一文详解超参数调优方法

©PaperWeekly 原创 · 作者|王东伟
单位|Cubiz
研究方向|深度学习
本文介绍超参数(hyperparameter)的调优方法。
-
模型参数,在训练中通过梯度下降算法更新; -
超参数,在训练中一般是固定数值或者以预设规则变化,比如批大小(batch size)、学习率(learning rate)、正则化项系数(weight decay)、核函数中的 gamma 等。
超参数调优的目标通常是最小化泛化误差(generalization error),也可以根据具体任务自定义其他优化目标。泛化误差是指预测未知样本得到的误差,通常由验证集得到,关于验证集可以参阅 Cross-validation (statistics). Wikipedia.。

网格搜索就是遍历所有可能的超参数组合,找到能得到最佳性能(比如最小化泛化误差)的超参数组合,但是由于一次训练的计算代价很高,搜索区间通常只会限定于少量的离散数值,以下用一段伪代码说明:
def train(acf, wd, lr):
优化目标函数得到模型M
由验证集得到泛化误差e
return e
learning_rate = [0.0001, 0.001, 0.01, 0.1]
weight_decay = [0.01, 0.1, 1]
activation = ['ReLU', 'GELU', 'Swish']
optimum = {'error': 1e10}
# grid search
for acf in activation:
for wd in weight_decay:
for lr in learning_rate:
error = train(acf, wd, lr)
if error < optimum['error']:
optimum['error'] = error
optimum['param'] = {
'acf': acf,
'wd': wd,
'lr': lr
}

随机搜索在预先设定的定义域内随机选取超参数组合。实验证明随机搜索比网格搜索更高效,主要原因是随机搜索可以搜索连续数值并且可以设定更大的搜索空间,因此有几率得到更优的模型。另外,对于仅有少数超参数起决定性作用的情况,随机搜索对于重要参数的搜索效率更高。
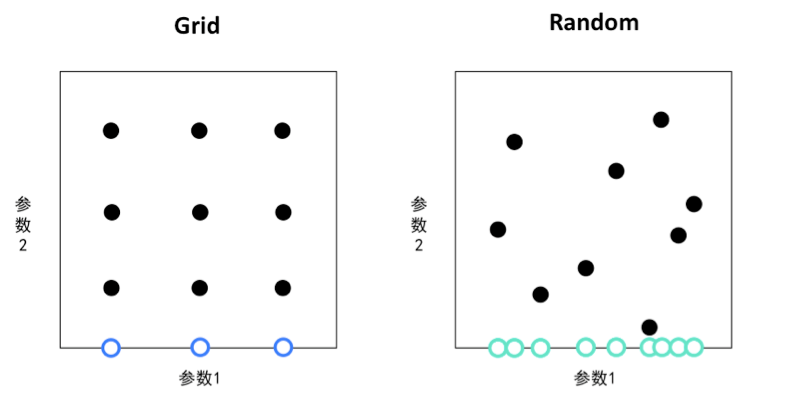
▲ 图1

贝叶斯优化 Bayesian optimization
给定一组超参数,为了计算相应的模型泛化误差,我们需要进行一次完整的模型训练,对于大型的深度学习模型可能需要花上几个小时的时间。注意到网格搜索和随机搜索中,不同的超参数采样是相互独立的,一个直接的想法是,能否充分利用已采样数据来决定下一次采样,以提高搜索效率(或者说减少采样次数)。
