微软亚洲研究院提出OCRNet:化解语义分割上下文信息缺失难题 | ECCV 2020
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:微软研究院AI头条
编者按:图像语义分割一直都是场景理解的一个核心问题。针对语义分割中如何构建上下文信息,微软亚洲研究院和中科院计算所的研究员们提出了一种新的物体上下文信息——在构建上下文信息时显式地增强了来自于同一类物体的像素的贡献,这种新的上下文信息从语义分割的定义出发,符合第一性原理思维,在2019年7月和2020年1月的 Cityscapes leaderboard 提交结果中都取得了语义分割任务第一名的成绩。相关工作“Object-Contextual Representations for Semantic Segmentation”已经被 ECCV 2020 收录。
图像分类、物体检测和语义分割可以并列为传统计算机视觉感知领域的3大基础问题,它们也是各种复杂视觉任务的基础。这些问题在日常生活中随处可见,例如,短视频软件内提供的一键特效功能可以让普通用户也能轻松制作出大片效果,这背后的底层算法就可能涉及到了对人体的语义分割。此外,无人驾驶技术里的底层视觉算法则通常会涉及到对街景的语义分割。
语义分割任务,即输入一张图像,输出图像中每个像素的语义类别。图1展示了选自 Cityscapes[1]、LIP[2]、ADE20K[3] 和 COCO-Stuff[4] 数据集的例子,第一行是原始的输入图像,第二行是对应于这些图像的 Ground-Truth 的语义分割结果,其中不同的颜色表示了不同的语义类别。

图1:语义分割任务示例

现在主流的基于深度学习的图像分割方法都是基于 CVPR 2015 的一项工作 Fully Convolutional Network for Semantic Segmentation (FCN) [5]。FCN 的 pixel-to-pixel(逐像素对应的输入输出)思想非常经典,而且易于理解,它被用来解决各种像素级理解的视觉任务,比如深度估计,光流估计,图像生成。图2为 FCN 的基本框架,整个网络去除了全连接层,最后通过上采样得到的特征表示可以与输入图像的每一个像素保持逐像素一一对应的关系。另外,FCN 的论文中也提出了 Encoder-Decoder 的结构来增强最后输出的特征表示。后续很多的经典工作比如 UNet[6] 等也是基于 FCN 设计的。
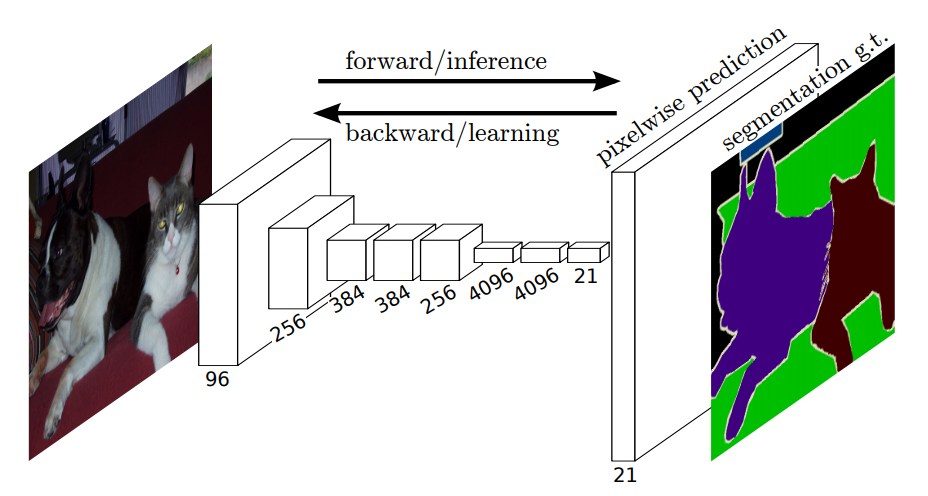
图2:FCN 框架
目前基于 FCN 的语义分割方法通常面临3个挑战:
(1)分辨率低: 通常随网络深度加深,逐渐降低的分辨率会导致空间信息损失;
(2)上下文信息缺失:像素级的特征的感受野不够,并且物体具有多尺度问题 (不同类别物体的绝对大小具有多尺度,同一类物体由于距离镜头的远近不同也具有多尺度);
(3)边界错误:由于边界区域像素的特征表示通常具有较弱的判别性,所以很多语义分割的错误是分布在边界区域上的。
对此,微软亚洲研究院在今年分别发表了3篇相关的工作来解决这些挑战,PAMI 2020 上发表的 HRNet[7] 可以解决分辨率低的问题,ECCV 2020 上的 OCR[8] 可以解决上下文信息缺失问题,而 ECCV 2020 上的 SegFix[9] 则可以用来解决边界错误的问题。
本文将主要介绍如何解决“上下文信息缺失问题”相关工作的技术细节,包括 ParseNet[10]、PSPNet[11]、DeepLab 系列[12,13]以及微软亚洲研究院的 OCR 方法。(本文中,我们用OCR 表示 Object Contextual Representation,用OCRNet表示基于 OCR 的网络框架。)
ParseNet
原始的 FCN 并没有去显式地利用全局上下文信息,因此每个像素特征的感受野(Receptive Field)会有所受限,从而导致了性能的瓶颈。为了解决这个问题,ICLR 2016 的 ParseNet[10] 提出了采用 Global Pooling 操作计算一个全局特征作为上下文信息去增强每个像素的特征表达(具体框架如图3)。ParseNet 旨在提高每个像素的特征感受野, 以获取更丰富的上下文信息。
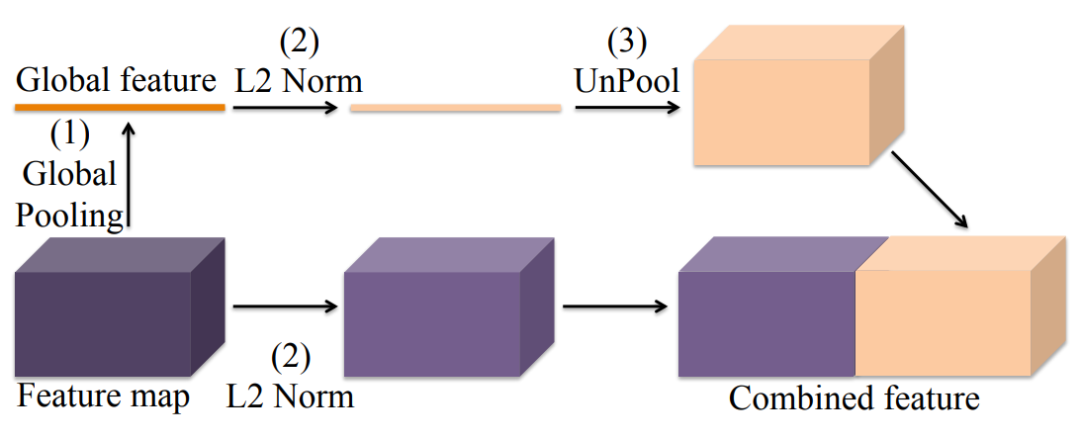
图3:ParseNet 框架
PSPNet
CVPR 2017 的 PSPNet [11] 提出了用 Pyramid Pooling 模块来抽取多尺度的上下文信息,以解决物体多尺度的问题。受益于这种更丰富的上下文信息,PSPNet 取得了 ImageNet Scene Parsing Challenge 2016 第一名的成绩。具体来说,PSPNet 采用了4路并行的不同尺度的图像划分,分别将图像均匀的划分成6ⅹ6/3ⅹ3/2ⅹ2个子区域,然后在每个子区域上应用 Average Pooling 计算得到一个向量作为这个区域内所有像素的 (不同尺度划分下) 局部上下文信息。另外,PSPNet 也会采用 Global Pooling 计算得到的一个向量作为所有像素的全局上下文信息,PSPNet 的整体计算框架见图4。
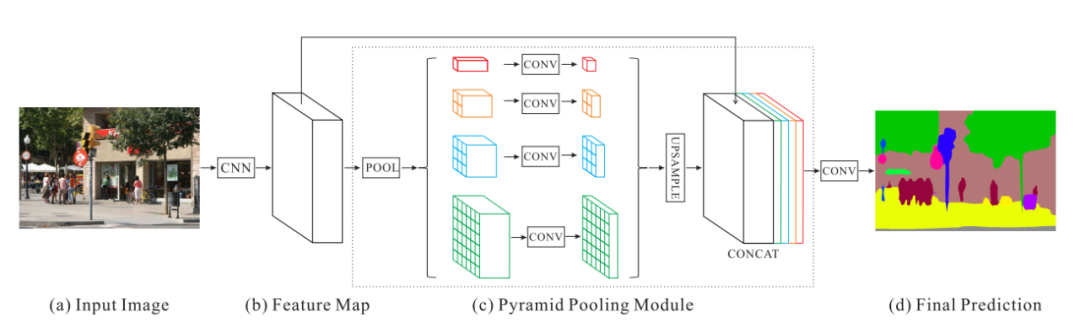
图4:PSPNet 框架
DeepLabv2/v3
发表于 PAMI 2017 的 DeepLabv2[12] 提出了一种新的 Atrous Convolution (带孔卷积) 来抽取多尺度上下文信息。具体而言,DeepLabv2 采用了并行的3组具有不同膨胀率(dilation rate)的带孔卷积操作来计算每一个位置的上下文信息,后续的 DeepLabv3[13] 又额外引入了 Global Average Pooling 操作来增强每一个位置的上下文信息。其中最核心的Atrous算法思想最早是在 ICLR 2015 的工作“Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs”中被引入到 FCN 的方法。图5展示了 DeepLabv3 是如何抽取丰富的多尺度上下文信息。
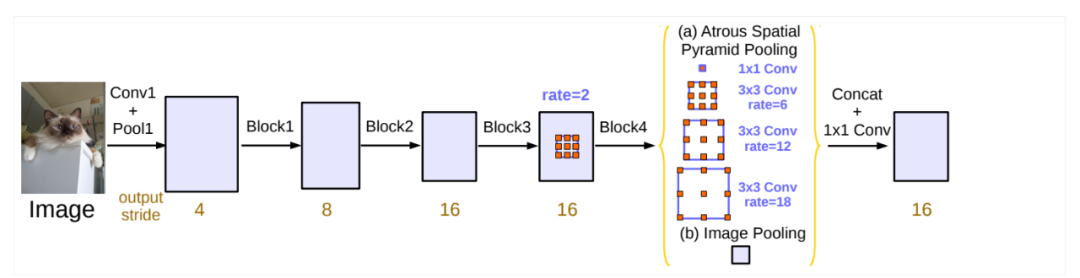
图5:DeepLabv3 框架
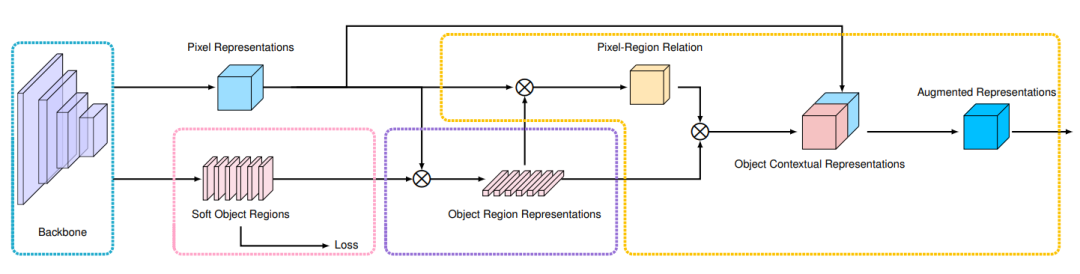
图6:OCRNet 框架
图7中对比了基于 ASPP 的多尺度上下文信息与基于 OCR 的物体上下文信息的区别。对选定的红色标记的像素,我们用蓝色来标记其对应的上下文信息。可以看到基于 ASPP 的多尺度上下文信息通常会包含不属于红色像素所属类别的像素,左图中采样到的蓝色标记的像素有一部分落在了人的身体上,还有一部分像素落在了后面的展板上。因此,这样的多尺度信息同时包含了物体信息与背景信息。而基于 OCR 的物体上下文信息的目标是只利用物体信息,即显式地增强物体信息。

