加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:机器之心@微信公众号
拿起以往的老照片,无一不是灰蒙蒙的。那么有没有一种方法将这些老照片重焕生机呢?近日,弗吉尼亚理工等机构开发出了一种语境感知分层深度修复技术,它利用基于学习的修复模型来迭代地合成新的颜色和深度信息,并借助标准图形引擎将这些老照片渲染成3D照片。
如何让一张老照片看起来有 3D 效果?
来自弗吉尼亚理工大学、台湾清华大学和 Facebook 的研究者提出了一种
将单个 RGB-D 输入图像转换为 3D 照片的方法
,利用多层表示合成新视图,且新视图包含原始视图中遮挡区域的 hallucinated 颜色和深度结构。
具体而言,研究人员使用具有显式像素连通性的分层深度图像(Layered Depth Image,LDI)作为基础表示,并提出了一种基于学习(learning-based)的修复模型,该模型以空间语境感知的方式,为遮挡区域迭代地合成局部新的颜色和深度信息。在使用标准图形引擎的情况下,该方法可以高效地渲染生成 3D 照片。
研究者
在多种具有挑战性的日常场景中验证了此方法的有效性,与当前 SOTA 方法相比,该方法生成结果的伪影更少。
除了论文以外,该研究还提供了大量示例、代码,还有可以试用的 Colab 环境,感兴趣的读者可以试试效果。
论文地址:https://arxiv.org/pdf/2004.04727.pdf
项目地址:https://github.com/vt-vl-lab/3d-photo-inpainting
网站地址:https://shihmengli.github.io/3D-Photo-Inpainting/
Colab 地址:https://colab.research.google.com/drive/1706ToQrkIZshRSJSHvZ1RuCiM__YX3Bz
这么优秀的 3D 效果是怎么实现的?
该研究提出的方法以 RGB-D 图像作为输入,并生成分层深度图像(LDI),并修复输入图像中被遮挡区域的颜色和深度。
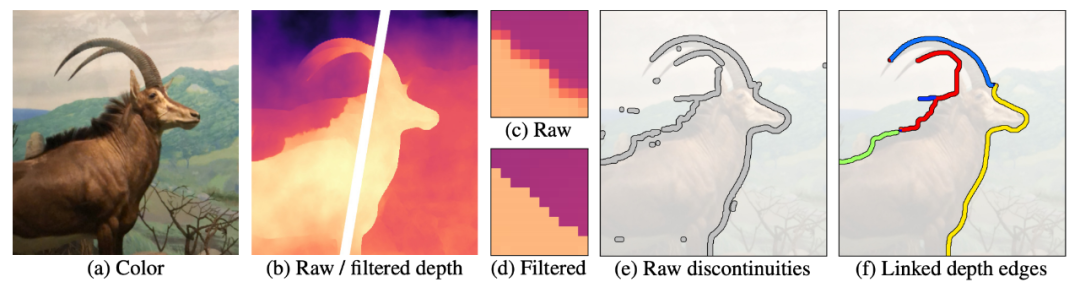