早在 1960 年,就有科学家 Danie G. Krige 用类似的方法用于金矿分布的估计,他用已开采的少数矿点对金矿分布进行建模,后来这类方法被称为 Kriging 或高斯过程回归(Gaussian process regression, GPR)。
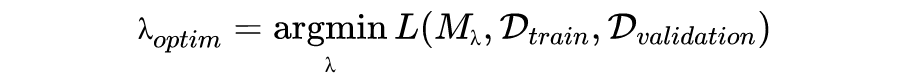
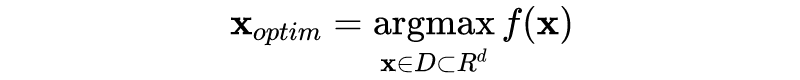

▲ 图2,源:https://arxiv.org/abs/1012.2599
3.2 高斯过程
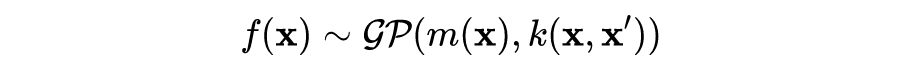
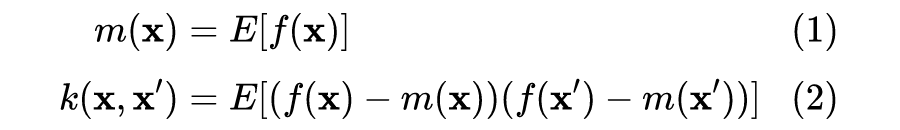
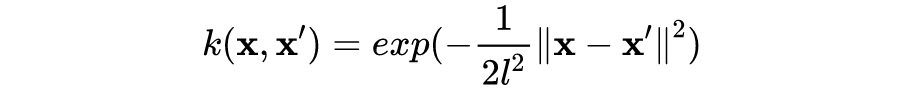
容易发现,上述协方差函数描述了不同输入之间的距离,或者说相似性(similarity)。对于回归或者分类问题,一个合理的假设是,距离较近的输入 x 有相近的目标函数值(或者类别标签)y,比如在分类问题中,距离测试样本更近的训练样本将提供更多关于测试样本类别的信息。可以说,协方差函数“编码”了我们对目标函数的假设。
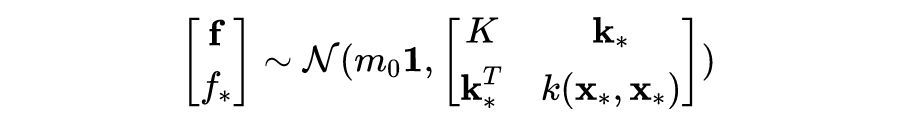
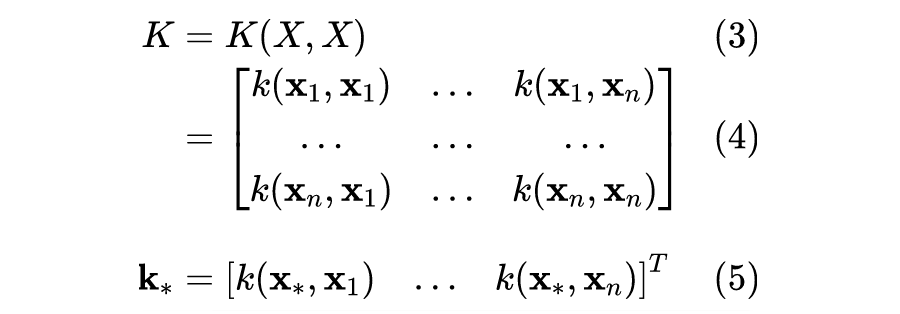
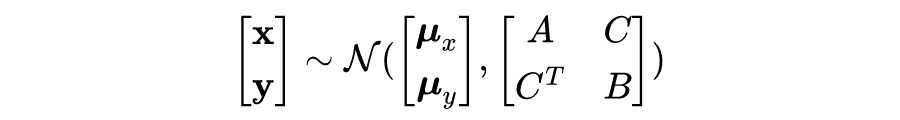
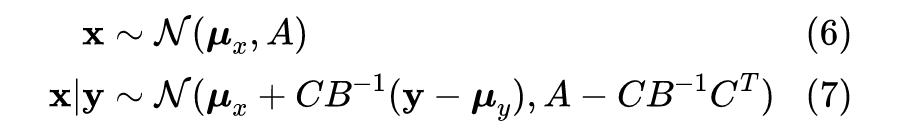
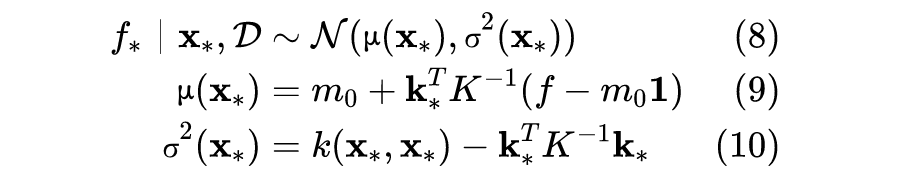
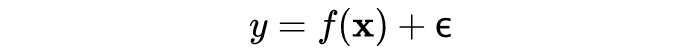
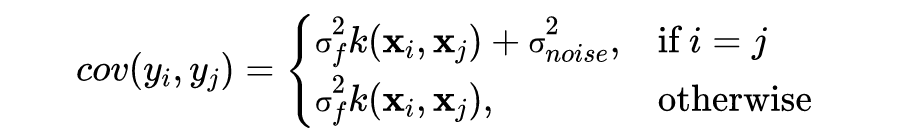
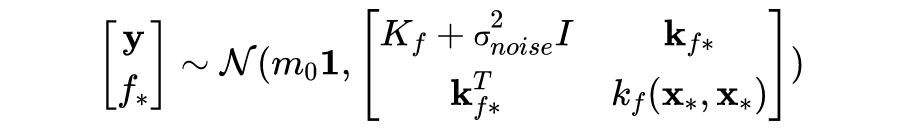
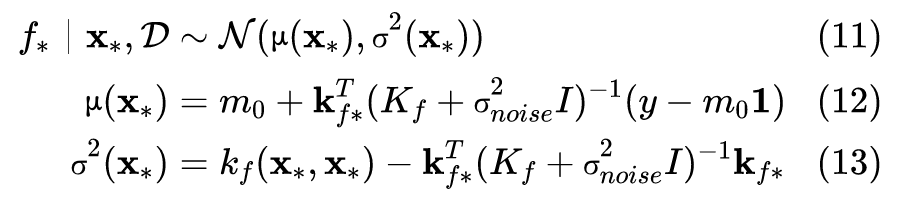
3.4 GP模型的超参数
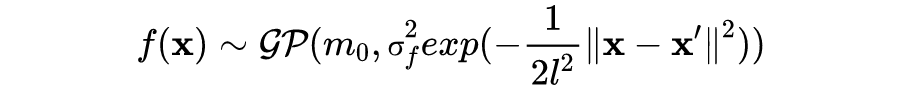
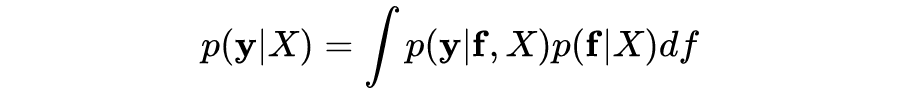
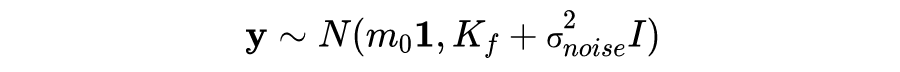
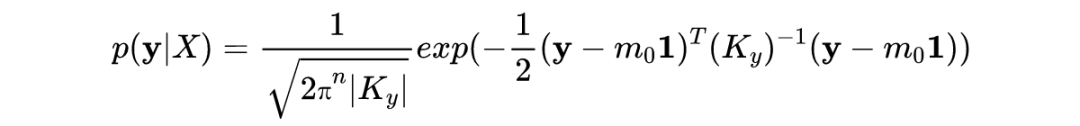