图7:ASPP 与 OCR 方法的对比
OCR 方法在5个主流的语义分割数据库上都取得了不错的结果。值得注意的是,基于 HRNet + OCR 的一个单模型结果在 ECCV 2020 提交截稿前,在 Cityscapse leaderboard 的语义分割任务中取得了排名第一。
表1中对比了不同方法的参数量、GPU 内存、计算量(GFLOPs)以及运算时间。根据表格中的结果,可以看出 OCR 方法的各项复杂度指标都具有优势,尤其在运行速度方面,是 PSPNet 的 PPM 或者 DeepLabv3 的 ASPP 运行速度的近2倍。
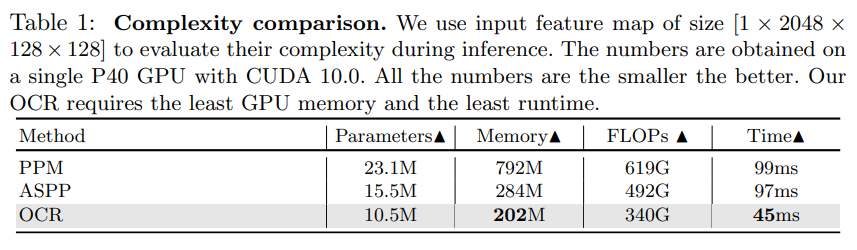
表1:PPM、ASPP、OCR 在参数量、GPU 内存、计算量 GFLOPs 和运算时间上的对比
表2则展示了 OCR 方法与目前已发表的前沿方法的对比,可以看出 OCR 在各个数据集上都取得了前三的结果。
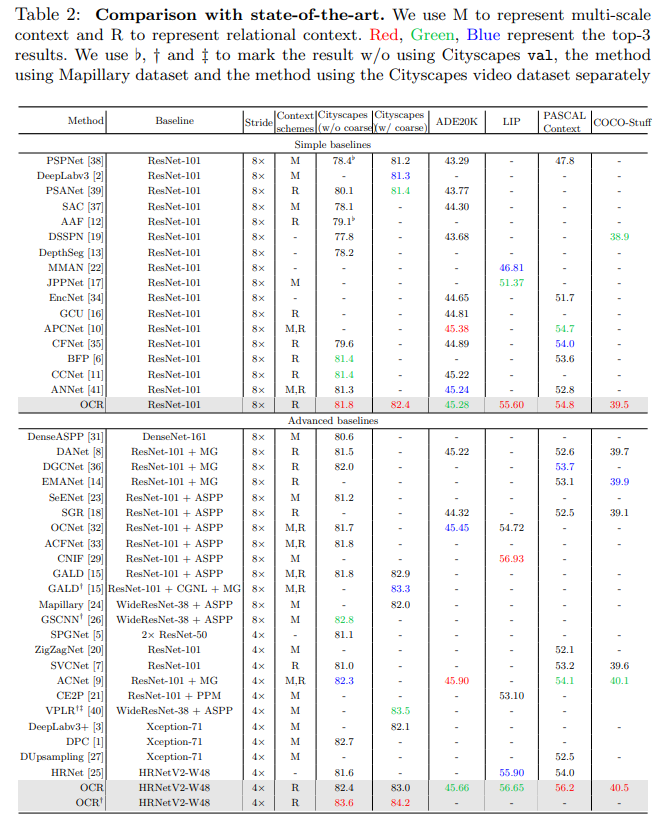
表2:OCR 与 State-of-the-art 方法对比
研究员们还基于 Panoptic-FPN[14] 在全景分割任务上验证了 OCR 方法的有效性,从表3中可以看出 OCR 稳定提升了最后的语义分割结果,而多尺度的上下文信息方法包括 PPM 与 ASPP 都没有显著提高结果。
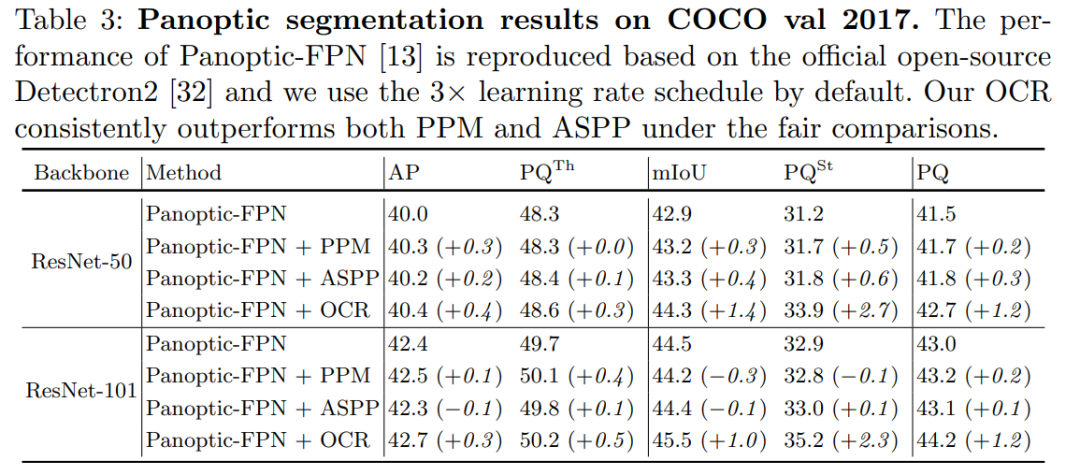
表3:基于 Panoptic-FPN 在全景分割任务上对比 OCR、PPM、ASPP
最近开源的 MMSegmentation[15] 代码库也验证了 OCR 方法的有效性。在都采用 ResNet-101 (os=8) 作为主干网络的时候,OCR 方法的 GPU 内存消耗与 FPS 都比 DeepLabv3 和 DeepLabv3+ 更具有优势,同时 OCR 在 Cityscapes validation set 上的 (不同训练设置下) 结果也都取得了比 DeepLabv3 更好的结果。HRNet 和 OCR 的结合则会在街景分割任务中有更加明显的优势,在表4中可以看到 HRNet+OCR 不仅速度是最快的,并且在 Cityscapes validation set 上的单尺度分割性能最高可以达到81.59%, 显著优于之前的 DeepLabv3 与 DeepLabv3+。
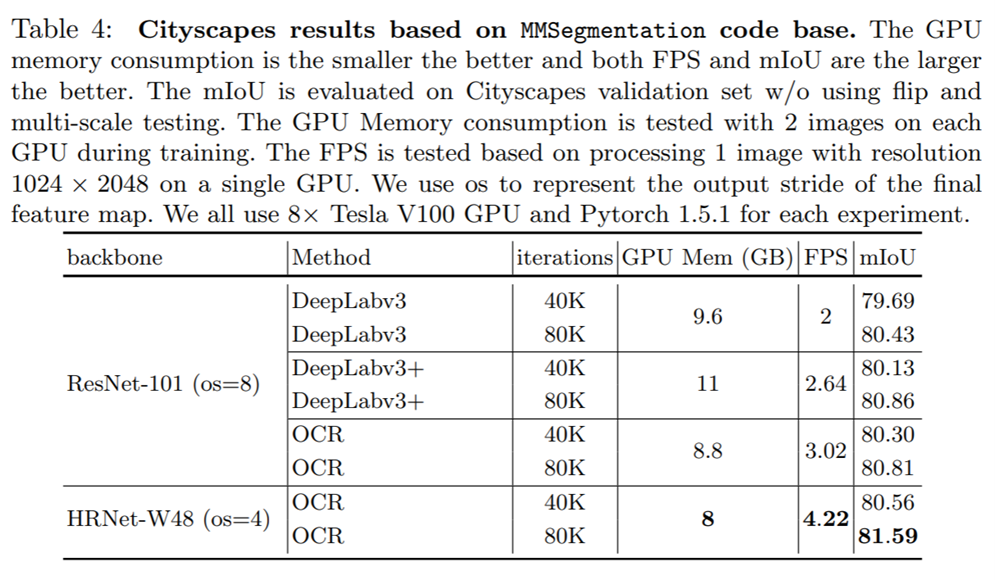
表4:基于 MMSegmentation 代码库的 OCR 实验结果
综上,OCR 方法提出的物体上下文信息的目的在于显式地增强物体信息,通过计算一组物体的区域特征表达,根据物体区域特征表示与像素特征表示之间的相似度将这些物体区域特征表示传播给每一个像素。在街景分割任务中,OCR 方法也比 PSPNet 的 PPM 和DeepLabv3 的 ASPP更加高效也更加准确。截止到2020年8月20日,根据最新 Cityscapes leaderboard 的结果,来自于 NVIDIA 的研究团队采用 HRNet + OCR 作为主干网络结构并且设计了一种更高效的多尺度融合方法[16],取得了目前排名第一的结果:85.4%。另外在最新的 ADE20K leaderboard 上,来自创新奇智(AInnovation)的研究团队[17]也基于 HRNet + OCR 取得了目前第一名的结果:59.48%。
更多技术细节可参考如下论文以及开源代码:

论文链接:https://arxiv.org/pdf/1909.11065.pdf
代码链接:https://github.com/openseg-group/openseg.pytorch
https://github.com/HRNet/HRNet-Semantic-Segmentation/tree/HRNet-OCR
引用:
[2] Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing, CVPR2017
[3] Scene parsing through ade20k dataset, CVPR207
[4] Coco-stuff: Thing and stuff classes in context, CVPR2018
[5] Fully convolutional networks for semantic segmentation, CVPR2015
[6] U-net: Convolutional networks for biomedical image segmentation, MICCAI2015
[7] Deep High-Resolution Representation Learning for Visual Recognition, PAMI2020
[8] Object-Contextual Representations for Semantic Segmentation, ECCV2020
[9] SegFix: Model-Agnostic Boundary Refinement for Segmentation, ECCV2020
[10] Parsenet: Looking wider to see better, ICLR2016
[11] Pyramid scene parsing network, CVPR2017
[12] Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs, PAMI2017
[13] Rethinking atrous convolution for semantic image segmentation, arXiv: 1706.05587
[14] Panoptic Feature Pyramid Networks, CVPR2019
[15] https://github.com/open-mmlab/mmsegmentation
[16] Hierarchical Multi-Scale Attention for Semantic Segmentation, arXiv:2005.10821
[17] AinnoSeg: Panoramic Segmentation with High Performance, arXiv:2007.10591
下载
论文PDF已打包好,在CVer公众号后台回复:OCRNet,即可下载访问
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已汇集1500人!涵盖语义分割、实例分割、全景分割、医学图像分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!


