CNN能同时兼顾速度与准确度吗?CMU提出AdaScale
选自arxiv
作者:Ting-Wu Chin、Ruizhou Ding、Diana Marculescu
机器之心编译
参与:Panda
对机器人和自动驾驶汽车等很多应用而言,视频目标检测都是很重要的。但在使用 CNN 执行这一任务时,速度与准确度往往不可得兼。卡内基·梅隆大学新提出的 AdaScale 方法却实现了对这两个要素的兼顾。介绍该方法的论文已被系统与机器学习会议(SysML)接收,该会议将于当地时间 3 月 31 日- 4 月 2 日在斯坦福大学举办。
论文:AdaScale: Towards Real-time Video Object Detection Using Adaptive Scaling

论文地址:https://arxiv.org/abs/1902.02910
在机器人和自动汽车等具备视觉能力的自动系统中,视频目标检测发挥着关键的作用。为了提供可靠的操作,视频目标检测的速度和准确度都是重要的因素。我们在这篇论文中表明的关键见解是当涉及到图像缩放时,速度和准确度并无必要权衡。我们的结果表明将图像的尺寸重新调整到更低的分辨率时,有时会得到更好的准确度。基于这一观察,我们提出了一种全新的方法 AdaScale,可以自适应地选择输入图像的尺寸,从而同时提升视频目标检测的准确度和速度。我们在 ImageNet VID 和 mini YouTube-BoundingBoxes 数据集上进行了实验,结果分别在加速 1.6 和 1.8 倍的情况下实现了 1.3 和 2.7 个百分点的平均精度均值(mAP)提升。此外,我们还将 ImageNet VID 数据集上当前最佳的视频加速工作提速了额外 1.25 倍,且 mAP 也略好一些。
引言
对于自动汽车、无人机和机器人等未来的自动智能体而言,视觉目标检测是视觉认知的一个基本构建模块。因此,为了构建性能可靠的系统,检测器必须要快速且准确。尽管目标检测非常适合静态图像(Dai et al., 2016; Girshick, 2015; He et al., 2014; Liu et al., 2016; Ren et al., 2015),但在视频目标检测方面还存在一些特有的挑战,包括由物体移动造成的运动模糊、相机对焦失败(Zhu et al., 2017a)以及自动智能体的实时速度限制。但是,除了这些难题之外,视频目标检测也会带来可以利用的新机会。之前一些关注视频目标检测的研究试图通过利用视频的一种独特特征来提升平均精度(Zhu et al., 2017a; Feichtenhofer et al., 2017; Kang et al., 2017),即时间一致性(连续帧有相似的内容)。另外,在速度方面,之前有研究(Zhu et al., 2017b; 2018b; Buckler et al., 2018)依靠这种时间一致性来降低独立的目标检测器所需的计算。类似地,我们的目标也是利用时间一致性,并使用一种名为自适应缩放测试(AdaScale/ adaptive-scale testing)的全新技术来同时提升独立目标检测器的速度和准确度。
输入图像的尺寸会同时影响基于 CNN 的现代目标检测器的速度和准确度(Huang et al., 2017)。之前与图像缩放相关的研究针对的是两个方向:(1)为了得到更好准确度的多尺寸测试,(2)为了实现更高速度的图像下采样。第一类的例子包括将图像调整为多个尺寸(图像金字塔)并使它们通过 CNN 以实现多个尺寸的特征提取(Dai et al., 2016; Girshick, 2015; He et al., 2014),然后通过一张单尺寸的输入图像生成的不同层来融合特征图(Lin et al., 2017a; Cai et al., 2016; Bell et al., 2016)。但是,相比于仅有单个尺寸的输入,这样的方法会引入额外的计算开销。第二类的例子包括通过调整输入图像尺寸的 Pareto 最优搜索(Lin et al., 2017b; Liu et al., 2016; Redmon & Farhadi, 2017; Huang et al., 2017)以及根据输入图像进行的动态图像尺寸调整(Chin et al., 2018)。但是,这样的方法的结果表明,在进行图像缩放时,更高速度的代价是准确度更低。
不同于之前的研究,我们发现下采样有时候有助于提升准确度。具体而言,图像下采样能带来两类提升:(1)减少假正例(false positive)的数量,而关注不必要的细节可能会引入假正例;(2)增加真正例(true positive)的数量,方法是通过将过大的目标缩放到目标检测器更有信心处理的尺寸。图 1 表明,在我们在 ImageNet VID 数据集上使用基于区域的全卷积网络(R-FCN)(Dai et al., 2016)目标检测器的实验中,下采样时得到的结果更好的图像。

