密歇根大学联合谷歌大脑提出,通过「推断语义布局」实现「文本到图像合成」
原文来源:arXiv
作者:Seunghoon Hong、Dingdong Yang、Jongwook Choi、Honglak Lee
「雷克世界」编译:嗯~阿童木呀
我们通过推断语义布局(semantic layout)提出了一种新的文本到图像合成(text-to-image synthesis)方法。我们的算法不是对从文本到图像的直接映射进行学习,而是将生成过程分解为多个步骤,首先,通过布局生成器从文本中构造出语义布局,然后由图像生成器将布局转换为图像。所提出的布局生成器通过生成目标边界框,并通过估算框内目标的形状以细化每个方框,从而逐级地以一种由粗到细(coarse-to-fine)的方式构造语义布局。图像生成器基于推断语义布局,进而合成图像,它提供了与文本描述相匹配图像的有用的语义结构。我们的模型不仅能够生成语义上更有意义的图像,而且使得我们能够通过修改生成的场景布局,实现生成图像的自动注释和用户控制生成过程。我们的研究结果证明了所提出模型在挑战MS-COCO数据集上的能力,并证明,相较于现有的方法,该模型能够显著地提高图像的质量,输出文本的解释性,以及输入文本的语义对齐。

可以这样说,从文本描述中生成图像一直都是计算机视觉领域一个非常活跃的研究课题。通过允许用户用自然语言描述视觉概念,它为调节图像生成提供了自然而灵活的界面。最近,基于条件生成式对抗网络(GAN)的方法已经在文本到图像合成任务上显示出了非常有前景的研究结果。在文本中对生成器和鉴别器进行调节,这些方法能够生成与输入文本不同且相关的非常逼真的图像。基于条件GAN框架,最近的方法通过生成高分辨率图像或扩充文本信息的方式,从而进一步提高了预测质量。
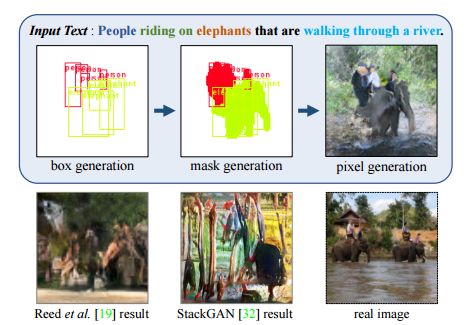
本文所提出算法的总体框架。给定一个文本描述,我们的算法序列性地构造一个场景的语义结构,并生成一个基于推断布局和文本的图像。可以根据标注的颜色进行查看。
然而,对于现有方法来说,它们的成功主要局限于诸如鸟类和花朵等这些简单的数据集,而像MS-COCO这样复杂的、真实图像的生成,对于它们来说仍然是一个很大的、公开性的挑战。如图1所示,从“人们骑在大象身上穿过一条河(people riding on elephants that are walking through a river)”这样的通用句子中生成图像,需要对各种视觉概念进行多种推理,诸如目标类别(人和大象)、目标的空间配置(骑着),场景环境(穿过一条河流)等等,这远比在较简单的数据集中生成单一的、大型的目标要复杂得多。现有的方法在为这种复杂的文本描述生成合理的图像方面还没有取得成功,因为从通用图像中学习一个文本到像素的直接映射是非常复杂的。
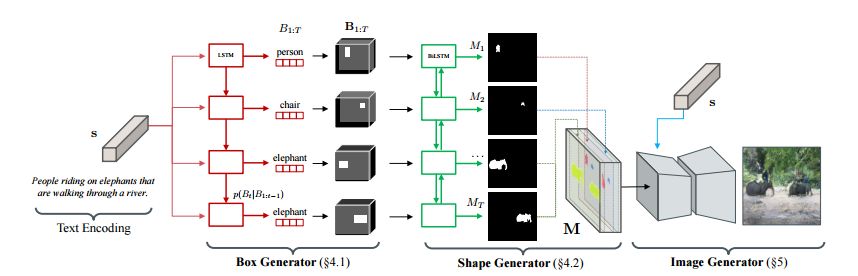
本文所提出算法的总体流水线。给定一个文本嵌入,我们的算法首先通过使用边框生成器放置一组目标边界框以生成一个粗略的布局,并使用形状生成器进一步细化每个边框内的目标形状。将边框生成器和形状生成器的输出结合起来,就形成了一个定义场景语义结构的语义标签映射。根据推断的语义布局和文本,图像生成器最终生成了一个像素级的图像。
