NeurIPS 2022 | 赋能产业界的人工智能研究新趋势

(本文阅读时间:11分钟)
自动强化学习辅助损失函数设计

论文链接:
https://www.microsoft.com/en-us/research/publication/reinforcement-learning-with-automated-auxiliary-loss-search/
项目主页:
https://seqml.github.io/a2ls/
强化学习算法通常面临稀疏奖励、高维输入情况下优化稳定性较差等训练问题。为此,研究者们根据经验提出了多种辅助损失函数,以帮助强化学习进行训练。然而,这些人工设计的辅助损失函数十分依赖人类知识,且设计过程耗时费力;同时,由于未考虑强化学习的原本优化目标,这些损失函数在函数空间中都属于次优解。
为了解决这些问题,微软亚洲研究院的研究员们提出了自动强化学习的框架 A2LS,在包含现有人工设计的损失函数的空间(复杂度约为7.5×10^20)中,使用基于元学习的自动化算法自动搜索更优的辅助损失函数。算法在三个随机选择的机器人训练环境中经过4至7轮的搜索后,找到了一个较优的辅助损失函数 A2-winner。广泛的实验结果证明,该辅助损失函数不仅能大幅提升强化学习的训练效果,而且显著优于人工设计的辅助函数,其在多种不同的场景下具有优秀的迁移泛化性,包括从未在训练环境中见过的:(1)基于图像的环境;(2)不同的场景例如游戏场景;(3)不同的状态类型;(4)不同的策略网络结构;(5)部分状态可见(partial observable)的场景。论文原文中还提供了更多视角的对比分析,表明算法的特点与搜索结果的优越性。
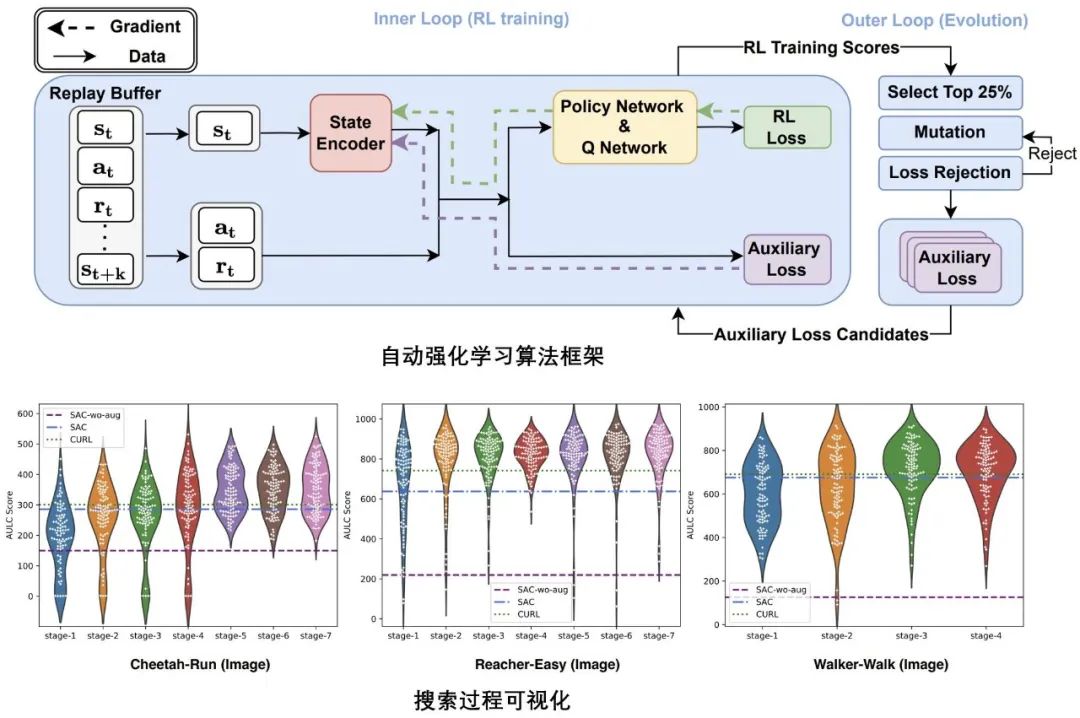
图1:自动强化学习算法框架(上);搜索过程可视化图(下)
自提升离线强化学习

论文链接:
https://www.microsoft.com/en-us/research/publication/bootstrapped-transformer-for-offline-reinforcement-learning/
项目主页:
https://seqml.github.io/bootorl/
