基于背景知识的对话模型
本期论文
A Knowledge-Grounded Neural Conversation Model
本文研究的问题是用完全数据驱动的模型生成带有知识的对话内容,在原有 seq2seq 模型的基础上增加了一个 fact encoder 来生成对话。解决方案很实用,也很有启发性,建议研读。
本文工作来自 Information Sciences Institute 和微软研究院。
论文链接:
https://arxiv.org/pdf/1702.01932.pdf
阅读笔记精选
❶
LeoZhao
Motivation & Insight
目前的纯数据驱动的系统缺乏真实世界的知识,这些回复虽然流畅,很少包含实际的知识;而传统的对话则相反,可以很简单的使用slot filling插入这些事实,这样也使得系统很难拓展到新的领域和任务。
这篇文章提出了一种纯数据驱动的,基于知识的神经对话模型。本文提出的这个框架能够通过多任务学习来很自然的把对话和非对话数据联合起来。 这是第一个大规模、纯数据驱动的,并且能够访问外部知识库的对话模型,并且其生成的回答不是像传统的 slot filling 的形式,是使用 Seq2Seq 直接生成。
Architecture
这篇论文提出的框架如 Figure3 所示,其中的 World Facts 是一个集合,收集一些经过权威认证过的句子或者不准确的句子,作为知识库。当个定一个输入 S 和历史,需要在 Fact 集合里面检索相关的 facts,这里采用的 IR 引擎进行检索,然后经过 Fact Encoder 进行 fact injection。添加 World Facts 集合里面的元素是不需要重新训练整个系统的。训练采用多任务学习 Minh-Thang Luong, Quoc V Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. 2015. Multi-task sequence to sequence learning. arXiv preprint arXiv:1511.06114.
Encoder-Decoder 模型
本文采用的 Cell 是 GRU 而不是 LSTM,实际中采用的层数是 2 层-GRU 网络,并且 encoder 和 decoder 不共享参数,也不共享词向量。
Facts Encoder模型(Insight)
与 Memory Network 相似,具体可参考 Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al. 2015. End-to-end memory networks. In Advances in neural information processing systems. pages 2440–2448.
Memory Network 广泛应用在 QA 中,可参考 Tsung-Hsien Wen, Milica Gasic, Nikola Mrksˇic ́, Pei- Hao Su, David Vandyke, and Steve Young. 2015. Semantically conditioned LSTM-based natural lan- guage generation for spoken dialogue systems. In Proc. of EMNLP. Association for Computational Linguistics, Lisbon, Portugal, pages 1711–1721.
实际采用的过程中,把原始 memory network 的输入替换成 sequence 经过 encoder 的输出 u,把原始 memory network 的输出再作为 decoder 的输入进行句子生成。整个过程 memory network 采用的是单层网络。
Conclusion
从 Human-Evaluation 的结果来看,采用两个指标 appropriateness 和 informativeness,让该模型 Vs Baseline(Seq2Seq)进行比较,最后得到的结果是在第一个指标上差不多,但是在 informativeness 上明显比较好,能够提供更多有用的信息。
❷
wy19881022
论文提出了一种将 seq2seq 模型与事实相结合的方法,先使用 seq2seq 中的 encoder 计算出问句以及对话历史 S(没有使用 LSTM,而是使用了 GNU,好像业内都喜欢用 GNU),然后将事实通过关键词检索或者命令词提取技术,获取出相关的事实 f1,f2......最后通过计算 S 和 f1 的结合概率,输入 decoder 中,输出对应回答,理论上可以计算出跟概率最大事实相关的回应。 论文进行了两种模型的训练,一种不带事实的模型训练,一种带有事实模型的训练;奇妙的是,确定最终模型以后,可以通过修改事实库,以达到动态扩展模型的作用。想法比较新颖,但是回应的准确率相比于 seq2seq 并没有显著的提升,事实相关性有所提升。
❸
xwzhong
paper 提出使用 data-driven 和 knowledge-grounded 方式(23M general dialogue dataset+1M grounded dialogue dataset+1.1M tips),使 seq2seq 生成更加 contentful 的 response。
大致思路如下: 1. 对 post 信息进行 encode,得到 vector u;2. 使用 post 文本信息检索与之相关的 tips(根据 tf-idf 计算相似度得到),并用式 2 得到 vector c;3. 使用 u 计算各个 c 的权重,并进行加权求和(式 4),最终相加得到 seq2seq 中 decoder 部分的隐层输入(式 5)。 4. paper 提出了使用 post“相关的其它信息”使生成的回复更具实质内容,这个出发点不错,引入其它信息从某个角度讲是降低了 post 的“熵”; 5. 模型在 deploy 某个 post 的其它 information 时,用了类似 attention 的机制,每条 tip 信息输出权重由 post 得到的 vector u 衡量,这一 trick 在多篇 paper 都有体现,而且效果还不错。
❹
MH233
Contribution:使用 conversation dataset 去训练 Seq2Seq model or encoder-decoder model 并用于 chitchat 是很自然的想法(模型特质),但由于难以加入 external knowledge 无法产生与输入文本更贴近的 response。本文提出的将 facts 也 encode 到模型中去也是比较自然的。就 end-to-end model 加入 external knowledge 做 task-oriented、personality、diversity dialogue 的文章也挺多的,但应该还有些研究点没有覆盖到。
❺
mev
本文的 insight 比较独特,也比较自然,使用非结构化的 knowledge 来使得 conversation 更加 informative。 做法其实也比较简单,整个 MultiTask Model 主要分为两个任务,1)普通的 seq2seq,学习句子生成的语法知识;2)带外部信息的 seq2seq,其实就是个 Memory Network,首先根据 query 中的 entity 在非结构化的知识库中用 tf-idf 抽取相关的句子 F{f1,...,fn},然后用 RNN 给 query 编码得到 u,用 bag of words 编码 fi 得到 ri,用 attention 的方法得到 o,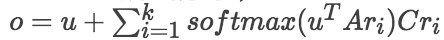
❻
YinongLong
看了前面同学的笔记,我有不同的想法。首先,我认为这篇文章不是为了解决对话生成模型生成的 response 太 general 的问题,从文章的第二部分开始看,作者强调的是数据集对 world's knowledge 的覆盖不全,所以生成回复的时候也不能期待 generator 可以生成相关的回复;其次,作者在自己的工作中也强调了自己的工作与传统的填槽式的生成回复的区别,也侧面反映了自己的工作类似于填槽,但是作者强调了自己是 data-driven。
然后,总览这个模型,可以分成两个部分,一是类似 Seq2Seq 的框架,用来学习 general conversational patterns;二是借用 End-to-End Memory Networks 来对 source embedding 和 relevant facts 进行操作,来生成 decoder 的 initial state。细节部分就是,开始的时候需要对 source sequence 进行 entity 识别(文中提到关键词匹配和实体识别两种类型的方法),根据识别的 entity,然后对 facts 进行检索(文中提到使用简单的关键字检索方法),然后使用 encoder 对 source sequence 进行 embedding,使用 embedding 的结果作为 End-to-End Memory Networks 的输入,而使用检索出来的 facts 的 BOW 表示作为 Memory 部分,最后生成输出 O,与前面的 source embedding 进行 summation 操作,作为 decoder 的 initial state 进行 response 的生成。
整个模型根据上面来看不是很复杂,最后采用 multi-task learning 的方式进行学习,作者认为这么做有几点好处,一是可以对 encoder 和 decoder 进行 pre-train,二是给了我们一定的灵活性来更好的处理两种类型的对话数据(我不是很确定)。最后,简单说,这篇文章使用 Seq2Seq 的框架学习 general conversational patterns(即可以用来填的槽),而是用 End-to-End Memory Networks 学习槽内容,最后结合生成回复。
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





