NeurIPS 2021 | 一文洞悉因果机器学习前沿进展

(本文阅读时间:26分钟)
近年来,随着机器学习模型性能的不断提高,人们逐渐不再满足于它们在标准数据集上的表现,而是还希望它们能在真实的应用场景中同样具有稳定可靠的表现。但实现此目的的一个重要挑战是,真实场景中的环境情况通常与干净的标准训练数据集不同,会有数据分布的变化从而会遇到分布外样例,而模型不一定会在新环境中给出合理的结果。
这为机器学习模型带来了新的要求,即模型需要学到做出预测或判断的本质原因和规律,而非依赖于表面“看上去”的关联关系,因为后者可能只是在特定环境下的表象,只有前者决定着环境变化之后的规律,可对分布外样例给出合理的结果。这便引出了因果机器学习这一新的研究方向。在 NeurIPS 2021 上,微软亚洲研究院的研究员们发表了一系列因果机器学习领域的研究成果。

论文链接:
https://arxiv.org/pdf/2011.01681
代码链接:
https://github.com/changliu00/causal-semantic-generative-model
人们已经发现标准的有监督学习方法,特别是深度学习方法对分布外样例的预测表现欠佳。例如图1中的例子[Ribeiro’16],若训练集中大部分“哈士奇”的图片都是暗背景而大部分“狼”的图片都是雪地背景,那对于处在雪地中的“哈士奇”的测试样例,模型会预测为“狼”。若对模型进行可视化可发现模型更关注于背景,因为在这样的数据集上,背景与前景物体具有很强的关联性,并且背景是一个比前景物体更有区分度的特征,但只有前景物体决定图片的标注。

图1:分布外预测任务的挑战
所以,微软亚洲研究院的研究员们希望模型能够学到类似于前景物体这样的特征进行预测。此目标可在因果关系理论下进行正式的描述。该理论是通过系统在干预(intervention)下的表现来定义因果关系的,即若通过干预改变变量 A 的值会改变变量 B 的值而干预 B 不会改变 A,那 A 就是 B 的因(cause),B 就是 A 的果(effect),记为 A→B。例如,海拔更高的城市的平均气温通常都比较低,但单从这样的“海拔-气温”成对(pair)数据中并不能知道谁是因谁是果。人们知道海拔是气温的因,是因为若用一个大型举重机把一个城市举起,升高它的海拔,那它的气温会下降,而若用一个巨大的加热器升高城市的温度,那这个城市并不会自动下沉。同理,若强行改变一张图 x 的背景而维持前景物体不变,那这张图的标注 y 不应改变,而改变前景物体却会改变 y。所以研究员们希望模型学到的是标注 y 的因,称为“语义因子”(semantic factor)s,如前景物体,而相区别的是“多变因子”(variation factor)v,如图片背景。只有将 s 识别出来才能做好分布外预测(out-of-distribution prediction)。
基于这个因果角度的考虑,研究员们提出了“因果语义生成模型”(Causal Semantic Generative model, CSG),如图2(a)所示(注意基于前面的考虑,图中去掉了v→y)。此外,根据上面的例子,s和v在特定环境中常会相关,例如“哈士奇”/“狼”常与暗背景/雪地背景一起出现,但此相关性并非因为两者间有因果关系,比如把“哈士奇”放到雪地中不会让它变成“狼”,也不会把背景变暗。因此研究员们使用了一个无向边来连接它们。这不同于大部分已有工作,那些工作认为各隐因子间都是独立的。

图2:因果语义生成模型(a)及其用于测试域的变种(b,c)
因果不变性与分布外预测
这个体现因果性质的模型可帮助做好分布外预测。其出发点是 “因果不变性”(causal invariance),即因果关系不会随环境或领域(domain)变化。这是因为因果关系反映的是基本的自然规律,例如一个场景下的物体和背景通过相机成像为图片的过程,即 p(x│s,v),以及从物体的本质特征给出标注的过程,即 p(y│s)。领域变化则源于先验分布 p(s,v) 的变化,例如训练环境下的 p(s,v) 会给(“哈士奇”, 暗背景)以及(“狼”, 雪地背景)较大的值,而测试环境则相反。