图像预处理:首先初始化 LDI,LDI 使用单个层,且完全 4-connected。在预处理过程中,检测主要的深度不连续区域,并将它们分为简单的连接深度边缘(connected depth edge)。这构成了主算法的基础,该算法的核心部分式迭代地选择深度边缘进行修复;
语境和合成区域:断开边缘上的 LDI 像素,只修复边缘的背景像素。具体做法是从边缘的「已知」侧提取局部语境区域,在「未知」侧生成合成区域;
语境感知的颜色和深度修复:合成区域是新像素的连续 2D 区域,研究者使用基于学习的方法从给定语境中为其生成颜色和深度值;
形成 3D 纹理网格:修复完成后,将合成像素合并到 LDI 像素。
该方法按照以上流程迭代进行,直到所有深度边缘都得到处理。
下图 2 展示了图像预处理的过程。首先对颜色和深度输入进行预处理 (a-b),然后使用双边中值滤波器锐化输入深度图 (c-d),接下来使用视差阈值检测不连续区域 (e),清除错误的阈值响应并将不连续区域组合成为连接深度图 (f)。这些连接深度图正是修复过程的基础。
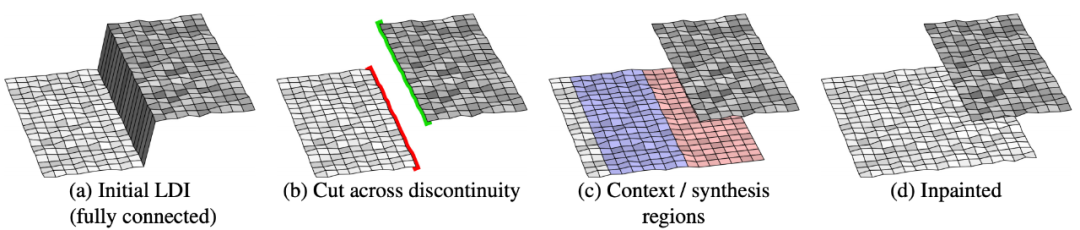
该研究提出的修复算法每次都在之前计算好的一个深度边缘上执行。给定一个深度边缘(下图 3a),修复算法的目的是在相邻的遮挡区域中合成新的颜色和深度信息。
首先将不连续区域中的 LDI 像素断开(图 3b)。断开的像素(即失去邻居的像素)被称为轮廓像素(silhouette pixel)。图 3b 中显示了前景轮廓(绿色)和背景轮廓(红色),我们只需要修复背景轮廓。
接下来生成合成区域(即新像素的连续区域,图 3c 中的红色像素),提取语境区域(图 3c 中的蓝色像素)。最后,将合成像素并入 LDI 像素中。
图 3:LDI 修复算法的概念图示。(a) 初始 LDI 是全连接的,图中灰色区域是深度边缘(不连续区域)。(b) 首先将深度边缘上的 LDI 像素连接断开,形成前景轮廓(绿色)和背景轮廓(红色)。(c) 对于背景轮廓,提取语境区域(蓝色),生成合成区域(红色)。(d) 将合成像素并入 LDI 中。
图 4:语境/合成区域。图 2(f) 中三个连接深度边缘示例(黑色)的语境区域(蓝色)和合成区域(红色)。
