备战世界杯!先用深度学习与强化学习踢场 FIFA 18

本文作者是切尔西足球俱乐部粉丝,他写了一篇英文博客介绍如何使智能体在 FIFA 18 游戏中更加完美地踢任意球。全文共分为两部分:用神经网络监督式地玩 FIFA 18;用强化学习 Q 学习玩 FIFA 18。
玩 FIFA 游戏的机制
构建能玩 FIFA 游戏的智能体与游戏内置的 Bot 是不一样的,它不能访问任何内部程序信息,只能与人一样获得屏幕的输出信息。游戏窗口截图就是所有需要馈送到智能体游戏引擎的数据,智能体会处理这些视觉信息并输出它希望采取的动作,最后这些动作通过按键模拟器传递到游戏中。
下面我们提供了一个基本的框架为智能体提供输入信息,并使其输出控制游戏。因此,我们要考虑的就是如何学习游戏智能体。本文主要介绍了两种方法,首先是以深度神经网络和有监督的方式构建智能体,包括使用卷积神经网络理解截图信息和长短期记忆网络预测动作序列。其次,我们将通过深度 Q 学习以强化学习的方式训练一个强大的智能体。这两种方式的实现方法都已经开源:
基于深度有监督的智能体:
https://github.com/ChintanTrivedi/DeepGamingAI_FIFA
基于强化学习的智能体:
https://github.com/ChintanTrivedi/DeepGamingAI_FIFARL
基于监督学习的智能体
步骤 1:训练卷积神经网络(CNN)
CNN 因其高度准确地对图像进行目标检测的能力而出名。再加上有快速计算的 GPU 和高效的网络架构,我们可以构建能实时运行的 CNN 模型。
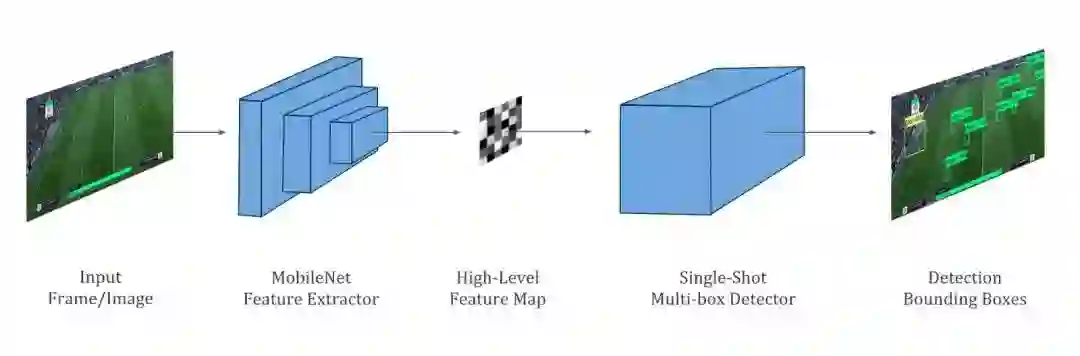
为了令智能体能理解输入图像,我们使用了一个非常紧凑的轻量级卷积网络,即 MobileNet。该网络抽取的特征图表征了智能体对图像的高级语义理解,例如理解球员和其它目标在图像中的位置。特征图随后会与单次多目标检测器一起检测球场上的球员、球与球门。
步骤 2:训练长短期记忆网络(LSTM)
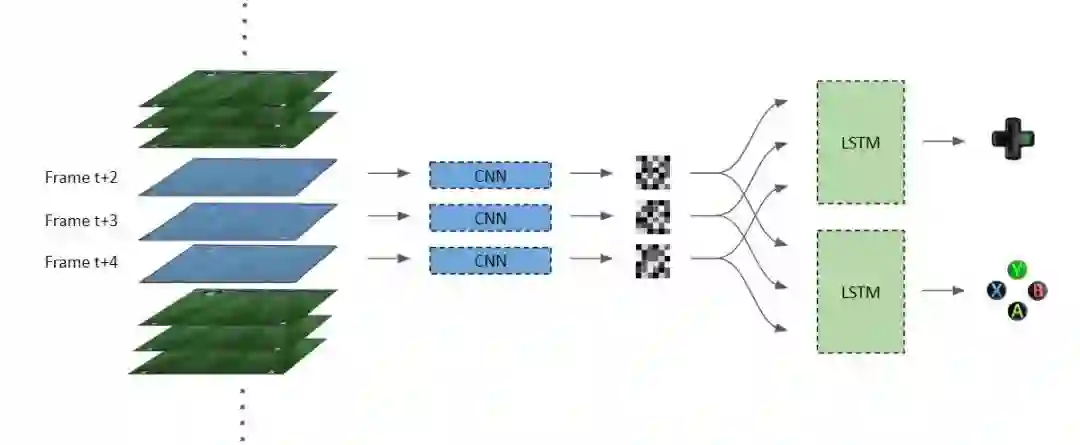
现在理解了图像之后,我们继续来决定下一步的行动。然而,我们并不想仅看完一个帧的图像就采取动作。我们首先需要观察这些图像的短序列。这正是 LSTM 发挥作用的地方,LSTM 就是因其对时序数据的优越建模能力而出名的。连续的图像帧在序列中作为时间步,每个帧使用 CNN 模型来提取特征图。然后这些特征图被同时馈送到两个 LSTM 网络。