作为对比,当前主流的领域自适应和领域泛化方法会在不同领域上使用同一个编码器来推断隐因子。这其实蕴含着“推断不变性”(inference invariance)。研究员们认为,推断不变性是因果不变性的特例。在支持推断不变性的例子中,比如从图片中推断物体位置,具有因果性的生成机制 p(x│s,v) 几乎是确定性的且可逆的,意味着只有一个“物体位置”的值(s 的一个分量)才能让 p(x│s,v) 对于给定的 x 非零。由于 p(x│s,v) 具有因果不变性,所以这种推断方式便也具有不变性。但当 p(x│s,v) 有噪或退化时,仅依据 p(x│s,v) 做推断是任意的,例如图3左图中的数字可能是由“5”也可能是由“3”产生的,而右图中,靠近我们的不论是 A 还是 B 面都会得到同样的图。这种情况下,由贝叶斯公式 p(s,v│x)∝p(s,v)p(x│s,v) 给出的推断结果便会明显受到先验的影响。而先验是会随环境变化的(对可能的推断结果的偏好因人而异),所以推断不变性不再成立,而因果不变性却仍然可靠。
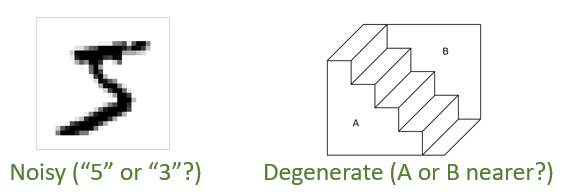
图3:当生成机制 p(x│s,v) 有噪(左)或退化(右)时,推断结果具有任意性,因而推断不变性不再可靠
基于因果不变性,研究员们给出了在测试域(test domain)上进行预测的原则。本篇论文考虑了两种分布外预测任务,称为“分布外泛化”(out-of-distribution generalization)以及“领域自适应”(domain adaptation)。两者都只有一个训练域(training domain)(因而分布外泛化不同于领域泛化;下一篇工作会解决领域泛化任务),但领域自适应中有测试域上的无监督数据,而在分布外泛化中则对测试域一无所知。
由因果不变性可知,在测试域上,具有因果性的数据生成机制 p(x│s,v) 和 p(y│s) 仍然适用,但先验分布会发生变化。对于分布外泛化则需要考虑测试域先验的所有可能性。因此,研究员们提出了适用一个独立的先验分布 p^⊥ (s,v)≔p(s)p(v),其中 p(s) 和 p(v) 都是训练域先验 p(s,v) 的边缘分布。此选择去掉了 s 和 v 在训练域上的虚假关联(spurious correlation),并且由于 p^⊥ (s,v) 具有比 p(s,v) 更大的熵,因此减去了独属训练域的信息,从而让模型更依赖于具有因果不变性的生成机制进行预测。这种预测方法被称为 CSG-ind。对于领域自适应,可利用无监督数据学习测试域的先验 p ̃(s,v) 用于预测,其对应方法称为 CSG-DA。这两个模型示于图2(b,c)中。值得注意的是,由于 CSG 在测试域上使用了与训练域不同的先验分布,在测试域上得到的预测规则 p(y│x) 会不同于训练域上的,因而此方法与基于推断不变性的方法严格不同。
方法
事实上,无论哪种方法都首先需要很好地拟合训练数据,因为这是所有监督信息的来源。由于 CSG 涉及隐变量,难以直接计算数据对数似然 logp(x,y) 用于训练,所以研究员们采用了变分贝叶斯方法(Variational Bayes)优化一个可以自适应变紧的下界,记为ELBO(Evidence Lower BOund)。虽然标准做法要引入形如 q(s,v│x,y) 的推断模型(inference model),但它却并不能帮助进行预测。为此,研究员们考虑用一个形如 q(s,v,y│x) 的模型表示所需推断模型 q(s,v│x,y)=q(s,v,y│x)/∫q(s,v,y│x) dsdv。进一步,将它代入 ELBO 中可发现,这个新的 q(s,v,y│x) 模型的目标正是由 CSG 模型所定义的对应分布 p(s,v,y│x),而由 CSG 的图结构,这个分布可分解为 p(s,v,y│x)=p(s,v│x)p(y│s),其中的 p(y│s) 已由 CSG 模型显式给出,只有 p(s,v│x) 是难以计算的项。因此研究员们最终采用了一个形如 q(s,v│x) 的推断模型以近似这个最小的难算部分 p(s,v│x),代入 ELBO 中即得训练目标。