此外,由于检测到的深度边缘可能无法与遮挡区域的边界很好地对齐,因此研究者将合成区域扩大了 5 个像素,这有助于减少修补区域中的伪影。
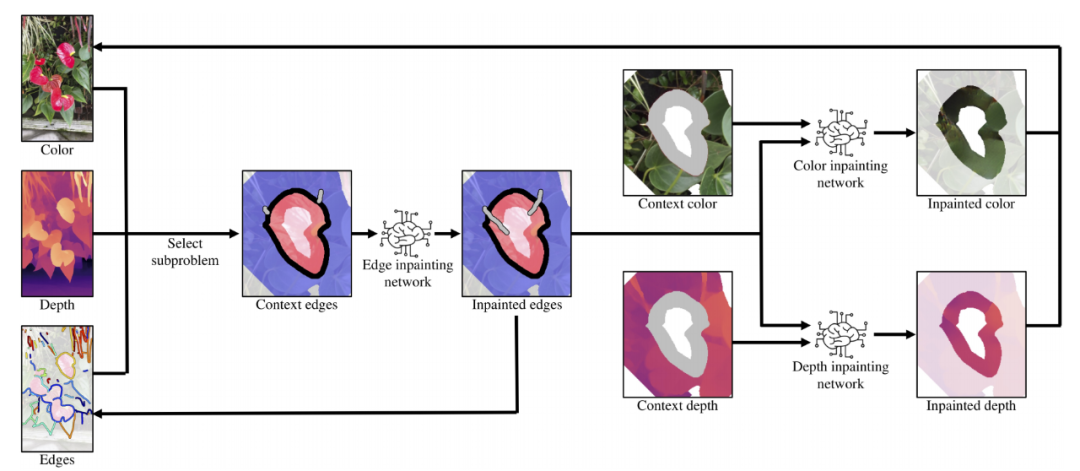
如何合成颜色和深度值?一种最直接的方法是分别修复彩色图像和深度图。但随之产生的问题是,已修复的深度图可能无法与已修复的颜色非常合适地匹配。为了解决此问题,研究者设计了类似于 [43, 67] 的颜色和深度修复网络,同时
将修复任务分解为三个子网络:边缘修复网络、颜色修复网络和深度修复网络
(下图 6)。
给定颜色、深度、提取以及连接的深度边缘作为输入,随机选择其中一个边作为子问题。首先使用边缘修复网络修复合成区域中(红色区域)的深度边缘,然后将修复后的深度边缘与语境颜色连接在一起,并应用颜色修复网络生成用以修复的颜色。类似地,将修复后的深度边缘与语境深度连接起来,并应用深度修复网络生成修复深度。
在深度复杂(deep-complex)的场景中,仅应用一次该研究提出的修复模型肯定不够,因为修复深度边缘所导致的不连续区域使得我们依然可以看见空白(hole)。所以研究者多次使用修复模型,直到不再生成修复深度边缘为止。
下图 8 展示了多次应用修复模型的效果。其中,应用一次修复模型填补了缺失的层。但是从图 8b 的观察视角中,我们依然可以看到一些空白区域。而应用两次修复模型可以彻底消除这些伪影。
研究者将所有的修复深度和颜色值集成返回原始 LDI 中,从而创建了 3D 纹理网格。在渲染过程中使用网格表示能够快速渲染新的视图,而且无需对每个视图执行推理步骤。因此,在边缘设备上使用标准图形引擎即可轻松地对该研究方法生成的 3D 表示进行渲染。
实验结果
该研究进行了大量实验,对新方法的效果做了
视觉对比、量化对比,同时还做了控制变量实验。
首先,我们来看新方法与当前最优的视角合成在视觉效果上的对比结果:
图 9:新方法与基于 MPI 的方法的视觉对比结果
从图中可以看到,该研究提出的新方法能够修复原始图像中被遮挡的区域,且结构和颜色都很合理。
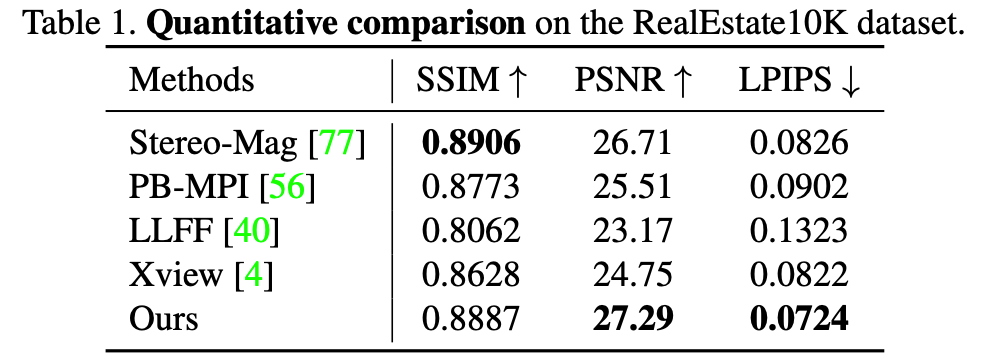
研究者对比了不同方法在 RealEstate10K 数据集上的量化对比结果,如下表 1 所示:
该研究提出的新方法在 SSIM 和 PSNR 两项指标上的性能均具备很强的竞争力。此外,新方法的合成视角表现出了更优秀的感知质量,这一点从 LPIPS 分数上可以看出。
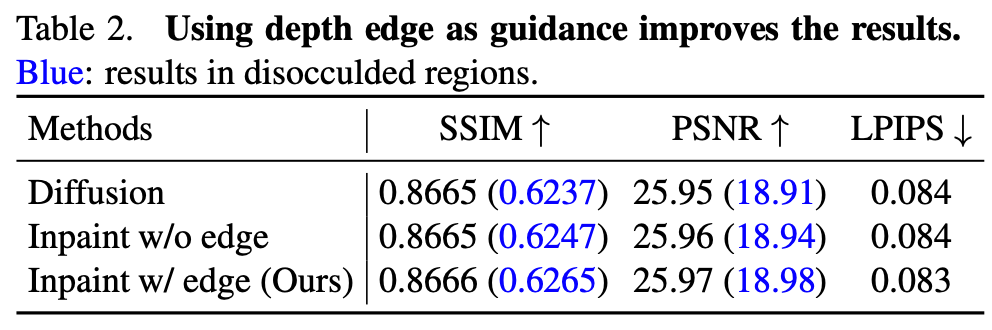
研究者从测试数据序列中采样了 130 个踪片,并在全图和未遮挡区域上评估修复颜色,测试结果见下表 2。可以看出,
该研究提出的边缘引导的修复技术给各项评估指标数值带来了微小的提升。
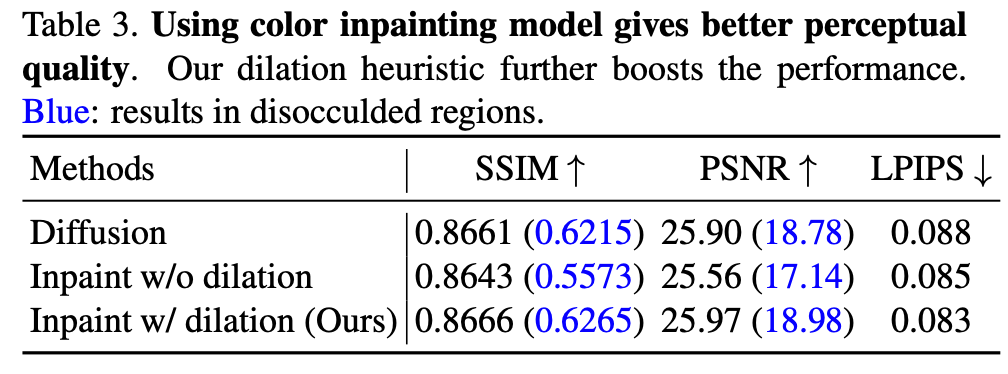
此外,为测试颜色修复模型的效果,研究者进行了类似的实验。下表 3 展示了不同方法在全图和遮挡区域上的性能结果:
从上表中可以看出新方法的感知质量更好,下图中的示例也说明了这一点。
研究者在不同方法生成的深度图上进行实验,结果表明新方法可以很好地处理不同来源的深度图。
图 12:该研究提出的方法可以处理不同来源的深度图。新视角图像左上角为深度估计。
Github 介绍
Linux (已在 Ubuntu 18.04.4 LTS 上测试)
Anaconda
Python 3.7 (已在 3.7.4 上测试)
PyTorch 1.4.0 (已在 1.4.0 测试执行)
运行以下命令
conda create -n 3DP python=3.7 anaconda
conda activate 3DP
pip install -r requirements.txt
conda install pytorch==1.4.0 torchvision==0.5.0 cudatoolkit==10.1.243 -c pytorch
chmod +x download.sh
./download.sh
python main.py --config argument.yml
将结果存储再以下目录中:
MiDas 估算的对应深度 tu
3D 网格
具有放大效果的渲染视频
具有摆动效果的渲染 shi'p
渲染视频并进行 circle motion
如果你对此项目感兴趣,可浏览项目地址便于参考更多详细信息。
40万奖金的AI移动应用大赛,参赛就有奖,入围还有额外奖励
![]()
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()