【干货】模仿人类的印象机制,商汤提出精确实时的视频目标检测方法
【导读】最近,针对视频目标检测中速度精度难以两全的问题,来自商汤科技(SenseTime)的学者发表论文提出一个新的概念——印象网络,其体现出了自然高效的特征聚合机制。本文的框架通过迭代吸收稀疏的关键帧特征来建立印象特征。印象特征一直沿着视频传播,有助于增强低质量帧的特征。这种印象机制能够将稀疏的关键帧进行远距离的特征融合,并且使融合的过程开销最小。所提出的方法在ImageNet VID上进行了评估,取得了非常好的效果并且具备实时性(20fps)。代码将开源。
论文:Impression Network for Video Object Detection

▌摘要
与图像目标检测相比,视频目标检测更具挑战性。以前的工作证明:对视频逐帧应用目标检测器不但速度慢,而且不准确。在视频中由于运动和虚焦导致目标出现视觉模糊现象,进而使相应帧的检测失败。多帧特征融合方法(Multi-frame feature fusion methods)能够提高检测精度,但是其以牺牲速度为前提。基于特征传播的方法(Feature propagation based methods)能够提高检测速度,但是它牺牲了准确性。那么是否可以同时提高速度和检测性能呢?
受到人们如何从模糊的帧中利用印象识别对象的启发,本文提出了印象网络(Impression Network),其体现了自然和高效的特征聚合机制。在提出的框架中,通过迭代吸收稀疏的帧特征来建立印象特征。印象特征一直沿着视频传播,有助于增强低质量帧的特征。这种印象机制能够将稀疏的关键帧进行远距离的特征融合,并且使融合的过程开销最小。它显著提升了ImageNet VID中逐帧进行检测的方法,同时速度提高了3倍(20 fps)。 本文希望印象网络能够为视频特征增强提供新的解决思路,将提供本文的代码。
▌详细内容
快速准确的视频目标检测方法在很多场景下都很有价值。 像Faster R-CNN 和R-FCN 这样的单图像检测器在静态图像上取得了非常好的精度,所以一种很自然的想法是将它们应用于视频中。一种直观的方法是在视频中逐帧应用这些方法,但这并不是最好的。首先,图像检测器通常涉及到大型的特征网络(像ResNet-101 这样的网络),即使在GPU上运行也很慢(5fps)。
这妨碍了视频目标检测在自动驾驶和视频监控等实时场景中的应用。其次,单图像检测器容易受到视频中图像退化问题(这是很常见的问题)的影响。如图2所示,图像帧可能会受到虚焦、运动模糊、对象位置异常等因素影响,其使得图像的视觉线索太弱以至于难以进行对象检测。因此,上述两个问题使视频目标检测任务具有挑战性。

图2:视频中变差的帧的示例
特征级方法可以针对上述两个问题给出解决方案。这些方法将单图像识别过程分为两个阶段:1. 图像通过通用特征网络进行特征提取; 2. 然后,子网络(具有特定任务的子网络)生成结果。当将图像检测器转换为视频检测器时,特征级方法致力于改进特征阶段(第一阶段),而任务网络(第二阶段)保持不变。任务的独立性使得特征级的方法多样话且概念简单。为了提高速度,特征级方法在第一阶段重用稀疏采样的深度特征,因为邻近的视频帧有很多冗余信息。这节省了特征网络推断的时间,使检测速度达到实时的标准,但牺牲了准确性。
另一方面,通过多帧特征融合可以提高准确性,使得检测器能够检测到低质量的帧,但是多帧特征融合成本可能很高,从而进一步降低了框架的运行速度。在本文的工作中,作者结合了二者的优势,提出了一个新的特征级框架,它具有实时的检测速度,并且准确率能超过逐帧检测方法。
提出的印象网络受到人类对视频的理解方式的启发。当出现一个新的帧时,人类不会忘记以前的帧。相反,这个印象是随着视频的积累产生的,这有助于在有限的视觉线索中理解退化帧(degenerated frames)。这种机制使提出的方法能提高帧的特征和准确性。文中还将其与稀疏关键帧特征提取方法相结合,以获得实时的检测速度。提出方法的流程如图1所示。
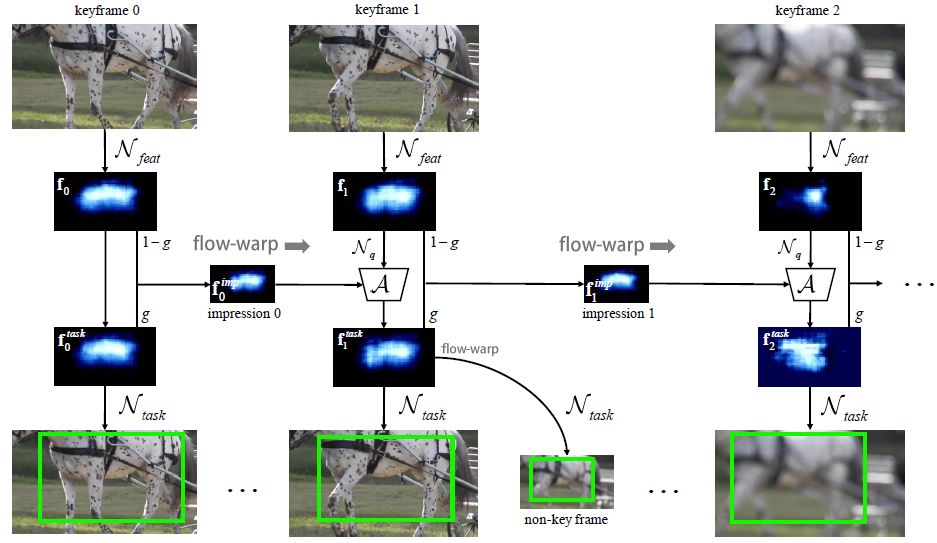
图1:印象网络推断流程。只显示前三个片段的关键帧。顶层特征图的第581个通道(对马敏感)被可视化。关键帧2处因为虚焦而导致检测失败(图5),但是印象特征将前面帧的信息传递过来,并增强f2,因此仍然能够正确预测。
为了解决冗余和提高速度,本文将视频分成长度相等的片段。对于每个片段,只选择一个关键的帧进行深度特征提取。利用光流指导(flow-guided)特征传播,关键帧特征被非关键帧重复使用。基于此,本文采用印象机制(Impression mechanism)进行多帧特征融合。当提取关键帧特征(key feature)时,不仅要送入任务网络,而且还被印象特征(impression feature)吸收。然后特征向下传播到下一个关键帧。
下一个关键帧的任务特征(task feature)是其自身特征和印象特征的加权组合,并通过吸收该特征来更新印象特征。这个过程持续到整个视频结束。在这个框架中,印象特征积累了高质量的视频对象信息并且一直向后传播,有助于增强传入的关键特征。它提高了任务特征的整体质量,从而提高了检测的准确性。
印象机制也有助于提升速度。通过迭代聚合策略,可以最大限度地降低特征融合的成本。 先前的工作[33]已经证明,视频帧特征应该在聚集之前与光流指导(flow-guided)的warping在空间上对齐,而光流的计算是不可忽略的。直观的方式需要对每个帧进行一个光流估计,而印象网络(Impression Network)只需要对相邻片段进行一次额外的流量估算,使其效率更高。
印象网络没有花里胡哨的修饰,却在ImageNet VID 数据集上超越了目前最先进的图像检测器。其速度提高了三倍(20 fps),并且准确度更高。本文希望印象网络能够为视频检测任务中的特征聚合提供新的视角。
▌方法简介
本文的算法流程如下所示:

给定一个视频,这次的任务是产生这个视频每一帧上的检测结果。为了避免冗余的特征计算,本文将帧序列以长度l进行划分。每个划分中只有一个关键帧通过特征网络提取特征。
关键帧特征通过flow-guided warping传播到剩余帧中,其中光流是通过一个轻量级的光流网络进行计算的。最后,所有帧的特征被送入任务网络,产生最终的检测结果。
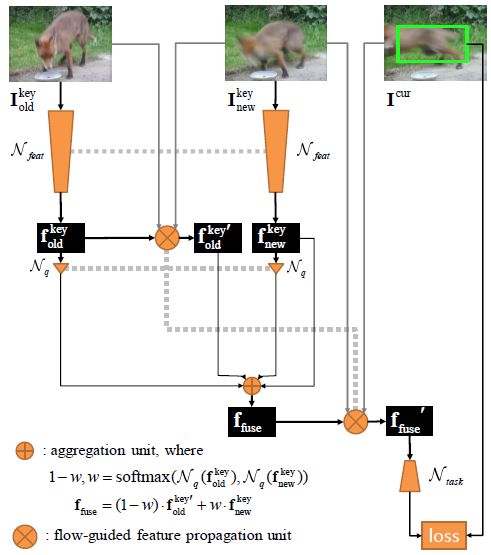
图3:印象网络的训练框架。数据流用实线标记出来。用虚线连接的组件之间共享权值。图中,利用三个视频帧对推断阶段的工作流程进行了模拟。所有的组件都进行端到端优化。
▌实验结果

图4:使用不同聚合权重分配帧的示例。白色数字表示用algorithm 1对加权像素进行空间平均。清晰的图像帧被分配到较大的权重,这使符合直觉的。

图5:印象网络好于逐帧的基准方法(标准ResNet-101 R-FCN)的示例。绿色框表示正确的,红色框表示错误的。
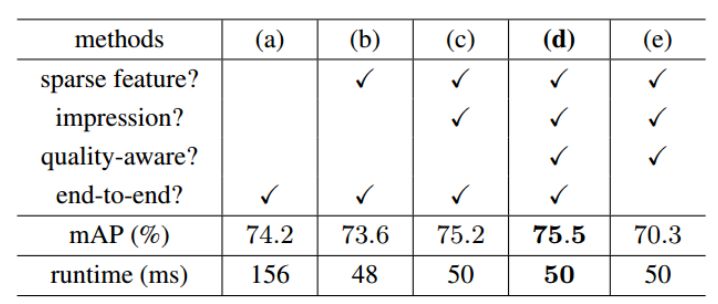
表1:不同方法的准确率和运行时间对比。
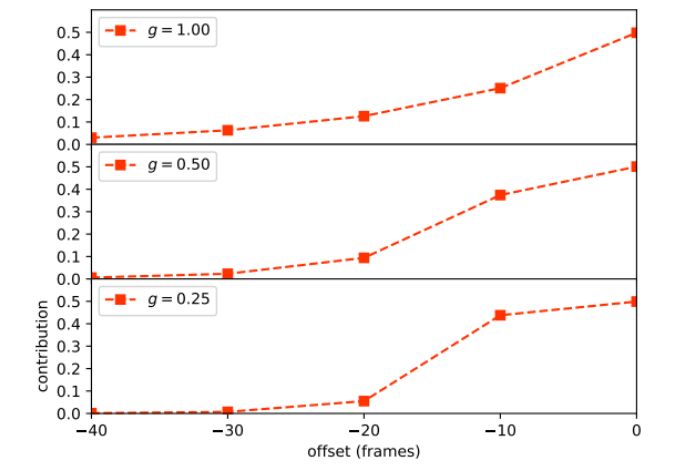
图6:先前的关键帧在不同记忆门g处对检测的平均贡献。 当g为1.0时,贡献值随着偏移值的增大而平滑下降。 随着g的减小,印象越来越多地被最近的关键帧占据,而早期的关键帧迅速缩小到0。
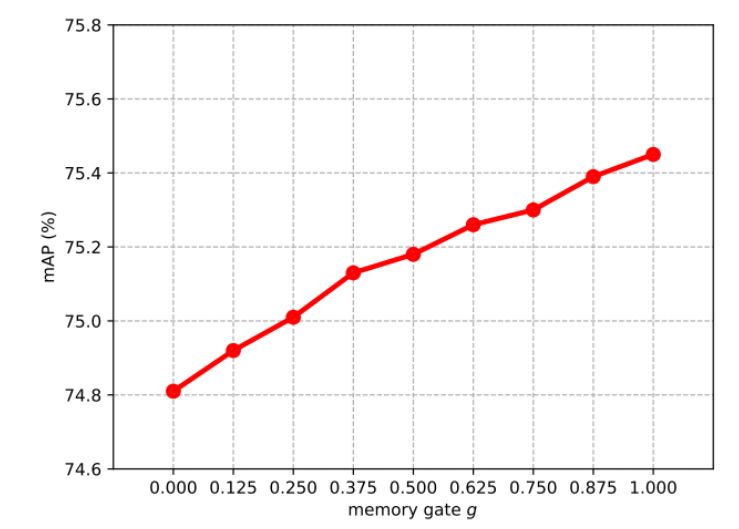
图7:在不同的g值时的mAP得分。 尽管网络训练并不总是如图中一样,但是启用远程聚合确实带来了显着的改善。
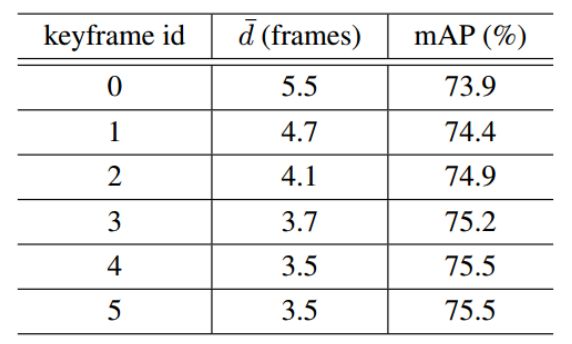
表2:选择不同的关键帧得到的平均传播距离和mAP值。其他设置保持一致(具体如表1).因为对称性,只显示关键帧id从0-5的结果。
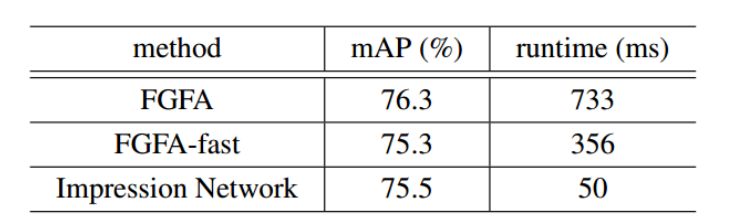
表3:用提出的印象网络与基于聚合的方法FGFA及其更快的变体FGFA-fast进行比较。其中的设置与表1中的方法(d)相同。
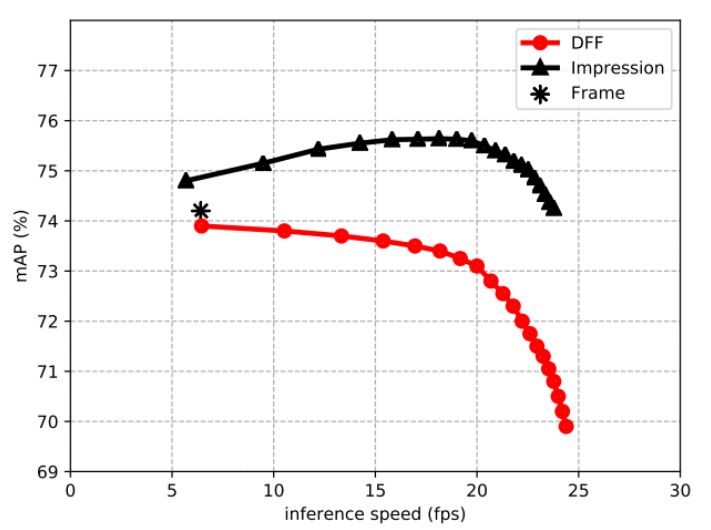
图8:比较深度特征光流(DFF)和印象网络的速度-精度(speed-accuracy)曲线。两者都使用ResNet-101作为特征网络,FlowNet-S作为光流网络(flow network)。
▌结论
本文提出了一个快速和准确的特征级(feature-level)的视频对象检测方法。所提出的印象机制利用了一种新颖的视频特征聚合方案。由于印象网络在特征阶段(第一阶段)工作,所以它与现有的box-level后处理方法如Seq-NMS 是可以互补的。 现在文章中使用FlowNet-S 来指导特征传播以便进行清晰的比较,使用更高效的光算法肯定会使提出的方法受益。 为了简单,文本使用固定的片段长度,当然,使用自适应的长度可以更合理地调度计算。作为一种特征级的方法,印象网络具有任务独立性(task-independence),并有可能解决其他视频任务中的图像退化问题。
参考链接:
https://arxiv.org/abs/1712.05896
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!