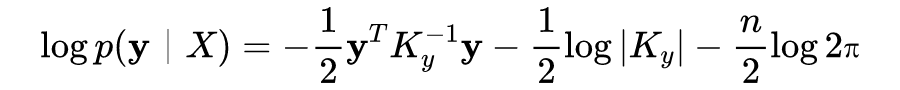
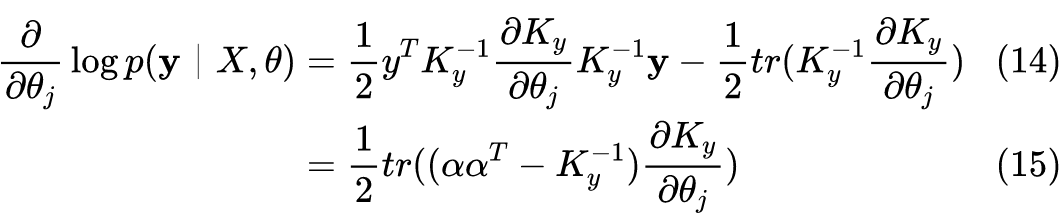
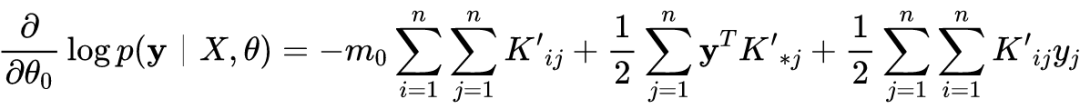
接下来我们可以通过类似梯度上升的优化算法得到最优参数值。
3.5 协方差函数
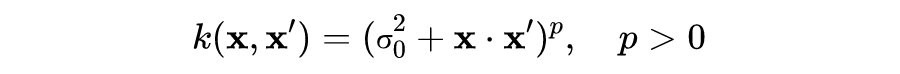
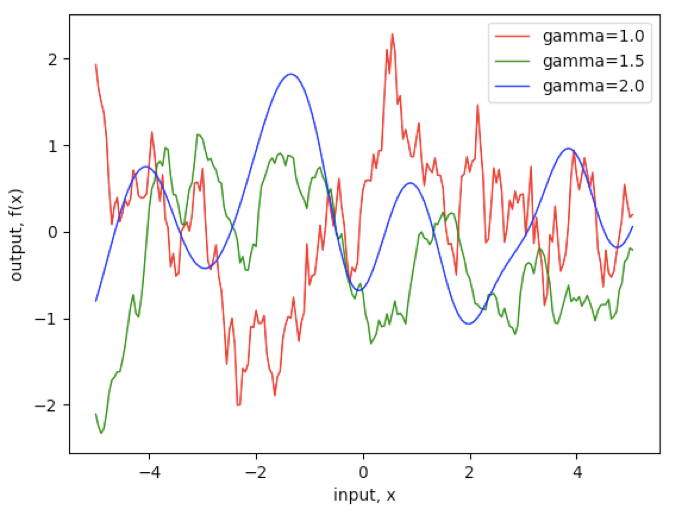
平滑性(smoothness)。随机过程的平滑性由均方可微性(mean square differentiability)决定,比如,SE 函数对应的高斯过程是无限均方可微的。关于均方导数、均方可微的定义你可以自行了解。
a. 伽马指数函数(γ-exponential covariance function)
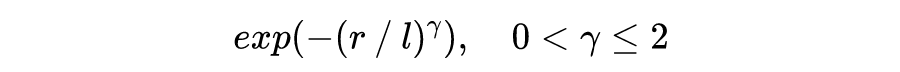
b. 马顿函数(The Matérn class of covariance functions)
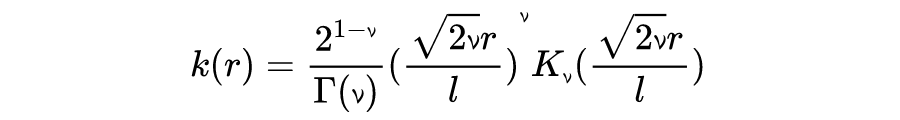
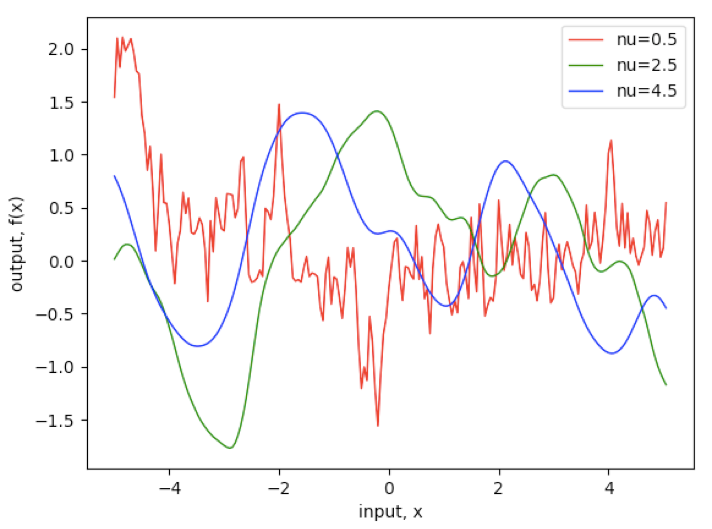
▲ 图5
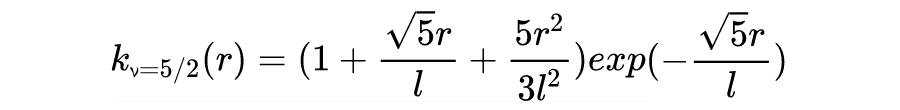
c. 二次有理函数(rational quadratic covariance function)
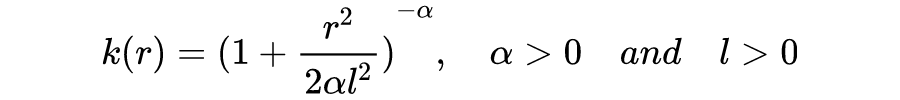
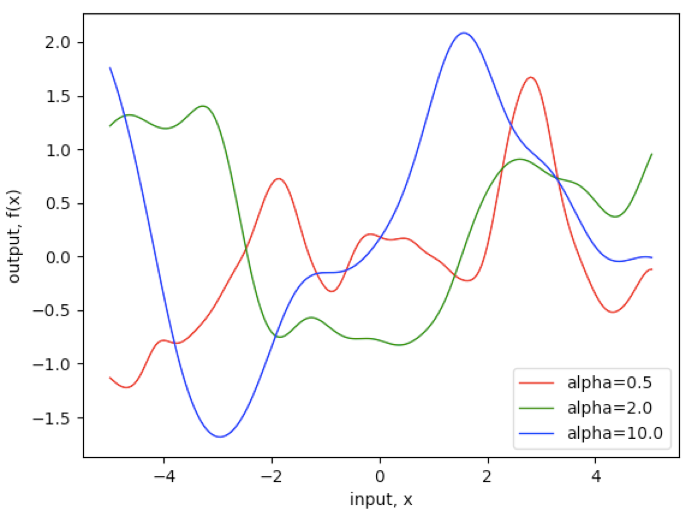
▲ 图6
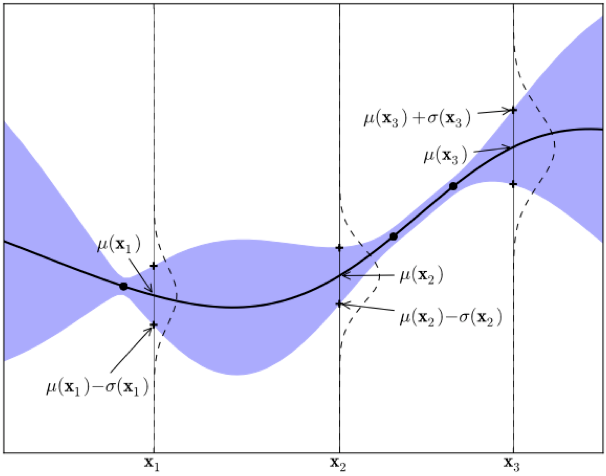
3.6 采样函数
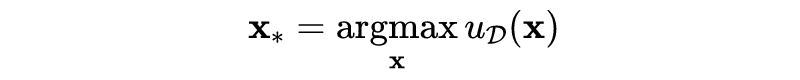
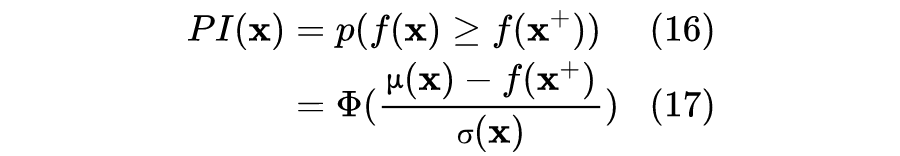
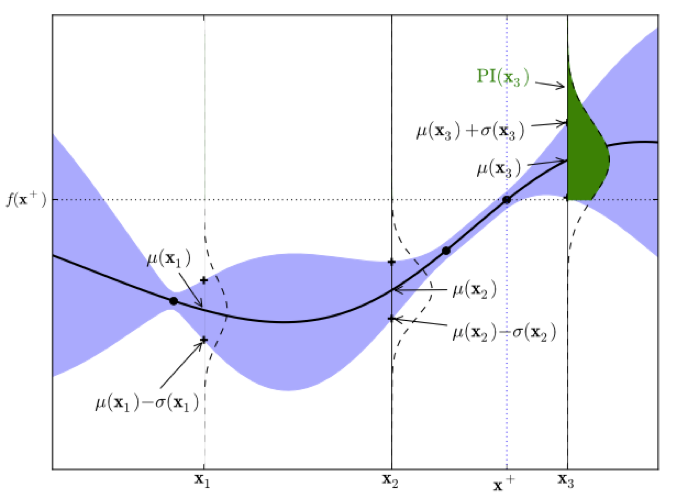
▲ 图7,源:https://arxiv.org/abs/1012.2599
a. Probability of improvement (PI)
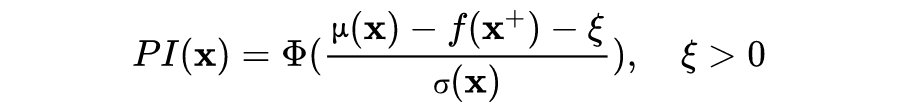
b. Expected improvement (EI)
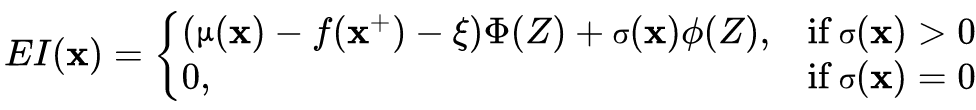
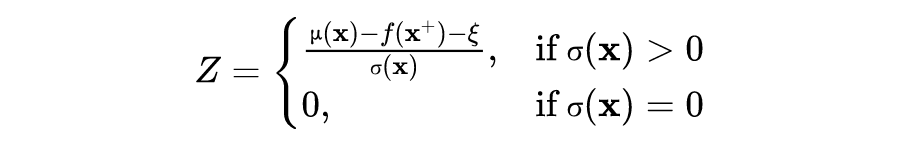
c. Upper confidence bound (UCB & GP-UCB)
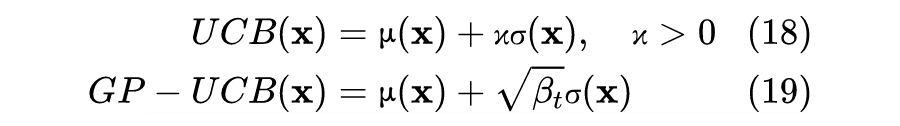
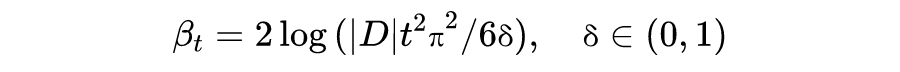

总结
采样函数的选择。对于选择哪个采样函数目前没有明确的规则,有论文提出用组合采样函数的方法可以得到比单独使用更好的实验表现,参阅 Portfolio Allocation for Bayesian Optimization. Eric Brochu, Matthew W. Hoffman, Nando de Freitas. 2010.。其他采样函数,如 knowledge-gradient The Knowledge-Gradient Policy for Correlated Normal Beliefs. Peter Frazier, Warren Powell, Savas Dayanik. 2008.,entropy search (ES) Entropy Search for Information-Efficient Global Optimization. Philipp Hennig, Christian J. Schuler. 2012.,predictive entropy search (PES) Predictive Entropy Search for Efficient Global Optimization of Black-box Functions. José Miguel Hernández-Lobato, Matthew W. Hoffman, Zoubin Ghahramani. 2014.,结合 fully Bayesian 的GP EI MCMC Practical Bayesian Optimization of Machine Learning Algorithms. Jasper Snoek, Hugo Larochelle, Ryan P. Adams. 2012.,提升采样函数效率的 mixture cross-entropy algorithm Surrogating the surrogate: accelerating Gaussian-process-based global optimization with a mixture cross-entropy algorithm. R ́emi Bardenet, Bal ́azs K ́egl. 2010.。
其他贝叶斯优化算法。采用随机森林建模的 Sequential Model-based Algorithm Configuration (SMAC) Sequential Model-Based Optimization for General Algorithm Configuration. Frank Hutter, Holger H. Hoos, Kevin Leyton-Brown. 2011.,更适合高维度、离散化、超参数间有条件依赖的 Tree Parzen Estimator (TPE) Algorithms for Hyper-Parameter Optimization. James Bergstra, R ́emi Bardenet, Yoshua Bengio, Bal ́azs K ́egl. 2011.,以及提升 GP 模型计算效率的 SPGPs 和 SSGPs Taking the Human Out of the Loop: A Review of Bayesian Optimization. Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, Nando de Freitas. 2016.。
附录:部分算法的Python代码示例
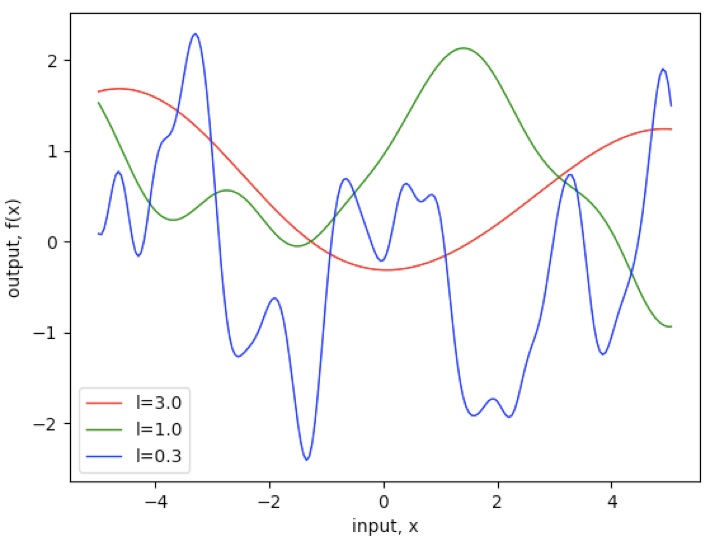
a. 多元高斯分布采样。原理参阅[GPML, Appendix A, A.2]。
from matplotlib import pyplot as plt
import numpy as np
# SE协方差函数
kernel_se = np.vectorize(lambda x1, x2, l: np.exp(-(x1 - x2) ** 2 / (2 * l ** 2)))
def sample_se(x, l, mean=0):
# x为numpy数组,e.g. x = np.arange(-5, 5, 0.05)
x1, x2 = np.meshgrid(x, x)
n = len(x)
sigma = kernel_se(x1, x2, l) + np.identity(n) * 0.000000001
L = np.linalg.cholesky(sigma)
u = np.random.randn(n)
y = mean + L @ u
return y
c = ['red', 'green', 'blue']
l = [3, 1, 0.3]
for i in range(len(l)):
x = np.arange(-5, 5, 0.05)
y = sample_se(x, l[i])
plt.plot(x, y, c=c[i], linewidth=1, label='l=%.1f' % l[i])
plt.xlabel('input, x')
plt.ylabel('output, f(x)')
plt.legend(loc='best')
plt.show()
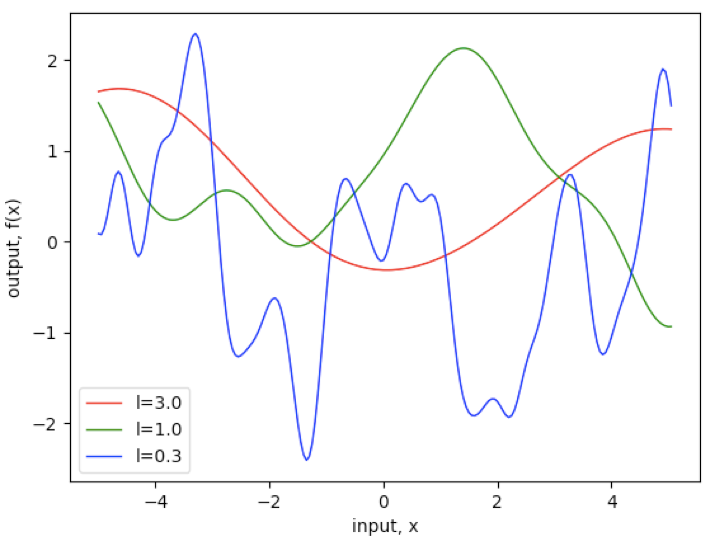
output: ![]()
from matplotlib import pyplot as plt
import numpy as np
# 目标函数
objective = np.vectorize(lambda x, std_n=0: 0.001775 * x**5 - 0.055 * x**4 + 0.582 * x**3 - 2.405 * x**2 + 3.152 * x + 4.678 + np.random.normal(0, std_n))
# 超参数
mean, l, std_f, std_n = 5, 1, 1, 0.0001
# SE协方差函数
kernel = lambda r_2, l: np.exp(-r_2 / (2 * l**2))
# 训练集,以一维输入为例
X = np.arange(1.5, 10, 3.0)
X = X.reshape(X.size, 1)
Y = objective(X).flatten()
# 未知样本
Xs = np.arange(0, 10, 0.1)
Xs = Xs.reshape(Xs.size, 1)
n, d = X.shape
t = np.repeat(X.reshape(n, 1, d), n, axis=1) - X
r_2 = np.sum(t**2, axis=2)
Kf = std_f**2 * kernel(r_2, l)
Ky = Kf + std_n**2 * np.identity(n)
Ky_inv = np.linalg.inv(Ky)
m = Xs.shape[0]
t = np.repeat(Xs.reshape(m, 1, d), n, axis=1) - X
r_2 = np.sum(t**2, axis=2).T
kf = std_f**2 * kernel(r_2, l)
mu = mean + kf.T @ Ky_inv @ (Y - mean)
std = np.sqrt(std_f**2 - np.sum(kf.T @ Ky_inv * kf.T, axis=1))
x_test = Xs.flatten()
y_obj = objective(x_test).flatten()
plt.plot(x_test, mu, c='black', lw=1, label='predicted mean')
plt.fill_between(x_test, mu + std, mu - std, alpha=0.2, color='#9FAEB2', lw=0)
plt.plot(x_test, y_obj, c='red', ls='--', lw=1, label='objective function')
plt.scatter(X.flatten(), Y, c='red', marker='o', s=20)
plt.legend(loc='best')
plt.show()
output:
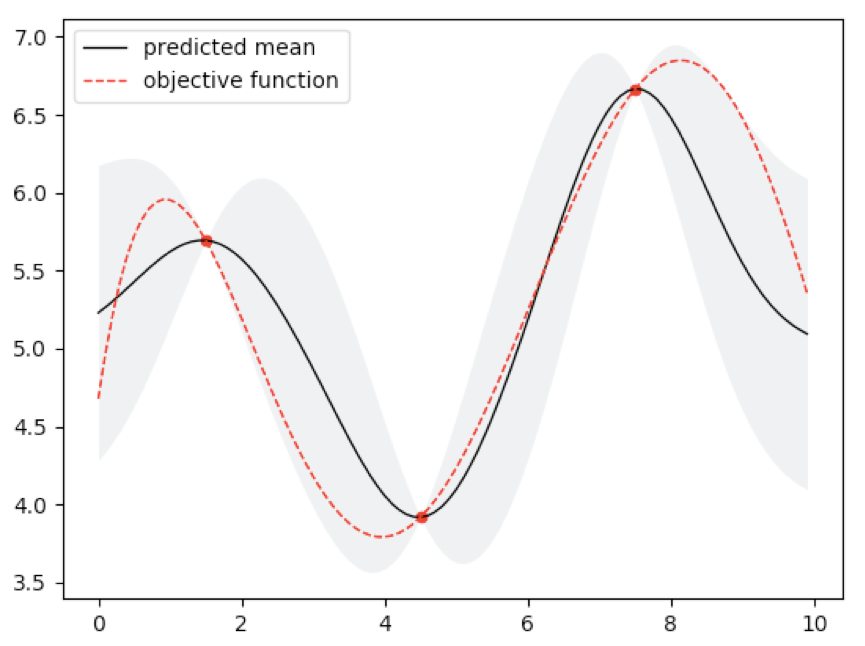
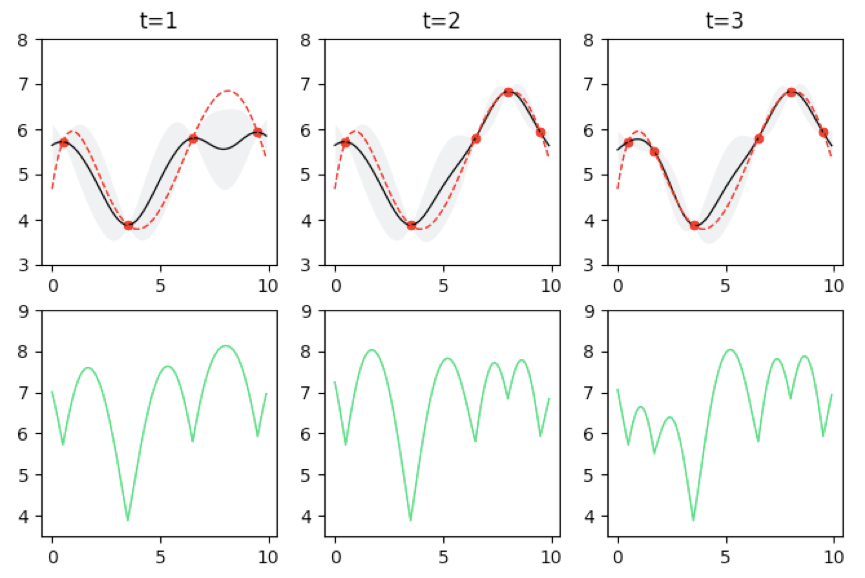
c. 贝叶斯优化示例。
from matplotlib import pyplot as plt
import numpy as np
# 目标函数
objective = np.vectorize(lambda x, sigma_n=0: 0.001775 * x**5 - 0.055 * x**4 + 0.582 * x**3 - 2.405 * x**2 + 3.152 * x + 4.678 + np.random.normal(0, sigma_n))
# 采样函数 - GP-UCB
GPUCB = np.vectorize(lambda mu, sigma, t, ld, delta=0.1: mu + (1 * 2 * np.log(ld * t**2 * np.pi**2 / (6 * delta)))**0.5 * sigma)
# 超参数
mean, l, sigma_f, sigma_n = 5, 1, 1, 0.0001
# 迭代次数
max_iter = 3
# SE协方差函数
kernel = lambda r_2, l: np.exp(-r_2 / (2 * l**2))
# 初始训练样本,以一维输入为例
X = np.arange(0.5, 10, 3.0)
X = X.reshape(X.size, 1)
Y = objective(X).flatten()
plt.figure(figsize=(8,5))
for i in range(max_iter):
Xs = np.arange(0, 10, 0.1)