对于 CSG-ind,它一方面需要针对独立先验 p^⊥ (s,v) 的推断模型 q^⊥ (s,v│x) 用于预测,另一方面也需要训练域上的推断模型 q(s,v│x) 用于训练。为避免使用两个推断模型的麻烦,研究员们发现可用 q^⊥ (s,v│x) 表示 q(s,v│x)。这是因为这两个模型分别以 CSG 所定义的 p(s,v│x) 及 CSG-ind 所定义的 p^⊥ (s,v) 为目标,根据两者的关系,取 q(s,v│x)=(p(s,v) / p^⊥(s,v)) (p^⊥(x) / p(x)) q^⊥(s,v|x),这样当 q^⊥ (s,v│x) 达成目标时,对应的 q(s,v│x) 也达成了目标。将此式代入 ELBO 中得到 CSG-ind 的训练目标为:
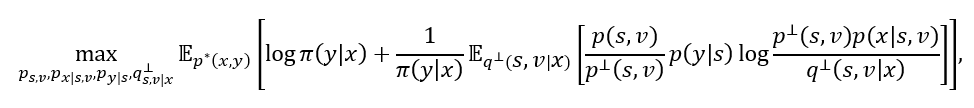
其中 π(y│x)≔E_(q^⊥ (s,v│x) ) [p(s,v)/(p^⊥ (s,v) ) p(y│s)]。式子中的期望可在对 q(s,v│x) 进行重参化(reparameterization)后用蒙特卡罗(Monte Carlo)方法估计。预测由 p^⊥ (y│x)=E_(p^⊥ (s,v|x) ) [p(y│s)]≈E_(q^⊥ (s,v|x) ) [p(y│s)]给出。
对于 CSG-DA,它与 CSG-ind 类似,所以研究员们也用测试域上的推断模型 q ̃(s,v│x) 来表示 q(s,v│x),并类似地写出训练域上的目标函数。CSG-DA 在测试域上还需要通过拟合无监督数据来学习测试域先验 p ̃(s,v),这可由标准的 ELBO 实现:
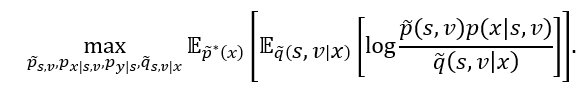
理论
可以证明的是, CSG 模型在一定条件下可从单个训练域上识别出语义因子,并且这种语义可识别性可保障 CSG 在分布外预测上的表现(详细描述请参看论文原文)。研究员们将“CSG 识别出了语义”定义为,存在一个可从真实(ground-truth)CSG 变换到该 CSG 的重参(reparameterization)满足它不会将真实的v混到所学的s中去。
定理(单训练域上的语义可识别性):假设 p(x│s,v) 和 p(y│s) 是加性噪声(additive noise)形式 p_噪声 (随机变量-函数(条件变量)),且其中的函数是双射,并且 logp(s,v) 有界。那当噪声方差 σ_μ^2 趋于0或者噪声有几乎处处非零的特征函数时,一个学好了的 CSG(即 p(x,y)=p^* (x,y))识别出了语义。
解读:在单训练域上取得识别性很难,所以必定会对它有要求。否则,若训练域中所有“哈士奇”都在暗背景中且所有“狼”都在雪地中,那就算是神仙也不知道标注标的是前景物体还是背景。定理中 logp(s,v) 有界的条件正是针对这一点,因为在上述情况下 p(s,v) 集中在 (s,v(s)) 曲线上因而密度函数无界。而若此有界条件满足,那当所学 CSG 将真实的 v 混入其 s 中时,真实 s 和 v 间的随机性会对训练集上的预测带来更大的噪声,从而使这个 CSG 不是“学好了的”。这是此定理的直觉。
定理(语义识别对分布外泛化的保障):一个识别了语义的 CSG 在一无所知的测试域上的预测误差有界:E_(p ̃^* (x) ) ‖E[y│x]-E ̃^* [y│x]‖_2^2≤Cσ_μ^4 E_(p ̃_(s,v) ) ‖∇ log(p ̃_(s,v)/p_(s,v) ) ‖_2^2(其中 C 是一个特定常数)。
定理中研究员们发现 E_(p ̃_(s,v) ) ‖∇ log(p ̃_(s,v)/p_(s,v) ) ‖_2^2 这一项正是衡量两个领域上先验分布差别的费舍尔散度(Fisher divergence)D_F (p ̃_(s,v),p_(s,v) ),它在预测误差的意义下衡量了两个领域的差别程度。另外,更小的费舍尔散度 D_F (p ̃_(s,v),⋅) 需要比 p ̃_(s,v) 有更大支撑集的分布,而 p_(s,v)^⊥ 恰好比 p_(s,v) 有更大的支撑集,这说明 CSG-ind 比 CSG 有更小的预测误差界!