随着强化学习在真实世界场景中的需求逐渐增大,作为一种新的强化学习训练范式,离线强化学习(offline reinforcement learning)受到了越来越多的关注。离线强化学习利用预先保存的智能体与环境的交互数据进行离线训练,进而获得可用于在线真实环境的智能体。目前较受关注的一个离线强化学习技术分支是引入 Transformer 模型做序列建模,并取得了良好的成效。
现有的离线强化学习数据存在两个问题,第一是覆盖率的问题,主要由于采样获得这些离线数据的智能体可能是任意的智能体,难以保证离线数据对强化学习真实的数据分布具备良好的覆盖;第二是训练数据量的问题,相比较自然语言处理预训练模型动辄上百万文本语句的语料库相比,离线强化学习的训练数据量一般较小。
根据目前 Transformer 模型序列建模与生成的特性,微软亚洲研究院的研究员们提出了自提升的离线强化学习训练框架 Bootstrapped Transformer(简称BooT)以解决上述问题。BooT 方法建模了离线训练数据的分布并同时生成了新的符合分布的数据以反哺训练过程。在通用的离线强化学习基准中,BooT 显著提升了效果,甚至超越了使用80倍数据量的其他预训练方案;量化与可视分析均表明 BooT 生成的数据更加符合原始数据分布,并能弥补原有离线训练数据的不足。
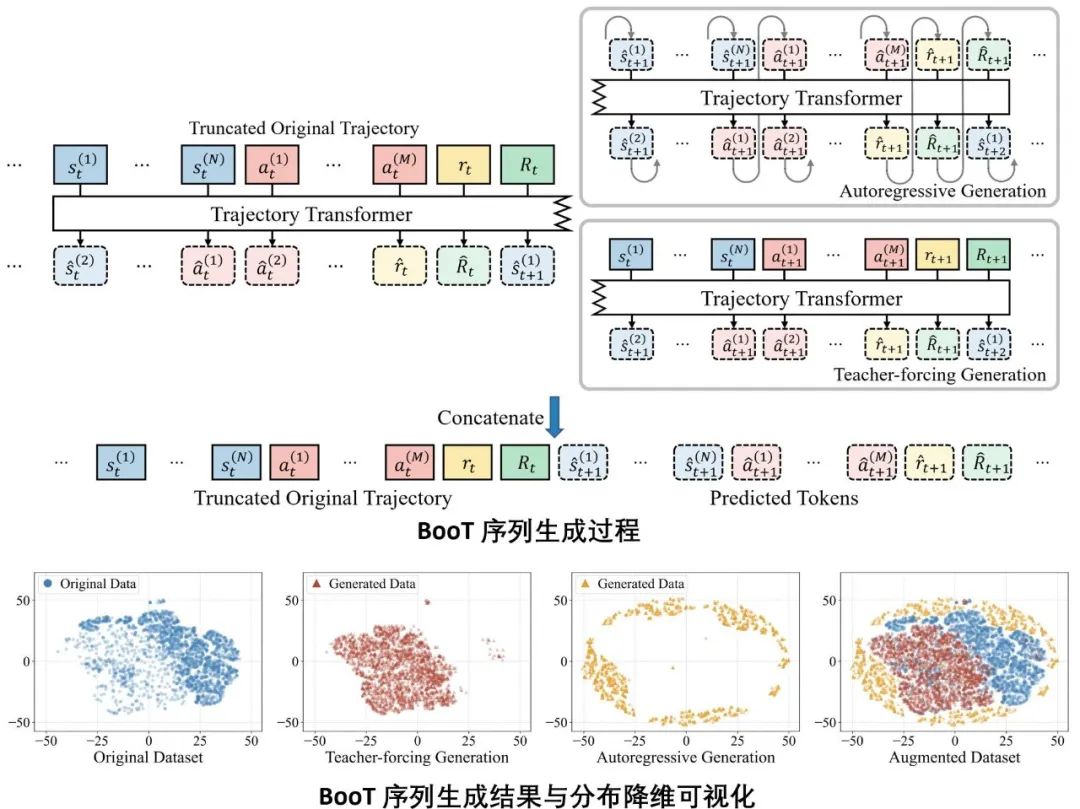
图2:BooT 序列生成过程(上);BooT 序列生成结果与分布降维可视化(下)
面向具有分段稳定上下文的非平稳环境的自适应深度强化学习

论文链接:
https://www.microsoft.com/en-us/research/publication/an-adaptive-deep-rl-method-for-non-stationary-environments-with-piecewise-stable-context/
在现实生活中,智能体处在不断变化的环境中。这是阻碍强化学习算法成功应用的原因之一。在很多现实问题中,环境(例如网络可用带宽、机器人所处地形等)会在一段随机的时间内保持不变,随后以不可预测的方式发生突然跳变。这些环境变量往往不可观测。因此,智能体需要及时检测到这种变化,并快速调整自身策略以适应这种变化。然而现有工作的建模方式都不能很好地解决当前问题。