图 1:下采样后的图像得到的检测结果更好的示例。蓝框是检测结果,数字是置信度。这个检测器是在 600(短边的像素)的单尺寸上训练的。(a) 和 (c) 列是在 600 尺寸上的测试结果,(b) 列是在 240 尺寸上的测试结果,(c) 列则是 480。
受此启发,我们的目标是将图像调整至它们的最佳尺寸,以同时得到更高的速度和准确度。在这项研究中,我们提出了 AdaScale 来提升独立目标检测器的准确度和速度。具体来说,我们使用当前帧来预测下一帧的最佳尺寸。我们在 ImageNet VID 和 mini YouTube-BoundingBoxes 数据集上进行了实验,结果分别在加速 1.6 和 1.8 倍的情况下实现了 1.3 和 2.7 个百分点的平均精度均值(mAP)提升。此外,通过结合在 ImageNet VID 数据集上当前最佳的视频加速工作(Zhu et al., 2017b),我们为其提速了额外 25%,且 mAP 也略好一些。
自适应缩放
图 2 展示了 AdaScale 方法的概况。其中包含微调目标检测器、使用所得到的检测器生成最优的尺寸标签、使用所生成的标签训练尺寸回归器以及 AdaScale 在视频目标检测中的部署。

图 2:AdaScale 方法
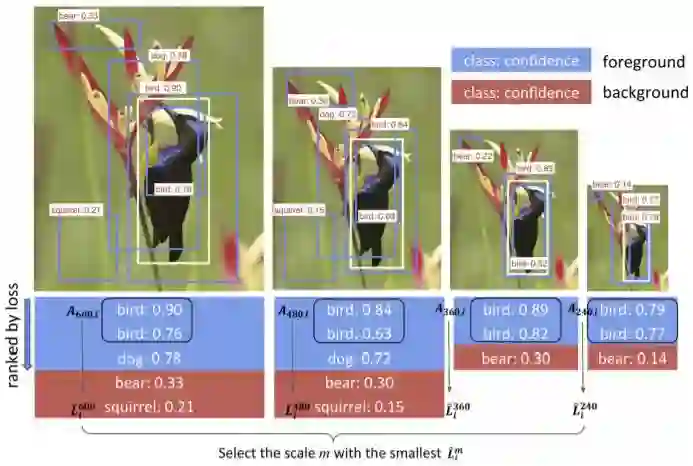
图 3:决定最优尺寸。首先,根据 4 个尺寸选择相同数量的预测前景。然后,选择损失最低的尺寸作为最优尺寸。
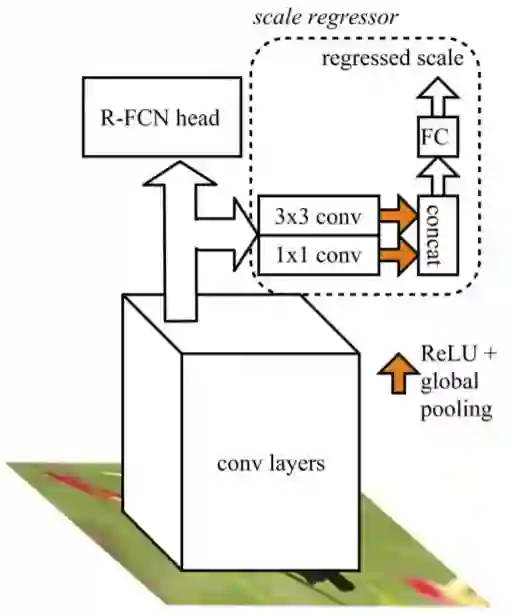
图 4:尺寸回归模块
为了将自适应缩放(AdaScale)整合进视频环境中,我们施加了一个时间一致性假设。更确切地说,我们假设两个连续帧的最优尺寸是相近的,我们的实验结果也验证了这一假设。算法 1 是一个利用 AdaScale 进行视频目标检测的例子。

