模型的泛化能力。结合表1和图2,可以得出,基于dropout的图增强并非性能提升的决定因素,在不使用的情况下,对模型性能影响很小。由此得出,其并非图对比学习所不可获取的。
3. SimGCL: 面向推荐的简单对比学习方法
基于第二章的结论,作者认为通过调节学习到的表征的分布的均匀性,可以使模型达到更佳的性能。由此,作者提出了一种非常简单的对比学习方法SimGCL. 其数据增强公式如下,
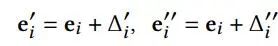
对于给定的节点表征e_i, SimGCL通过向表征添加均匀噪声的方法实现数据增强。噪声向量delta满足以下两个约束。
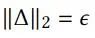
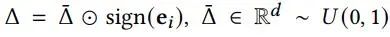
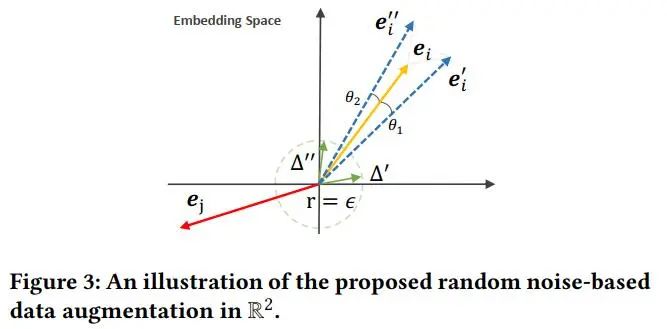
第一个约束控制了噪声的粒度,其等价于以epsilon为半径的超球面上的向量。半径越小,噪声的粒度越小。第二个约束是的噪声向量和原始表征位于同一超象限,以避免添加噪声造成过大的语义偏离。通过添加噪声,可以看作是使得原始表征向量在空间上旋转了两个小的角度,当旋转角度较小时,既保留了大部分原始信息,又带来了语义上的不同 (见图3)。
在SimGCL中,作者依然采用了LightGCN作为backbone。在每一层,不同的随机噪声将加到学习到的embedding,公式如下:
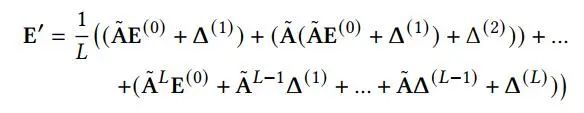
作者认为,通过调节噪声半径epsilon的大小,可以平滑的调节表征的分布均匀性,并用实验证明了其可行性。作者在yelp2018数据集上随机抽取了5000用户以及所有交互超过200的流行项目,通过如下公式计算分布的均匀性。
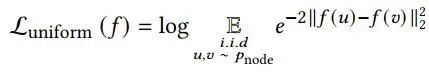
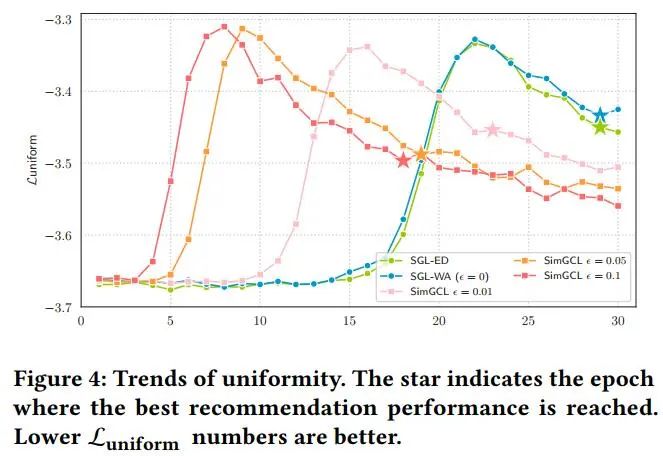
在图4中,可以看出,在最后收敛时,SimGCL学习到的表征均匀性高于SGL的两个变体,并且越大的噪声半径带来了越高的均匀性。
4. 实验
本文中作者做了大量的实验验证了SimGCL在各方面的性能,包括推荐准确性,收敛速度,运行速度,去偏能力,不同噪声类型的影响,以及与其他基于自监督学习的方法的比较。在此主要呈递部分实验结果。
首先是与SGL变体在三个数据集上的的性能全面比较,训练主要参数均保持一致。详细设置见论文。
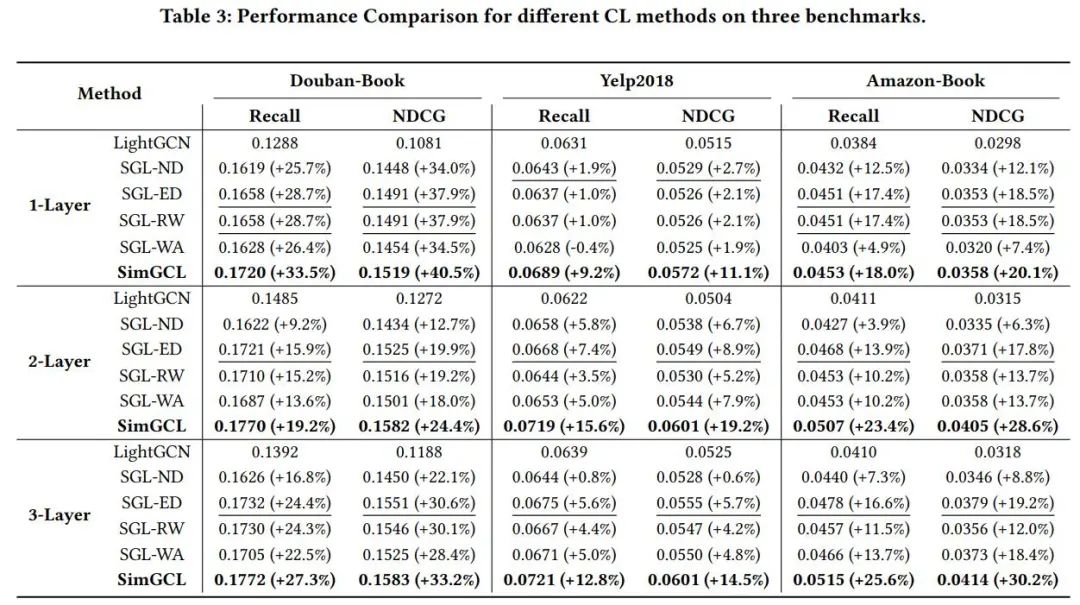
由上表可以看出,SimGCL的性能大大好于SGL。
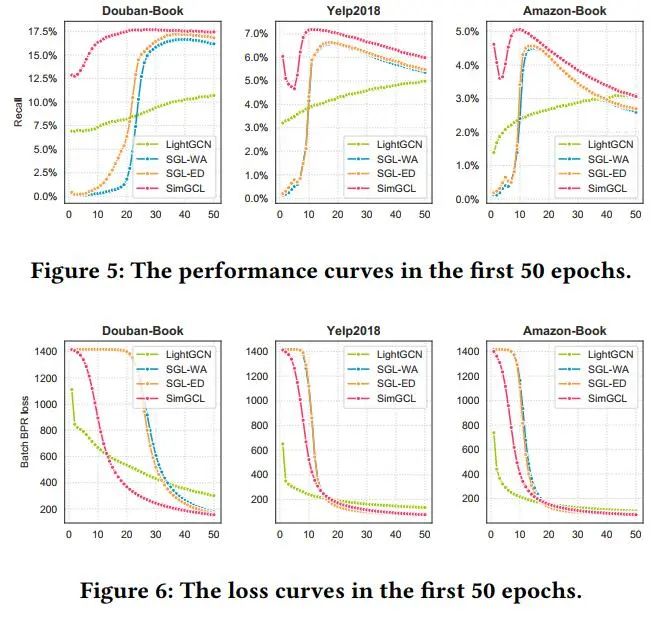
然后作者做了收敛性对比实验,由下图可知,SimGCL只需SGL所需的2/3迭代次数即可收敛,LightGCN收敛速度较慢。
另外,作者汇报了多个模型的每一次迭代实际运行时间,如下表。
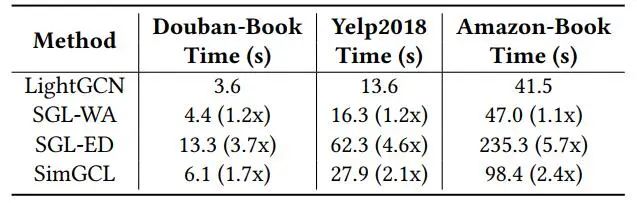
由于省去了图增强,SimGCL所需时间远少于SGL。
为了证明对比学习的去偏作用,作者将所有项目划分为三组:非流行项目(交互数排名后80%),流行项目(交互数排名前5%),普通项目(交互数居中),并做了在各组项目上的召回实验。各组结果之和为总的召回率。
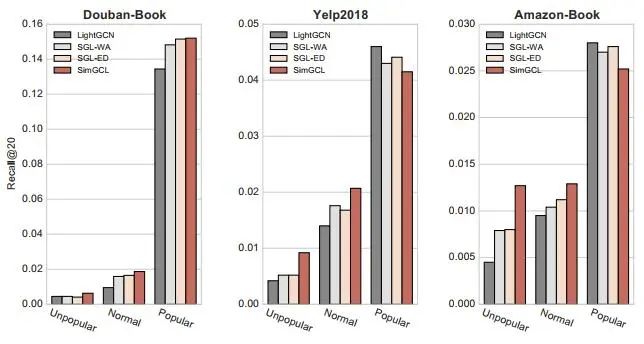
根据上图所示,SimGCL具有极强的去偏效应,其性能提升主要来自于非流行和普通项目,在流行项目上,其推荐效果反而降低了。考虑到用户往往能通过多种渠道可以获取流行项目信息,一个更善于推荐长尾项目的推荐方法更符合用户的实际需要。相比SimGCL, SGL也具有一定去偏能力,而LightGCN更善于推荐流行项目,容易导致推荐结果多样性和新颖性较差。
由以上实验可知,SimGCL在多方面具有良好的性能,可以作为SGL的理想替代模型。
5. 总结
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。