为此,微软亚洲研究院的研究员们提出了一种新的 Latent Situational MDP (LS-MDP),引入了环境变量 C 以及环境变量结构 G 来细致地刻画问题的结构,并提出了 SeCBAD(segmented context belief augmented deep RL)算法,以联合推断环境变量结构及内容的方式,来完成对环境变化的快速检测。同时,研究员们还使用推断的环境变量 belief 对 state 进行增广,从而使得智能体可以在收集更多信息、与利用已有信息最大化回报这两种策略间达到最优权衡。在机器人控制、网络带宽控制等应用上对该算法的实验结果表明 SeCBAD 能够显著提升性能。
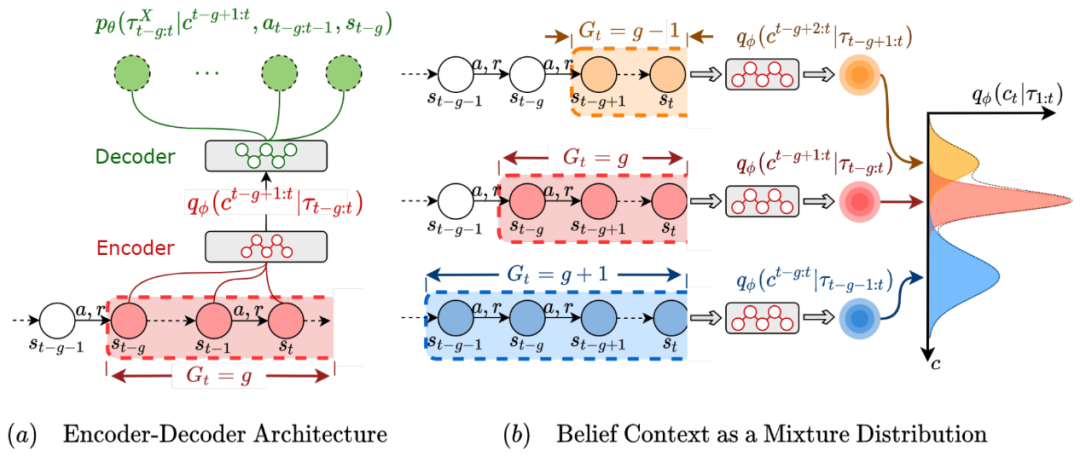
图3:SeCBAD 算法框架图
基于多模态时序对比学习的长视频-语言预训练

论文链接:
https://www.microsoft.com/en-us/research/publication/long-form-video-language-pre-training-with-multimodal-temporal-contrastive-learning/
项目主页:
https://github.com/microsoft/XPretrain
以往对视频-语言预训练的研究主要集中在短视频(即30秒内的视频)和句子上,忽略了真实场景中更加常见的长视频理解。直接从长视频和语言中学习表征可以帮助许多长视频-语言理解任务的发展,但远程关系建模的难度和更多帧引起的计算负担极具挑战性。
在本文中,研究员们提出了 Long-Form VIdeo-LAnguage 预训练模型(LF-VILA),并在基于视频文本数据集 HD-VILA-100M 构建的大规模长视频和段落数据集 LF-VILA-8M 上进行了训练。为了有效地捕捉丰富的时序动态,并以有效的端到端的方式更好地对齐视频和语言, LF-VILA 模型中引入了两种新设计。研究员们首先提出了一种多模态时序对比学习(MTC)损失,通过鼓励长视频和段落之间的细粒度对齐来学习不同模态之间的时序关系。其次,提出了一种分层时间窗口注意力(HTWA)机制,以有效捕获长期依赖关系,同时降低 Transformer 的计算开销。
在7个下游长视频语言理解任务(包括段落到视频检索和长视频问答)上对预训练的 LF-VILA 模型进的验证表明,LF-VILA 取得了最好的性能。具体而言,LF-VILA 在 ActivityNet 段落到视频检索任务上取得了16.1%的相对改进,在 How2QA 任务上取得了2.4%的相对改进。LF-VILA 的代码、数据集和预训练的模型将很快在官方项目主页上发布,欢迎关注。
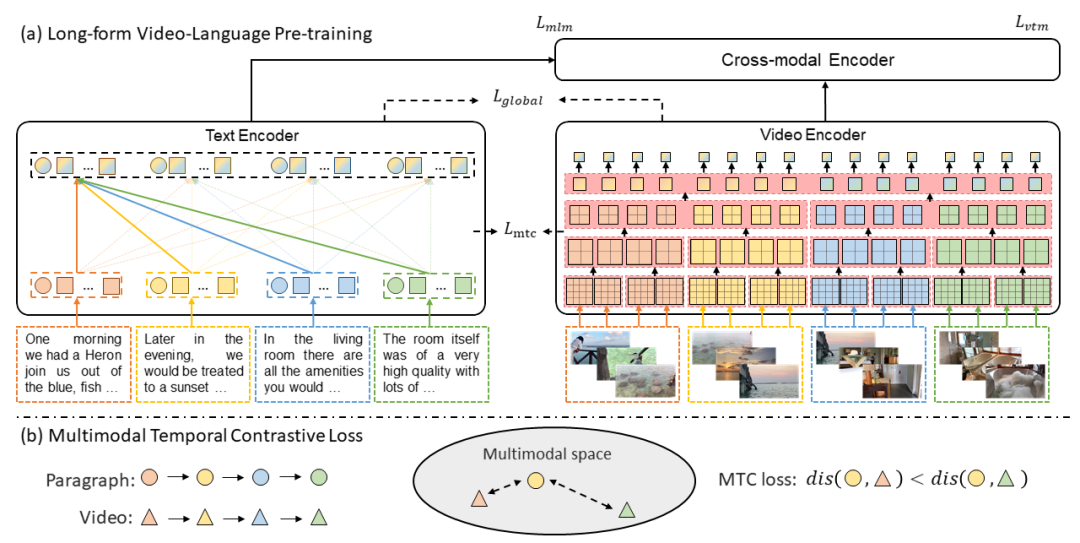