Xs = Xs.reshape(Xs.size, 1)
n, d = X.shape
t = np.repeat(X.reshape(n, 1, d), n, axis=1) - X
r_2 = np.sum(t**2, axis=2)
Kf = sigma_f**2 * kernel(r_2, l)
Ky = Kf + sigma_n**2 * np.identity(n)
Ky_inv = np.linalg.inv(Ky)
m = Xs.shape[0]
t = np.repeat(Xs.reshape(m, 1, d), n, axis=1) - X
r_2 = np.sum(t**2, axis=2).T
kf = sigma_f**2 * kernel(r_2, l)
mu = mean + kf.T @ Ky_inv @ (Y - mean)
sigma = np.sqrt(sigma_f**2 - np.sum(kf.T @ Ky_inv * kf.T, axis=1))
y_acf = GPUCB(mu, sigma, i + 1, n)
sample_x = Xs[np.argmax(y_acf)]
x_test = Xs.flatten()
y_obj = objective(x_test).flatten()
ax = plt.subplot(2, max_iter, i + 1)
ax.set_title('t=%d' % (i + 1))
plt.ylim(3, 8)
plt.plot(x_test, mu, c='black', lw=1)
plt.fill_between(x_test, mu + sigma, mu - sigma, alpha=0.2, color='#9FAEB2', lw=0)
plt.plot(x_test, y_obj, c='red', ls='--', lw=1)
plt.scatter(X, Y, c='red', marker='o', s=20)
plt.subplot(2, max_iter, i + 1 + max_iter)
plt.ylim(3.5, 9)
plt.plot(x_test, y_acf, c='#18D766', lw=1)
X = np.insert(X, 0, sample_x, axis=0)
Y = np.insert(Y, 0, objective(sample_x))
plt.show()

参考文献
更多阅读



#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