算法 1:在测试阶段使用 AdaScale 的伪代码
实验

图 5:几种类别的精度-回调曲线,MS/AdaScale 在 (a)(b)(c) 中有更好的性能,在 (d) 中性能相当,在 (e)(f) 中相较 SS/SS 更差
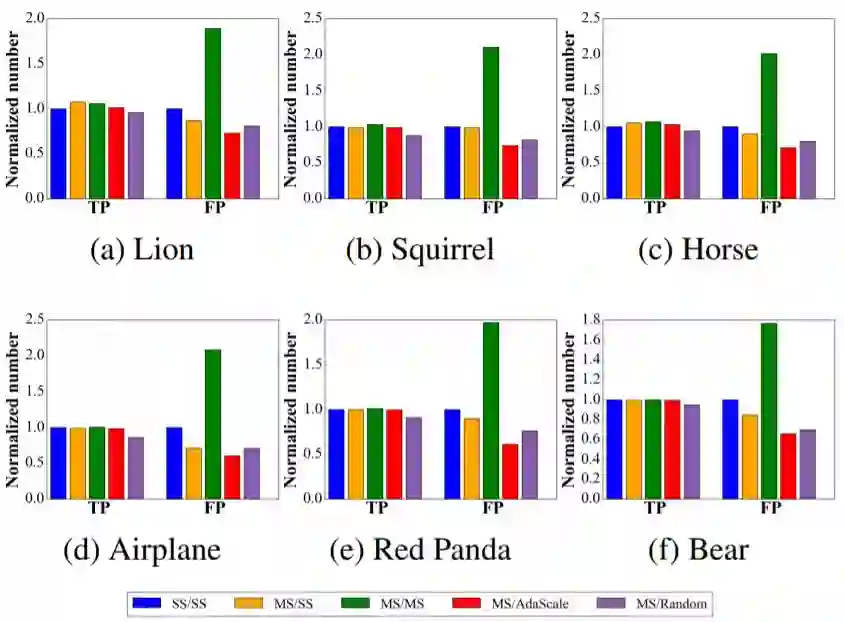
图 6:在验证集中的所有图像上,不同方法在这些类别上得到的归一化的真正例和假正例情况
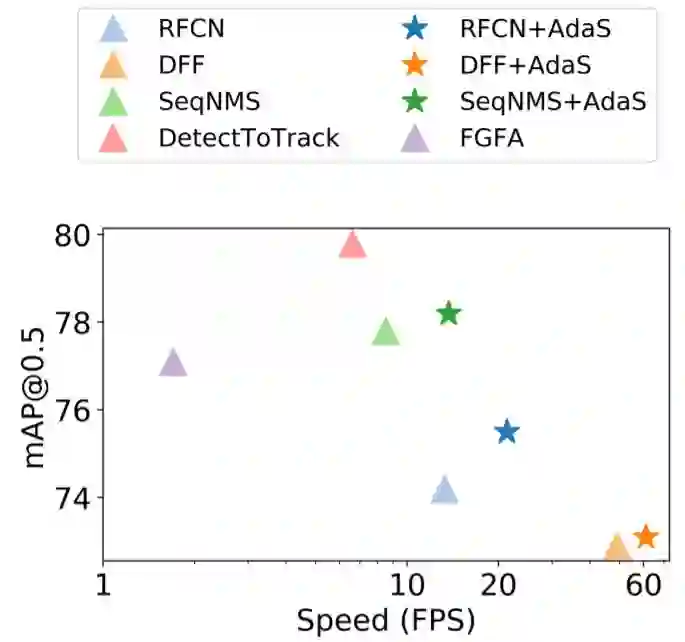
图 7:在 ImageNet VID 数据集上与之前最佳方法的 mAP 和速度比较。将我们的 AdaScale 应用于 RFCN (Dai et al., 2016)、DFF (Zhu et al., 2017a) 和 SeqNMS (Han et al., 2016) 时都能实现进一步的速度和准确度提升。

图 8:SS/SS 和 MS/AdaScale 结果的定性比较。(a) 和 (c) 列是 SS/SS 得到的结果,(b) 和 (d) 是 MS/AdaScale 得到的结果。MS/AdaScale 使用的尺寸标注在黑底白字矩形框中。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