定理(语义识别对领域自适应的保障):基于一个识别了语义的 CSG 的学好了的(即 p ̃(x)=p ̃^* (x))测试域先验 p ̃(s,v) 是真实的测试域先验 p ̃^* (s,v) 的重参,并且基于它给出的预测规则是准确的,即 E ̃[y│x]=E ̃^* [y│x]。
实验
研究员们设计了一个只包含数字0和1的“平移 MNIST”数据集,其中训练数据中的0被有噪地向左平移5像素,而1向右。除了原本的测试集,研究员们也考虑将其中的数字用零均值噪声平移。更加真实的任务包括 ImageCLEF-DA,PACS 和 VLCS(附录)。表1中的结果表明,对于分布外泛化,CSG 胜过标准监督学习(cross-entropy,CE)及判别式因果方法 CNBB,同时 CSG-ind 也胜过 CSG,表明了使用独立先验用于预测的好处。对于领域自适应,CSG-DA 也胜过当前流行的方法。图4中的可视化分析表明所提方法更关注图片中有语义信息的区域和形状。
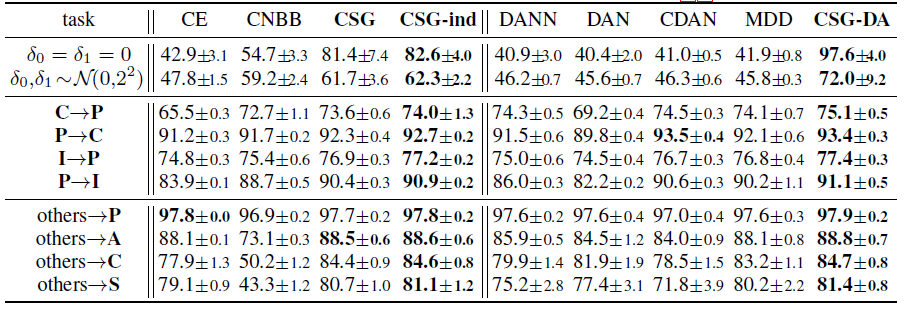
表1:平移MNIST(前两行)、ImageCLEF-DA(中四行)和 PACS(后四行)数据集上分布外泛化(左四列)和领域自适应(右五列)任务上各方法(所提方法加粗)的表现(预测准确度%)

图4:分布外泛化(上两行)及领域自适应(下两行)任务中各方法的可视化结果(基于LIME [Ribeiro’16])

论文链接:
https://arxiv.org/pdf/2011.02203
代码链接:
https://github.com/wubotong/LaCIM
这篇论文将 CSG 模型推广到了多训练域的情况,即用来处理领域泛化(domain generalization)任务,并给出了相应的算法和理论。为了建模与领域标号 d 的关系,此时的先验分布记为 p^d (s,v)。为避免在图模型中以及在算法和理论中暗含给定 d 之后 s 与 v 的独立性,研究员们引入了混淆变量(confounder)c。它解释了 s 与 v 之间的虚假关联(spurious correlation),因为尽管 s 和 v 之间没有因果关系,但若忽略 c,那看上去 s 和 v 就会有相关性:p^d (s,v)=∫p^d (c) p^d (s│c) p^d (v│c) dc。拓展后的模型如图5所示,被称为隐式因果不变模型(Latent Causal Invariant Model,LaCIM)。
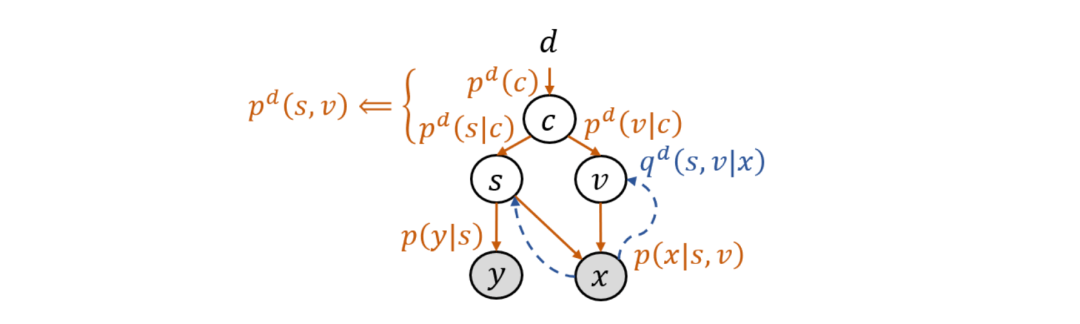
图5:隐式因果不变模型(LaCIM)
LaCIM 的训练方法与 CSG 类似,只是需要对所有训练域上的目标函数求和,并在各训练域上使用各自的先验模型 p^d (s,v) 和推断模型 q^d (s,v│x)。而其预测方法则与 CSG-ind 类似,区别在于推断 (s,v) 不通过一个推断模型,而是直接使用最大后验估计(maximum a posteriori estimate, MAP):p^(d^' ) (y│x)=p(y│s(x) ), 其中 (s(x),v(x))≔argmax_(s,v) p(x│s,v) p^⊥ (s,v)^λ .
理论
由于需要建模各分布与领域标号 d 的关系,理论分析中需要加入更多的结构。因此,假设 c∈[C]≔{1,…,C},且 p^d (s│c) 和 p^d (v│c) 都属于指数分布族(exponential family),进而定义相应的识别性概念,称为指数识别性:存在一个可从真实 LaCIM 变换到所学 LaCIM 的重参,且此重参可在允许一个分量置换和整体平移的意义下分别恢复出真实 p^d (s│c) 和 p^d (v│c) 的充分统计量。
定理(多训练域上的指数可识别性):假设 p(x│s,v) 和 p(y│s) 是特定加性噪声形式,且 p^d (s│c) 和 p^d (v│c) 的充分统计量线性独立。那么当各训练域在特定意义下足够多样时,一个学好了的 LaCIM 就取得了指数识别性。
此定理的结论(取得指数识别性)比单训练域上可识别性定理的结论(取得语义识别性)更强。这体现在,前者不仅要求后者所要求的学到的 s 未混入真实的 v,还要求学到的 v 未混入真实的 s,即要求学到的 s 和 v 是解耦的(disentangled)。之所以能得到更强的结论,是因为多个足够多样的训练域为模型带来了更多的信息,且指数分布族也为模型带来了更具体的结构。另外,此结论也强于 identifiable-VAE [Khemakhem’20] 的结论,因为此结论要求充分统计量的分量置换不能跨越 s 和 v 的内部。
实验
在实验中,研究员们选择了一些最新的领域泛化数据集,包括 NICO 自然图片数据集、彩色 MNIST,以及预测阿尔兹海默症的 ADNI 数据集。表2中的结果表明 LaCIM 取得了最好的表现。可以注意到 LaCIM 也比不区分 s 和 v 的变种 LaCIMz 表现好,说明了将 s 和 v 分别建模的好处。图6中的可视化分析表明,LaCIM 很好地区分开了语义和多样因子,且关注图片中具有语义信息的区域。
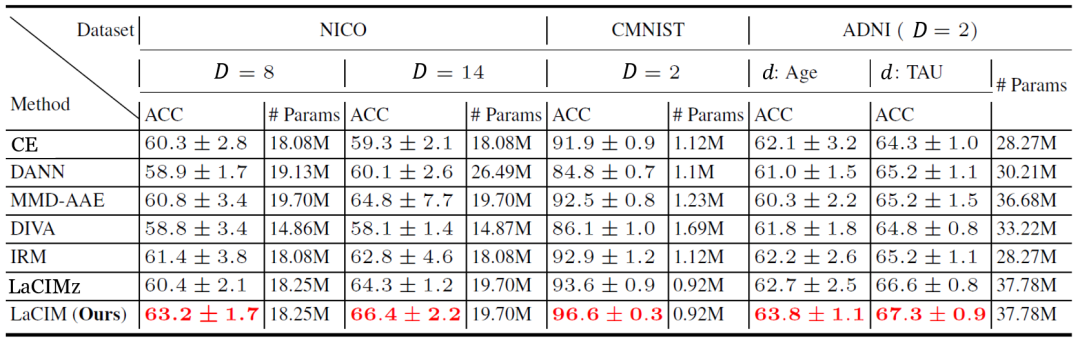
表2: 领域泛化的各数据集上各方法的表现(预测准确度%)

图6:领域泛化任务中各方法的可视化结果

论文链接:
https://arxiv.org/pdf/2110.14118
代码链接:
https://github.com/alinlab/oreo
这一篇因果机器学习的论文关注的是模仿学习(imitation learning)中的因果混淆(causal confusion)问题。模仿学习即为从专家示范中学习策略模型(policy),它可利用已有数据来避免或减少危险或高代价的与环境交互。行为克隆(behavioral cloning, BC)是一种简单有效的方法,它将模仿专家示范看作一个有监督学习任务,即用状态(state)s 预测动作(action)a。然而,该方法常会产生因果混淆问题,即学到的策略关注的是专家动作的明显结果而非原因(即专家策略所关注的对象)。De Haan等人 (2019)举了一个经典例子:考虑司机做驾驶示范的过程,其中车的仪表盘上有刹车指示灯。当视野中出现行人时,司机会采刹车同时刹车灯亮起。由于“a=踩刹车”和“s=刹车灯亮起”总是同时出现,策略模型很可能会仅仅基于刹车灯来决定是否踩刹车,这样可以很好地拟合示范数据,但在使用中当视野中出现行人时,由于刹车灯没有亮,它也仍然不会踩刹车,这显然不是人们希望的。
研究员们发现,因果混淆问题在一般的场景中广泛存在。如图7所示,原本环境下学到的策略表现远不如训练时将分数掩盖掉的好。原环境中,策略模型会仅仅依赖于画面中的分数给出动作,因为它与专家动作的关系紧密而敏感,但却不知这只是专家动作的结果,所以在使用中不能采取有效的动作。而在分数被掩盖的环境中,策略模型不得不寻找其他线索来预测专家动作,才得以发现真实规律。
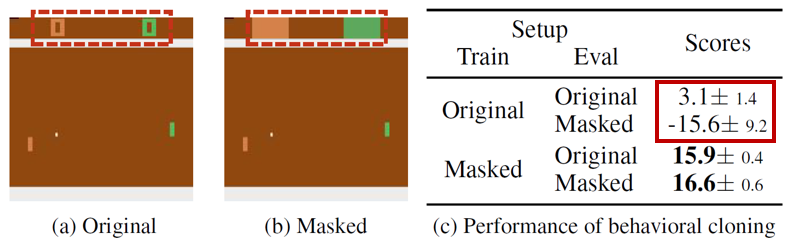
图7:雅达利(Atari)乒乓(Pong)游戏中存在的因果混淆问题
方法
由上述分析,研究员们发现产生因果混淆问题主要是因为策略模型仅仅依赖于画面中的个别对象采取动作,而此对象往往是专家动作所产生的看上去很明显的结果。这启发了研究员们通过让策略模型均衡地关注画面中的所有对象来应对此问题,使策略模型能注意到真正的因。
实现此想法需要解决两个任务:(1)从图像中提取对象。(2)让策略模型注意到所有对象。对于第一个任务,研究员们采用了量子化向量变分自编码器(vector-quantized variational auto-encoder,VQ-VAE)[v.d. Oord’17] 抽取对象特征。如图8所示,研究员们发现,VQ-VAE 学到的离散编码相近的值(相近的颜色)代表了同一(或语义相近的)对象,因此它找到并区分了图像中的对象。

图8:VQ-VAE 学到的离散编码可找到并区分图像中的对象
对于第二个任务,研究员们对每一个离散编码的值随机地决定是否选择它,并在图像的 VQ-VAE 编码中掩盖掉具有所选离散值的格点。此操作掩盖掉了编码中的一些对象,迫使策略模型关注未被掩盖掉的对象,避免仅关注个别对象。这是与现有方法最大的不同,现有方法掩盖掉的都是空间上相近的区域,并不反映具有语义的对象。因此,此方法被称为“察觉对象的正则化方法”(Object-aware REgularizatiOn,OREO)。图9展示了 OREO 方法的流程。第一阶段训练 VQ-VAE 提取对象表示,第二阶段学习基于 VQ-VAE 编码的策略模型,其间通过所述随机掩盖对象的方法做正则化。
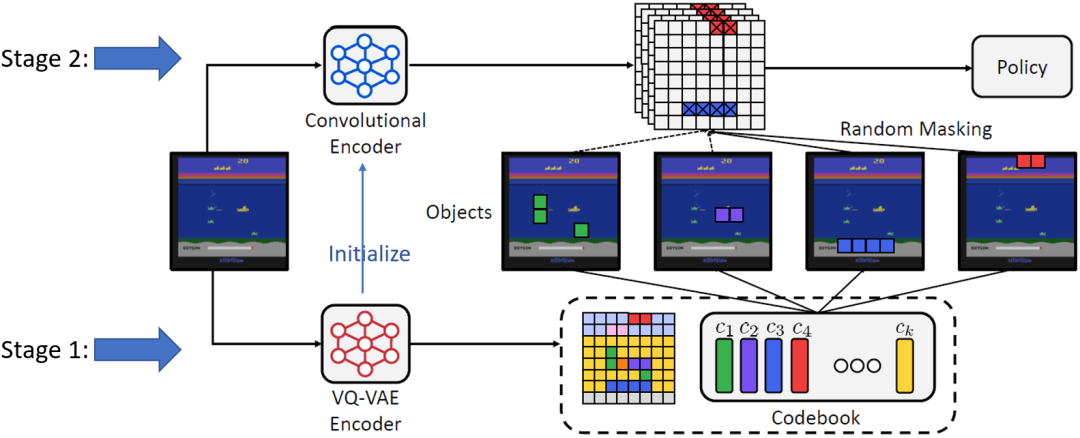
图9:“察觉对象的正则化方法”(OREO)的流程
实验
首先,考虑混淆雅达利游戏(confounded Atari games)环境,这是 De Haan 等人(2019) 所提出的考察因果混淆问题的环境,其中游戏图像的每一帧都额外显示玩家上一步采取的动作。如表3所示,OREO 方法在大部分游戏中都取得了最好的表现。特别地一点,OREO 方法胜过在空间区域上随机掩盖的方法(Dropout, DropBlock)、数据增广(data augmentation)方法(Cutout, RandomShift)、以及空间式地随机掩盖 beta-VAE 所学编码的方法(CCIL)[De Hann’19],说明了用察觉对象的方式进行正则化的优势。OREO 也胜过了因果预测方法 CRLR,说明简单直接地应用因果方法并不一定有效,因为其假设在模仿学习任务中并不成立,例如图像数据各维度间并没有明确的因果关系,且变量关系也非线性。图10的可视化结果表明,行为克隆所学到的策略确实仅关注个别物体,而 OREO 学到的则更广泛地关注图中的相关对象。对于真实场景任务,研究员们也考察了在 CARLA 驾驶模拟环境中的表现。表4中的结果表明 OREO 也取得了最好的表现。论文原文及附录中提供了更多实验结果。
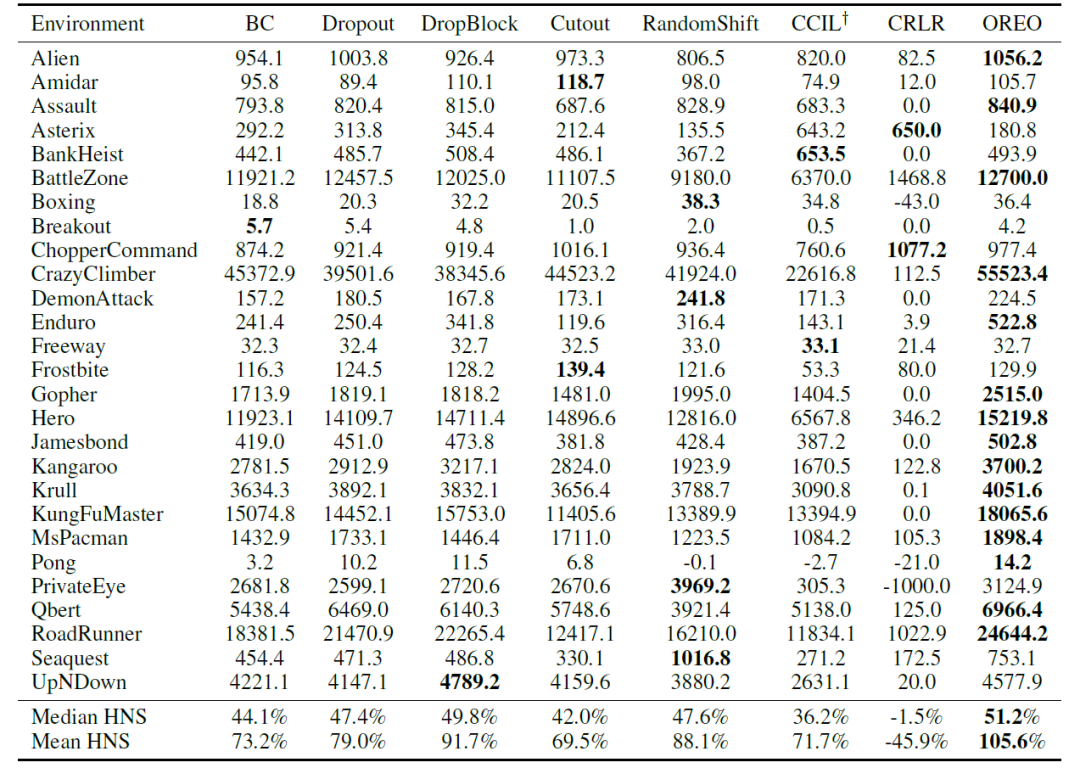
表3:混淆雅达利游戏环境中各模仿学习算法的表现比较

图10:使用行为克隆(第一行)及 OREO 方法(第二行)在混淆雅达利环境(左列)及原本的雅达利环境(右列)下学到的策略模型的可视化结果

表4:CARLA 驾驶模拟环境中各任务下各模仿学习算法的成功率
参考文献
1. [Ribeiro’16] M. T. Ribeiro, S. Singh, and C. Guestrin. “Why should I trust you?": Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, pages 1135–1144, 2016.
2. [v.d. Oord’17] van den Oord, A., Vinyals, O., & Kavukcuoglu, K. Neural discrete representation learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems (pp. 6309-6318), 2017.
3. [de Haan’19] de Haan, Pim, Jayaraman, Dinesh, and Levine, Sergey. Causal confusion in imitation learning. In Advances in Neural Information Processing Systems, 2019.
4. [Khemakhem’20] I. Khemakhem, D. P. Kingma, R. P. Monti, and A. Hyvärinen. Variational autoencoders and nonlinear ICA: A unifying framework. In the 23rd International Conference on Artificial Intelligence and Statistics, 26-28 August 2020, Online [Palermo, Sicily, Italy], volume 108 of Proceedings of Machine Learning Research, pages 2207–2217, 2020.