强文!LEARNING ACTIONABLE REPRESENTATIONS WITH GOAL.. POLICIES
LEARNING ACTIONABLE REPRESENTATIONS WITH GOAL-CONDITIONED POLICIES
Dibya Ghosh∗ , Abhishek Gupta & Sergey Levine Department of Electrical Engineering and Computer Science University of California, Berkeley Berkeley, CA 94720, USA
ABSTRACT Representation learning is a central challenge across a range of machine learning areas. In reinforcement learning, effective and functional representations have the potential to tremendously accelerate learning progress and solve more challenging problems. Most prior work on representation learning has focused on generative approaches, learning representations that capture all underlying factors of variation in the observation space in a more disentangled or well-ordered manner. In this paper, we instead aim to learn functionally salient representations: representations that are not necessarily complete in terms of capturing all factors of variation in the observation space, but rather aim to capture those factors of variation that are important for decision making – that are “actionable.” These representations are aware of the dynamics of the environment, and capture only the elements of the observation that are necessary for decision making rather than all factors of variation, without explicit reconstruction of the observation. We show how these representations can be useful to improve exploration for sparse reward problems, to enable long horizon hierarchical reinforcement learning, and as a state representation for learning policies for downstream tasks. We evaluate our method on a number of simulated environments, and compare it to prior methods for representation learning, exploration, and hierarchical reinforcement learning.
重点笔记:
Maximum entropy RL. Maximum entropy RL algorithms modify the RL objective, and instead learns a policy to maximize the reward as well as the entropy of the policy (Haarnoja et al., 2017; Todorov, 2006), according to π ? = arg maxπ Eπ[r(s, a)] + H(π). In contrast to standard RL, where optimal policies in fully observed environments are deterministic, the solution in maximum entropy RL is a stochastic policy, where the entropy reflects the sensitivity of the rewards to the action: when the choice of action has minimal effect on future rewards, actions are more random, and when the choice of action is critical, the actions are more deterministic. In this way, the action distributions for a maximum entropy policy carry more information about the dynamics of the task.
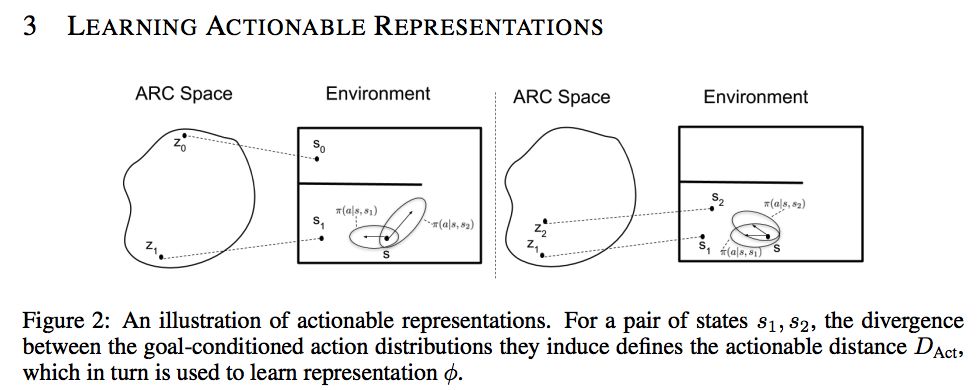
In this work, we extract a representation that can distinguish states based on actions required to reach them, which we term an actionable representation for control (ARC). In order to learn state representations φ that can capture the elements of the state which are important for decision making, we first consider defining actionable distances DAct(s1, s2) between states.
thereby implicitly capturing dynamics. If actions required for reaching state s1 are very different from the actions needed for reaching state s2, then these states are functionally different, and should have large actionable distances

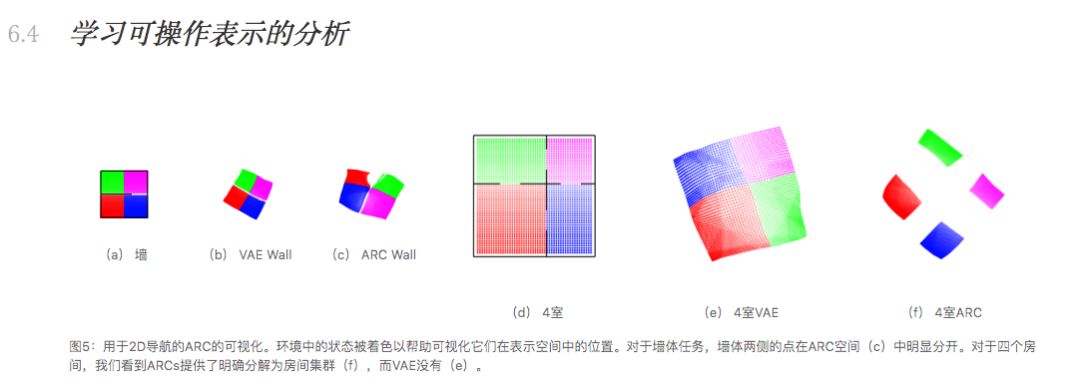
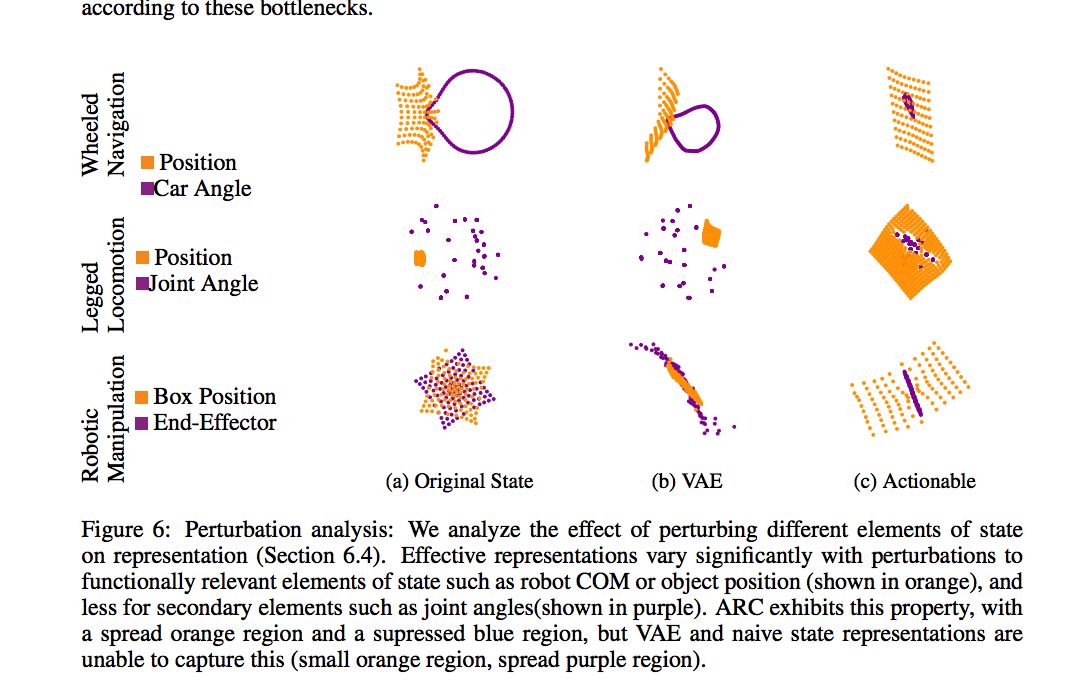
6 实验 非常充分,比其他方法都好很多。
6.2 LEARNING THE GOAL-CONDITIONED POLICY AND ARC REPRESENTATION
6.5 LEVERAGING ACTIONABLE REPRESENTATIONS FOR REWARD SHAPING
6.6 LEVERAGING ACTIONABLE REPRESENTATIONS AS FEATURES FOR LEARNING POLICIES
6.7 BUILDING HIERARCHIES FROM ACTIONABLE REPRESENTATIONS
CreateAMind永久招聘:能复现出次论文跑出效果,工资你来提。
招聘笔记:http://note.youdao.com/noteshare?id=b0f27c01f384e96d30ee1c1d2a5c7d31
https://arxiv.org/pdf/1811.07819.pdf