第一个 LSTM 执行的是决定玩家移动方式的学习任务。因此,这是一个多类别分类模型。第二个 LSTM 得到相同的输入,并决定采取交叉、过人、传球还是射门的动作,是另一个多类别分类模型。然后这两个分类问题的输出被转换为按键动作,来控制游戏中的动作。
这些网络已经在手动玩游戏并记录输入图像和目标按键动作而收集的数据上训练过了。这是少数几个收集标记数据不会那么枯燥的任务类型之一。
基于强化学习的智能体
在前一部分中,我介绍了一个经过训练的人工智能机器人,它使用监督学习技术来玩 FIFA 游戏。通过这种方式,机器人很快就学会了传球和射门等基本动作。然而,收集进一步改进所需的训练数据变得很麻烦,改进之路举步维艰,费时费力。出于这个原因,我决定改用强化学习。
这部分我将简要介绍什么是强化学习,以及如何将它应用到这个游戏中。实现这一点的一大挑战是,我们无法访问游戏的代码,所以只能利用我们在游戏屏幕上所看到的内容。因此,我无法在整个游戏中对智能体进行训练,但可以在练习模式下找到一种应对方案来让智能体玩转技能游戏。在本教程中,我将尝试教机器人在 30 码处踢任意球,你也可以通过修改让它玩其他的技能游戏。让我们先了解强化学习技术,以及如何制定适合这项技术的任意球问题解决方案。
强化学习(以及深度 Q 学习)是什么?
与监督学习相反,强化学习不需要手动标注训练数据。而是与环境互动,观察互动的结果。多次重复这个过程,获得积极和消极经验作为训练数据。因此,我们通过实验而不是模仿来学习。
假设我们的环境处于一个特定的状态 s,当采取动作 a 时,它会变为状态 s’。对于这个特定的动作,你在环境中观察到的即时奖励是 r。这个动作之后的任何一组动作都有自己的即时奖励,直到你因为积极或消极经验而停止互动。这些叫做未来奖励。因此,对于当前状态 s,我们将尝试从所有可能的动作中估计哪一个动作将带来最大的即时 + 未来奖励,表示为 Q(s,a),即 Q 函数。由此得到 Q(s,a) = r + γ * Q(s’, a’),表示在 s 状态下采取动作 a 的预期最终奖励。由于预测未来具有不确定性,因此此处引入折扣因子 γ,我们更倾向于相信现在而不是未来。
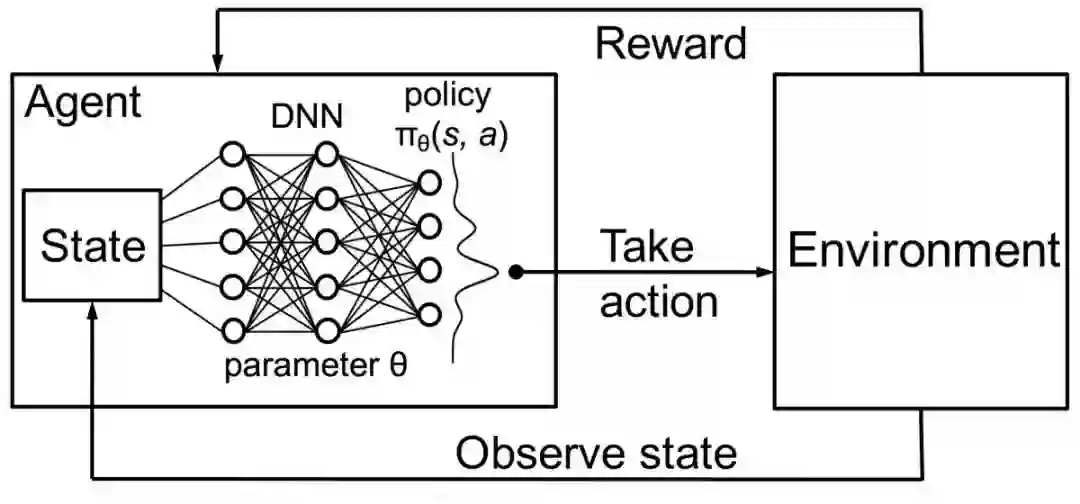
图源:
http://people.csail.mit.edu/hongzi/content/publications/DeepRM-HotNets16.pdf深度 Q 学习是一种特殊的强化学习技术,Q 函数是通过深度神经网络学习的。给定环境的状态作为这个网络的图像输入,它试图预测所有可能动作的预期最终奖励,像回归问题一样。选择具有最大预测 Q 值的动作作为我们在环境中要采取的动作。该技术因此得名「深度 Q 学习」。
将 FIFA 任意球定位为 Q 学习问题
状态:通过 MobileNet CNN 处理的游戏截图,给出了 128 维的扁平特征图。
动作:四种可能的动作,分别是 shoot_low、shoot_high、move_left、move_right.
奖励:如果按下射门,比赛成绩增加 200 分以上,我们就进了一个球,r=+1。如果球没进,比分保持不变,r=-1。最后,对于与向左或向右移动相关的动作,r=0。
策略:两层密集网络,以特征图为输入,预测所有 4 个动作的最终奖励。
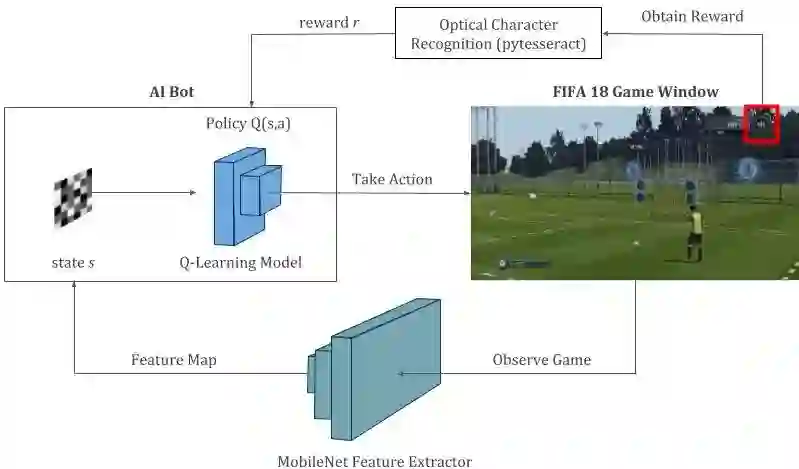
智能体与游戏环境交互的强化学习过程。Q 学习模型是这一过程的核心,负责预测智能体可能采取的所有动作的未来奖励。该模型在整个过程中不断得到训练和更新。注意:如果我们在 FIFA 的开球模式中有一个和练习模式中一样的性能表(performance meter),那么我们可能就可以将整个游戏作为 Q 学习问题,而不仅仅局限于任意球。或者我们需要访问我们没有的游戏内部代码。不管怎样,我们应该充分利用现有的资源。
代码实现
我们将使用 Tensorflow (Keras) 等深度学习工具在 Python 中完成实现过程。
GitHub 地址:
https://github.com/ChintanTrivedi/DeepGamingAI_FIFARL
下面我将介绍代码的四个要点,以帮助大家理解教程,此处一些代码行出于简洁目的被删除了。不过运行代码时需要使用完整代码。
1. 与游戏环境交互
我们没有现成的 API 来访问代码。所以,我们自己制作 API!我们将使用游戏的截图来观察状态,利用模拟按键在游戏环境中采取动作,利用光学字符识别(OCR)来读取游戏中的奖励。我们的 FIFA 类别中有三种主要的方法:observe(), act(), _get_reward();另外还有一种方法是 _over(),检查任意球是否发出。