图4:LF-VILA 预训练模型框架图(a)与 MTC 方法示意图(b)
面向多任务分组学习的元学习框架

论文链接:
https://openreview.net/forum?id=Rqe-fJQtExY
多任务学习范式被广泛应用于各种各样的机器学习场景中,包括语言理解、视觉识别、机器人控制、药物发现、临床治疗、能源管理等等。然而,如何有效地选择共同训练的任务组合却是一个极有挑战性的问题,这里有两方面的原因:1)任务组合的数量随着任务数量的增加而成指数级别地增长;2)简单地选择一种分组可能会导致某些任务出现严重的性能衰退。现有的研究工作要么聚焦于给定任务组合情况下的优化方法和模型架构,要么采用一些启发式的方法来应对指数增长的任务组合(比如:将多个任务组合在一起的收益,近似均摊为其两两组合的收益之和)。诸多新进多任务学习研究都认为在任务数量较多时,充分探索这个指数级别增长的任务组合的空间是几乎不可能完成的任务。
为了应对任务组合爆炸增长的挑战,在本文中,研究员们为多任务分组学习提出了一套元学习框架。本文的核心观测在于尽管任务组合的数量随着任务的数量指数增长,但任务组合与在其上做多任务学习带来的增益之间的关系却存在于一个低维的流形空间中。基于此观测,本文定义了一个任务组合上的元学习问题:给定一个任务组合,预测其多任务学习相对于单任务学习所带来的增益。在此元学习问题的基础上,研究员们构建了一个元模型并开发了一套逐步选择元学习样本的训练方法。基于此方法,只需要进行有限次的多任务学习与评估,即可获得一个有效的元模型来准确地预测出所有未知任务组合上多任务学习的增益,进而实现有效的任务分组。
值得注意的是,在视觉、能源、医疗等多种多任务学习场景下验证了以上框架后,一个大规模的实验评测(27个临床医疗预测任务,超过10亿的任务组合)表明:在几乎同等的计算开销下,相对于现有的最佳方案,本文所提出的元学习方法获得了几乎翻倍的性能提升。
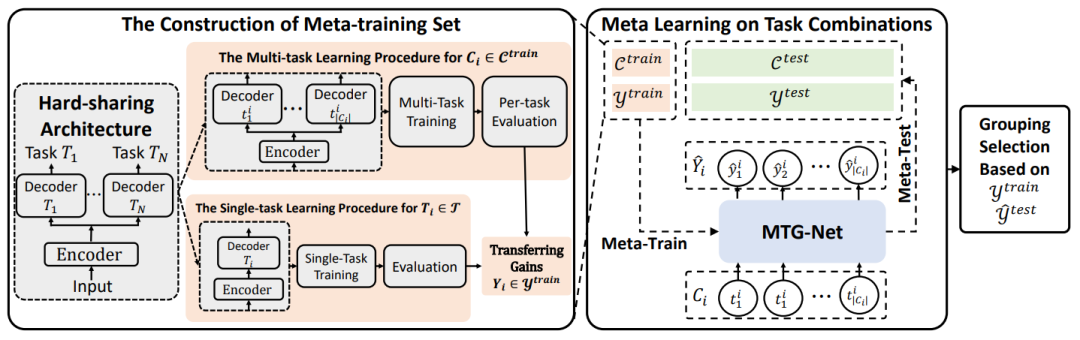
图5:元学习框架图
想要详细了解本期分享的论文?我们准备了微软亚洲研究院 NeurIPS 2022 论文直播分享,邀请你共同探索计算机科学的更多可能!
本次直播分享所选取的论文将采用投票形式选出,位列投票榜前列的论文将于近期在 B 站“微软中国视频中心”账号进行直播,快来支持本期你最感兴趣的论文,为它投上一票吧!
你也许还想看:







