让人工智能发明自己的语言:OpenAI语言理解研究新方向
选自OpenAI
作者:Igor Mordatch 等
机器之心编译
参与:李泽南、蒋思源、微胖、黄小天
在本文中,OpenAI 展示了自己的新研究,让人工智能体开发自己的语言。
OpenAI 研究人员认为:人工智能只有将学习的语言与实践相结合才能真正理解语言,而不是从巨大语料库中找寻语言模式。作为人工智语言之旅的第一步,我们应该研究人工智能是否可以通过交互合作自发产生一种简单的语言作为其通信工具,该研究的两篇论文已经发表在arXiv 上(见文末)。
让人工智能发明自己的语言
OpenAI 刚刚发布了让人工智能体在简单环境中自创语言的研究论文。通过给予人工智能互相交流的能力,并提出一个通过交流才能实现的奖励目标,研究人员利用强化学习和精巧的实验设计让人工智能有了自己的语言。
目前,人工智能发明的语言相对简单,具有基础与合成性的特征。基础(Grounded)意味着该语言中的单词有关环境中说话者直接经历的东西。例如:单词「树」与树的图像或其他体验之间的联系;合成性(Compositional)意味着说话者可以将多个单词组合成句子以表示特定想法,例如让另一个人工智能体去到特定位置。
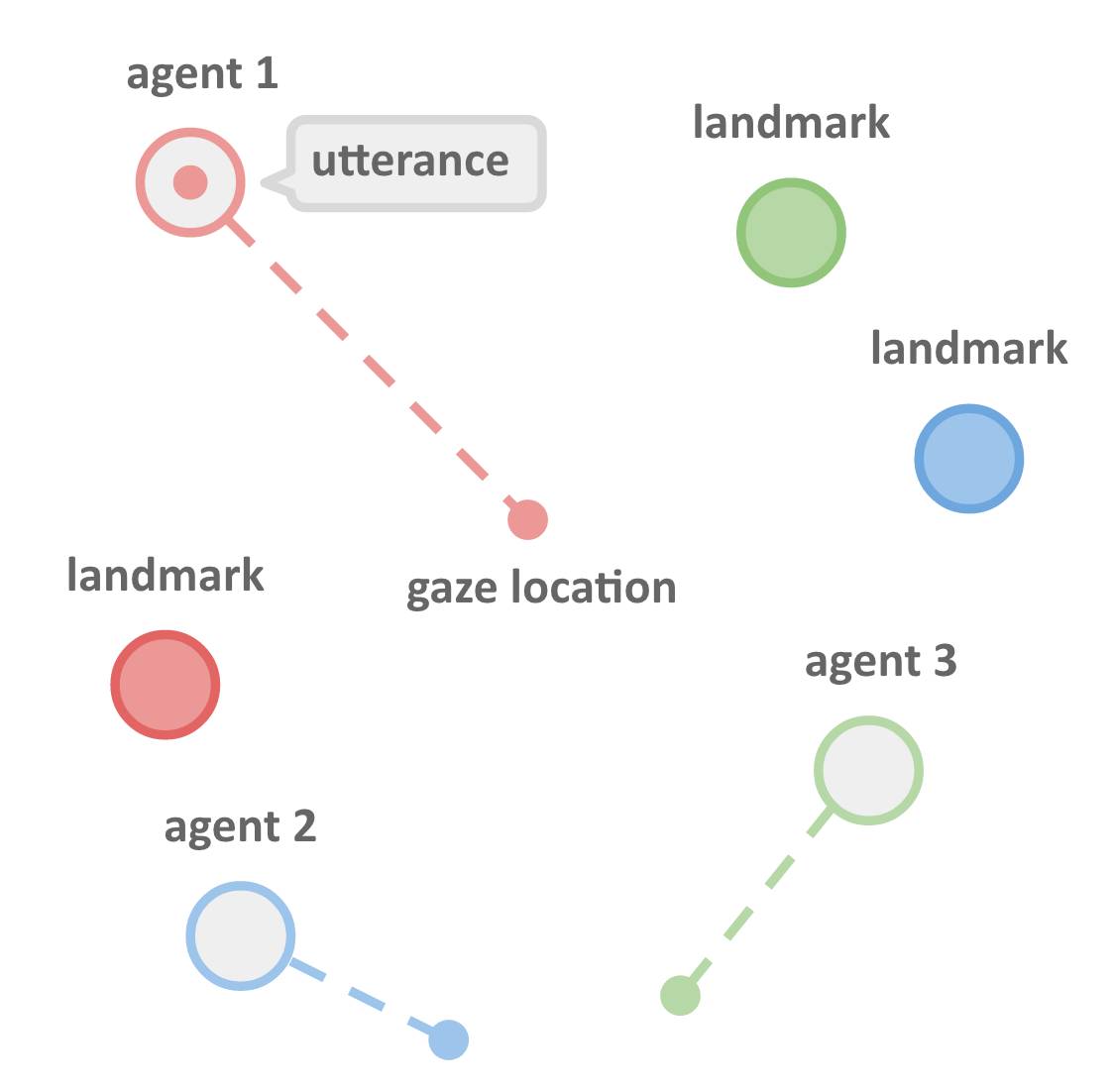
在研究中,人工智能体存在于一个简单的 2D 世界,可以做出移动、观察、与其他人工智能交流等动作。在图中,1号智能体在观察中心点的时候正在说话。
为了训练人工智能体交流的能力,研究者将实验设计成必须进行合作的形式——多智能体强化学习问题。人工智能体存在于具有简单特征的 2D 世界中,每个智能体都有自己的目标:可以是观察一个物体,或是移动到特定的位置,甚至是向另一个人工智能体发出指令让它移动到特定的位置。每一个人工智能都可以向所有人工智能发出信息。每个人工智能获得的奖励分数会被相加计算,随后反馈给各个智能体,这种方式可以鼓励它们的协作。
在每一个时间步里,强化学习智能体可以选择作出两种类型的动作:a. 环境动作,如移动和观察;b. 交流动作,如向其他所有智能体发言。注意:尽管研究者发现人工智能体提出了对应于对象和其他智能体的单词,以及像「看看」或「转到」等动词,但这些单词是由one-hot vector 表示的抽象符号——研究者将这些矢量以英语单词表示以标注它们的含义。在每一个时间步之前,人工智能体都会先处理上一个时间步其他智能体发出的信息,并获知世界中所有物体的位置。交流的信息被存储在人工智能体自有的循环神经网络中,听到的单词会被记住。
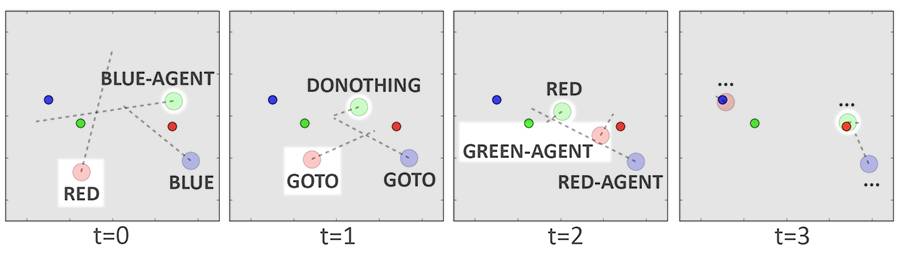
在时间步发展中,t=0 时红色智能体对其他智能体说了一个单词以表示红色界标(图中深红色),随后在t=1 时又说了相当于「去(Goto)」的单词,在 t=2 时它说:「绿色智能体」。绿色智能体听到了这些指令,立即移动到了红色界标的位置。
可区分的动作(信息由类似于单词的符号组成)在互不交汇的信道之中传递。这样,每个信道在每个时间步上都是畅通的,可以保证信息能被传递到所有智能体那里。这种方式是通过稍稍改变信息的内容,让智能体在接受信息时可以获得额外奖励达成的。智能体通过计算关于未来奖励的梯度和收到信息中奖励的变化预期决定自己的下一步动作(例如:这些信息中的哪一个能让奖励变多?)。如果一个智能体意识到另一个智能体发出另一种信息可以更好地完成任务,前者就会告诉后者如何换一种说法。换句话说,人工智能体在任务中会提出这样的问题:「我们应该如何交流才能获得最好的奖励?」
通过使人工智能体发送一个实数向量或者相互发送二进制值的连续近似,再或者使用非微分通信和训练,之前的努力成功获取了这种可微分通信。在训练中研究者使用Gumbel-Softmax 策略来近似带有连续性表征的分离性通信决策,这使研究者们得到了两全其美的结果。在训练中可微分通道意味着智能体可用连续性表征快速学习相互之间如何通信,结果就是在训练结束之后汇聚了分离性输出,这些输出的可阐释性更强,并具有组合性的特点。在下面的视频中,OpenAI展示了如何进化语言以拟合其处境的复杂性:一个人工智能体不需要通信;两个智能体发明了一个词的短语以在处理简单任务时,相互协作;三个智能体创造了包含多个词的句子以用于完成更具挑战性的任务。
通过设计实验影响语言的进化
所有的研究走过的道路都是曲折的。OpenAI 的智能体一开始经常会发明不具有合成性特征的语言。即使智能体成功发明了想要的语言,其解决方案也会经常具有「个人特征」。
研究人员遇到的第一个问题就是智能体创造单一话语并将其映射到空间而产生意义这一倾向。这种莫尔斯电码类的语言很难解密并是一种非合成性(non-compositional)语言。为了纠正这一点,研究员对每个语句添加微小的成本,并对快速完成任务添加了优先权。这样的设置就能鼓励智能体更简洁地进行交流,同时也将拥有更大的词汇量。
研究员遇到的另一个问题是智能体会试图使用单个单词编码整个句子的意义。之所以会发生这样的问题,是因为研究者们赋予了智能体使用大型词汇库的能力。通过大型词汇库,智能体最终会创造出单一话语进而编码整个句子的的意义(如「红色智能体,去蓝色界标」)。虽然这对智能体十分有用,但这种方法要求词汇量的大小与句子长度成指数型地增长,并且与创造人类可解释的(interpretable)人工智能这一目标不相符。为了防止智能体创造出这种语言,研究员们通过给已流行单词加上偏好而压缩单词量的规模,这一灵感来源于「句法交流的演变(Theevolution of syntactic communication)」。研究员们给予特定单词的奖励与这个单词之前所出现的频率成比例。
最后,研究员还发现了一些智能体并不基于颜色,而会基于其他特征如空间位置等线索发明界标参照(landmarkreferences)。例如,智能体会发明一些「top-most」或「left-most」等指代二维坐标系统位置信息的词。虽然这些行为是非常具有创造性的,但其在特定环境中的实现是十分具体的,并且如果从本质上改变智能体所处的地理构成,那么系统就会出现问题。为了解决这个问题,研究者们将智能体放置在以自身为原点的坐标系(智能体之间没有共享的坐标系)。这个做法就解决了方向问题,智能体们也就能有自身的色彩属性指向界标。
不能说话?让我为你指路。听不到?让我做你的向导
当智能体不能通过文本相互交流,并且必须在模拟环境中执行物理运动时,该训练法同样能运作。在接下来的动图中,研究员们展示了智能体指向点的即时情况或指导其他智能体去目标的情况,在极端情况下智能体会看不见它们的目标。
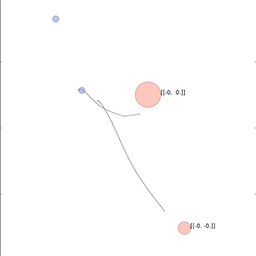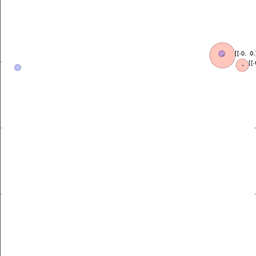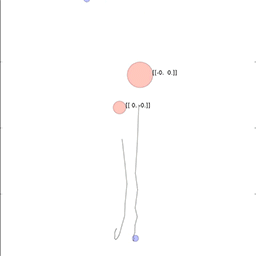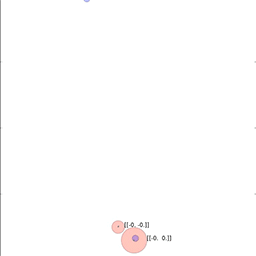

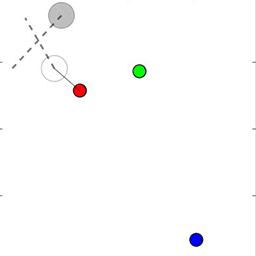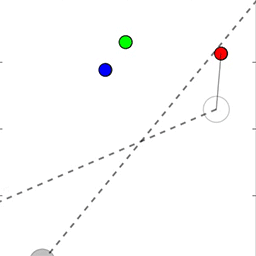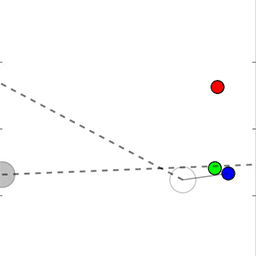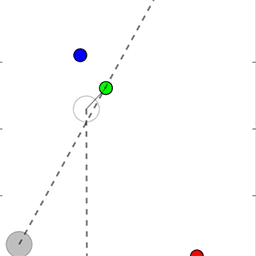
从上到下:人工智能智能体通过指向将目标的位置信息通知另一个智能体;较小的智能体引导更大的智能体朝向目标;智能体将一个盲目的智能体推向一个目标。
推论语言和基底语言
如今,很多人已经将机器学习应用到与语言相关的任务中,也取得了巨大成功。大规模机器学习技术已经在翻译、语言推理、语言理解、句子生成以及其他领域取得了重要成就。所有这些研究方法都是给系统输入海量文本数据,系统从中提取特征并发现模式。虽然这类研究已经产生了无数个发明与创新,但仍然有些缺点,这与所学语言的表征质量有关。越来越多的研究证明,如果以这种方式用某种语言训练计算机,机器并不会深入理解该语言与真实世界的连接方式。该研究试图解决这一根本问题,方法就是训练智能体发明与他们自己对世界的感知紧密联系的语言。
训练语言模型却没基础,这些计算机就像 John Searle 中文房间(Chinese Room)隐喻所描述的机器,它们将输入的文本与类似词典的东西(通过分析海量文本数据所得)进行比较。但是,仍然不清楚的是,这些计算机的想法有多少是关于文本表征内容的,既然它们从未离开过房间,也能与文本描述的世界互动。
中文房间实验
一个对汉语一窍不通,只说英语的人关在一间只有一个开口的封闭房间中。房间里有一本用英文写成的手册,指示该如何处理收到的汉语讯息及如何以汉语相应地回复。房外的人不断向房间内递进用中文写成的问题。房内的人便按照手册的说明,查找到合适的指示,将相应的中文字符组合成对问题的解答,并将答案递出房间。
John Searle 认为,尽管房里的人可以以假乱真,让房外的人以为他确确实实说汉语,他却压根不懂汉语。在上述过程中,房外人的角色相当于程序员,房中人相当于计算机,而手册则相当于计算机程序:每当房外人给出一个输入,房内的人便依照手册给出一个答复(输出)。而正如房中人不可能通过手册理解中文一样,计算机也不可能通过程序来获得理解力。既然计算机没有理解能力,所谓「计算机于是便有智能」便更无从谈起了。
展望下一步
OpenAI 希望该研究能让我们开发出这样的机器,它能够拥有与自己生活经验密切联系的语言。如果我们以这一实验为基础慢慢增加环境复杂性,扩大智能体被允许的活动范围,或许可以创造出一种表达性语言,其中会包含超越这里基础动词和名字的观念。
随着这种被发明出来的语言不断变得复杂,如何为人类解释这些语言就会变成一种挑战。这也是为什么下一个项目中,RyanLowe 和 Igor Mordatch 打算研究如何借由让智能体与说英语的智能体交流,这将让被发明的语言与英语连接起来。这将会自动将他们的语言翻译成我们听得懂的话。这也属于交叉学科的研究内容,跨域人工智能、语言学以及认知科学,也是他们即将与UC Berkeley 的研究人员合作研究的部分内容。
论文:Emergence of Grounded Compositional Language in Multi-Agent Populations

摘要:
通过在大型语料库中构建统计学模式,机器学习在包括机器翻译、问答系统(questionanswering)及情感分析(sentiment analysis)的自然语言处理方面已取得了巨大成功。然而,对于和人交互的智能体(agents)来说,仅仅构建统计学模式还远远不够。在本论文中,我们研究了基础合成语言(groundedcompositional language)能否以及如何在多智能体中作为完成目标的一个手段而出现。为此,我们提出了一种可以生成基础合成语言的多智能体学习环境和方法。这种语言表征为智能体随时间而做出的抽象离散符号流(abstractdiscrete symbols),但其还是具有定义词汇和句法的一致结构(coherent structure)。我们也发现,当语言通信不可用时,指向(pointing)和引领(guiding)等非言语(non-verbal)通信方式也就出现了。
论文地址:https://arxiv.org/pdf/1703.04908.pdf
论文:A Paradigm for Situated and Goal-Driven Language Learning

摘要:
在不同语境中灵活使用语言及与其他个体交流复杂思想是人类智能十分突出的属性。自然语言会话的研究应聚焦于设计可与上述语境整合并与人高效协作的通信智能体。
在该论文中,我们提出了一个通用性情境语言学习(general situated languagelearning)范式,其设计目的在于打造一个与人高效协作的鲁棒性语言智能体。该会话范式(dialogue paradigm)基于语言理解的实用性定义而构建。语言只是智能体在环境中完成目标的工具之一。只有当智能体运用语言高效完成目标,我们才说智能体「理解」了语言。在该定义下,智能体的通信成功(communicationsuccess)减少了其在环境中完成任务的成功。
这一设置通过和许多传统的自然语言任务对比,最大化了由静态数据集衍生的语言学目标。这样的应用经常因为将语言具化为自己的终止而犯错。这些任务优先独立度量语言智能(通常是语言能力的一种,按照乔姆斯基的说法(1965)),而不是在真实情景中度量模型的有效性。实用性定义(utilitariandefinition)由强化学习最近的成功而引发。在强化学习的设定中,智能体将真实世界的任务中的成功度量最大化,而无需语言行为(linguisticbehavior)的直接监督。

论文地址:https://arxiv.org/pdf/1610.03585.pdf
机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