我们并不是学习从文本到图像的直接映射,而是提出了一种替代方法,即将语义布局构造为文本与图像之间中间表示。语义布局定义了基于目标实例的场景结构,并提供场景的细粒度信息(fine-grained information),如目标的数量、目标的类别、位置、大小、形状等(图1)。通过引入能够明确地将图像的语义结构与文本对齐的机制,所提出的方法可以生成与复杂文本描述相匹配的复杂图像。另外,在语义结构上对图像生成进行调节,使得我们的模型能够生成语义上更有意义的图像,且这些图像更易于识别和具有可解释性。
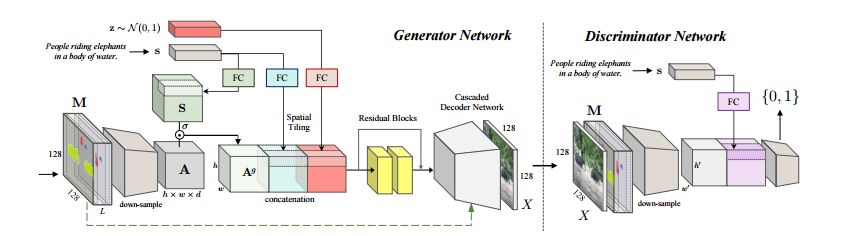
图像生成器的体系结构。根据文本描述和由布局生成器生成的语义布局,生成器生成与两个输入匹配的图像。
我们用于分层文本到图像合成的模型由两部分组成:一个是通过文本描述构造语义标签映射的布局生成器,另一个是将涵盖文本在内的估计布局转换为图像的图像生成器。由于学习一个从文本到细粒度语义布局的直接映射仍然具有挑战性,因此,我们将任务进一步分解为两个可管理的子任务:首先,我们使用边框生成器(box generator)估计图像的边界框布局,然后使用形状生成器优化边框内每个目标的形状。再然后,使用生成的布局指导图像生成器以进行像素级的合成。边框生成器、形状生成器和图像生成器都是由独立的神经网络实现的,并使用相应的监督进行并行训练。
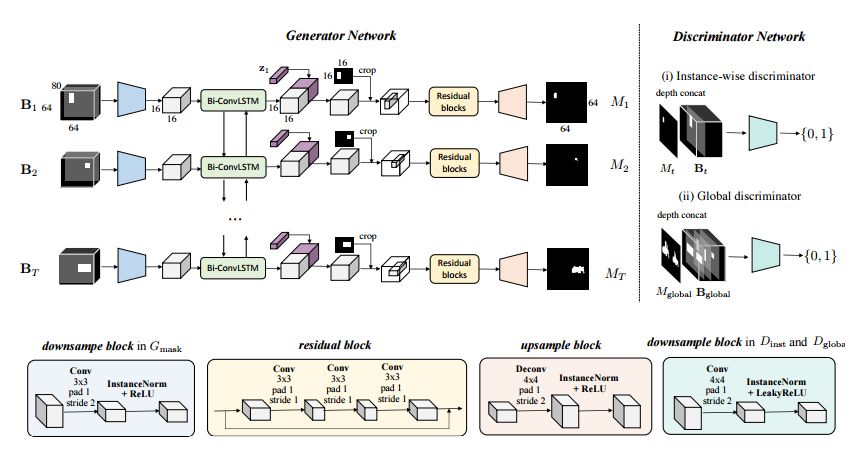
形状生成器的结构
生成语义布局不仅提高了文本到图像合成的质量,而且还带来了一些潜在的好处。首先,语义布局为生成图像提供了实例注释,这可以直接用于数据扩充和场景分析。其次,它提供了一个用于控制图像生成过程的交互界面,用户可以通过删除/添加目标、改变目标的大小和位置等来修改语义布局,从而生成期望中的图像。
本文所取得的成就及作出的贡献主要包括以下几点:
•我们提出了一种从复杂的文字描述中合成图像的全新方法。我们的模型从文本描述中明确地构造了语义布局,并且使用推断的语义布局指导图像的生成。
•通过在显式布局预测上对图像生成进行调节,我们的方法能够生成语义上更为有意义的图像,并且能够与输入描述保持良好的一致性。
•我们对具有挑战性的MS-COCO数据集进行了大量的定量和定性评估,并证明,相较于现有研究的成果来说,我们的方法在生成质量上有了实质性的改善和提升。

使用我们方法的图像生成结果。每列对应于根据(a)预测的边框和掩码布局,(b)对照标准边框和预测的掩码布局和(c)对照标准边框和掩码布局所生成的结果。处于说明的目的,类是颜色编码的。
我们提出了一种文本到图像合成的方法,它对语义布局进行明确的推断,并将其作为从文本到图像的中间表示。通过一系列生成器,我们的模型以一种由粗到精的方式,逐层地构造了语义布局。通过在显式布局预测上对图像生成进行调节,我们的方法能够生成复杂的图像,且能够保留语义细节,并与文本描述高度相关。我们的研究结果还表明,预测的布局可以用来控制生成过程。我们相信,在未来,布局和图像生成的端到端训练将是一个有趣的研究方向。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