2. 收集训练数据
在整个训练过程中,我们要储存所有的经验和观察到的奖励,并以此作为 Q 学习模型的训练数据。所以,对于我们采取的每一个动作,我们都要将经验 <s,>与 game_over 标志一起存储。我们的模型将尝试学习的目标标签是每个动作的最终奖励,这是该回归问题的实数。

3. 训练过程
现在我们可以与游戏互动,并将互动储存在记忆中。我们开始训练 Q 学习模型。为此,我们将在「探索」(exploration,在游戏中随机采取动作)和「利用」(exploitation,采取模型预测的动作)之间取得平衡。这样我们就可以通过试错来获得不同的游戏体验。参数 epsilon 正是用于此目的,它是平衡 exploration 和 exploitation 的指数递减因子。开始的时候,我们什么都不知道,想进行更多探索,但是随着 epoch 的增加,我们学到的越来越多,于是我们想多利用,少探索。因此参数epsilon 的值衰减。
在本教程中,由于时间和性能的限制,模型训练只进行了 1000 个 epoch,但以后我想至少训练 5000 个 epoch。

4. 模型定义和训练过程的启动
Q 学习过程的核心是具有 ReLU 激活函数的两层密集 / 全连接网络。它将 128 维的特征图作为输入状态,为每个可能的动作输出 4 个 Q 值。具有最大预测 Q 值的动作是根据给定状态的网络策略所要采取的期望动作。

这是执行此代码的起点,但你必须确保 FIFA 18 游戏在第二个显示器上以窗口模式运行,并在技能游戏下加载任意球练习模式:射击菜单。确保游戏控件与你在 FIFA.py 脚本中硬编码的键同步。
结果
尽管该智能体并未掌握所有种类的任意球,但它在某些场景中学习效果很好。它几乎总能在没有筑人墙的时候成功射门,但是在人墙出现时射门会有些困难。此外,由于它在训练过程中并未频繁遇到「不直面球门」等情况,因此在这些情况下它的行为比较愚蠢。但是,随着训练 epoch 的增加,研究者注意到该行为呈下降趋势。
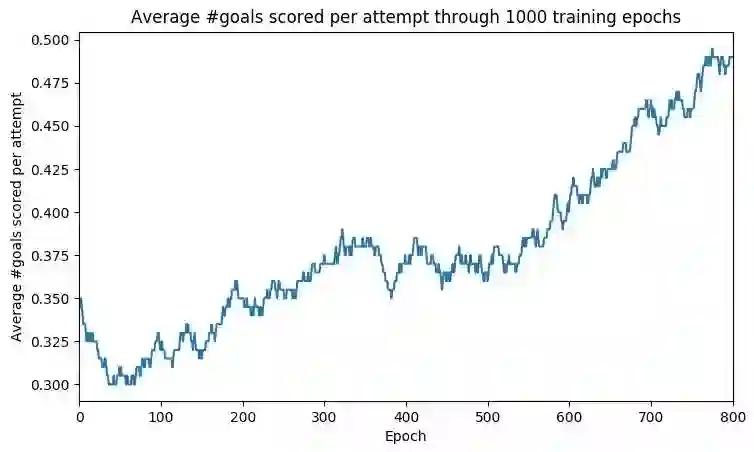
上图显示在 1000 个 epoch 中每次尝试的任意球平均数。因此,例如 epoch 700 的值为 0.45 意味着(平均)45% 的尝试需要罚球。如上图所示,在训练 1000 个 epoch 后,平均射门得分率从 30% 上升到 50%。这意味着当前机器人在一半数量的任意球尝试中成功得分(而人类的平均得分率是 75-80%)。不过 FIFA 的比赛并不具备那么强的确定性,使得学习过程变得困难。
更多结果查看:
https://www.youtube.com/c/DeepGamingAI
结论
总体而言,我认为虽然该智能体未能达到人类水平,但结果也是相当令人满意的。从监督式学习转向强化学习有助于减少收集训练数据的麻烦。如果有足够的时间去探索,它在学习如何玩简单游戏等问题上会表现得非常好。然而,强化学习的设定在遇到陌生情况时似乎会失败,这使我认为将它表述为不能推断信息的回归问题和监督学习中的分类问题是一样的。也许二者结合可以解决两种方法的弱点。到时候我们或许就会看到为游戏构建人工智能的最佳结果。
原文链接:
https://towardsdatascience.com/building-a-deep-neural-network-to-play-fifa-18-dce54d45e675
https://towardsdatascience.com/using-deep-q-learning-in-fifa-18-to-perfect-the-art-of-free-kicks-f2e4e979ee66

媒体合作请联系:
邮箱:xiangxiaoqing@stormorai.com




