CVPR2019 | 目标检测新文:Generalized Intersection over Union
点击上方“CVer”,选择加"星标"
重磅干货,第一时间送达


作者 | ywsun
论文链接 | arxiv.org/abs/1902.0963
原文地址:
https://zhuanlan.zhihu.com/p/57863810
论文名称:《Generalized Intersection over Union: A Metric and A Loss for Bounding Box
Regression 》
1.Motivation
包围框回归是2D/3D 视觉任务中一个最基础的模块,不管是目标检测,目标跟踪,还是实例分割,都依赖于对bounding box进行回归,以获得准确的定位效果。目前基于深度学习的方法想获得更好的检测性能,要么是用更好的backbone,要么是设计更好的策略提取更好的feature,然而却忽视了bounding box regression中L1、L2 loss这个可以提升的点。
IoU是目标检测中一个重要的概念,在anchor-based的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离,或者说predict box的准确性。IoU有一个好的特性就是对尺度不敏感(scale invariant)。
在regression任务中,判断predict box和gt的距离最直接的指标就是IoU,但所采用的loss却不适合,如图所示,在loss相同的情况下,regression的效果却大不相同,也就是说loss没有体现出regression的效果,而IoU却可以根据不同的情况得到不同的数值,能最直接反应回归效果。
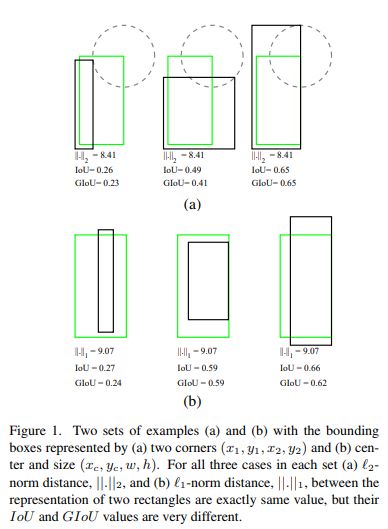
2.Method
因此本文提出用IoU这个直接的指标来指导回归任务的学习。与其用一个代理的损失函数来监督学习,不如直接用指标本身来的好。此时损失函数为:
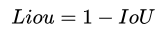
但直接用IoU作为损失函数会出现两个问题:
如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。
IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
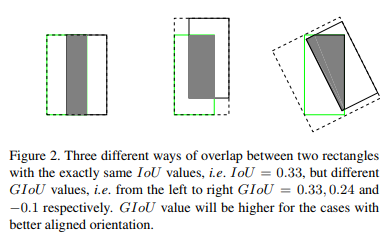
针对IoU上述两个缺点,本文提出一个新的指标generalized IoU(GIoU):

GIoU的定义很简单,就是先计算两个框的最小闭包区域面积,再计算IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。GIoU有如下4个特点:
与IoU相似,GIoU也是一种距离度量,作为损失函数的话,
,满足损失函数的基本要求
GIoU对scale不敏感
GIoU是IoU的下界,在两个框无线重合的情况下,IoU=GIoU
IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。
与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
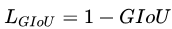
其实GIoU不仅定义简单,在2D目标检测中计算方式也很简单,计算重合区域和IoU一样,计算最小闭包区域只需要得到两者max和min坐标,坐标围城的矩形就是最小闭包区域。
GIoU和IoU作为loss的算法如下所示:

步骤:
分别计算gt和predict box的面积
计算intersection的面积
计算最小闭包区域面积
计算IoU和GIoU
根据公式得到loss
3.Experiments
GIoU loss可以替换掉大多数目标检测算法中bounding box regression,本文选取了Faster R-CNN、Mask R-CNN和YOLO v3 三个方法验证GIoU loss的效果。实验在Pascal VOC和MS COCO数据集上进行。
实验效果如下:
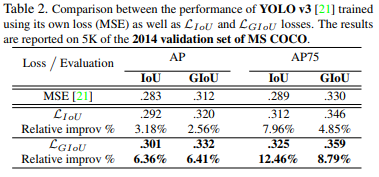
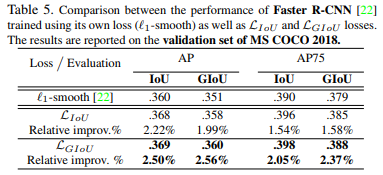
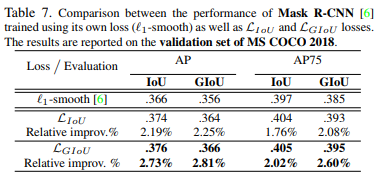
可以看出YOLOv3在COCO上有明显涨点,但在其他模型下涨点并不明显,作者也指出了faster rcnn和mask rcnn效果不明显的原因是anchor很密,GIoU发挥作用的情况并不多。
总体来说,文章的motivation比较好,指出用L1、L2作为regression损失函数的缺点,以及用直接指标IoU作为损失函数的缺陷性,提出新的metric来代替L1、L2损失函数,从而提升regression效果,想法简单粗暴,但work的场景有很大局限性。
---End---
想要了解最新最快最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。

扫码进群
这么硬的论文速递,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!


