ACL2022 | 基于强化学习的实体对齐

论文题目:Deep Reinforcement Learning for Entity Alignment
本文作者:郭凌冰、韩玉强、张强、陈华钧(浙江大学)
发表会议:ACL 2022 Findings
论文链接:https://www.zhuanzhi.ai/paper/ea0d24acf0badd2ea11089cfdc1094eb
代码链接:https://github.com/guolingbing/RLEA
欢迎转载,转载请注明出处

一、引言
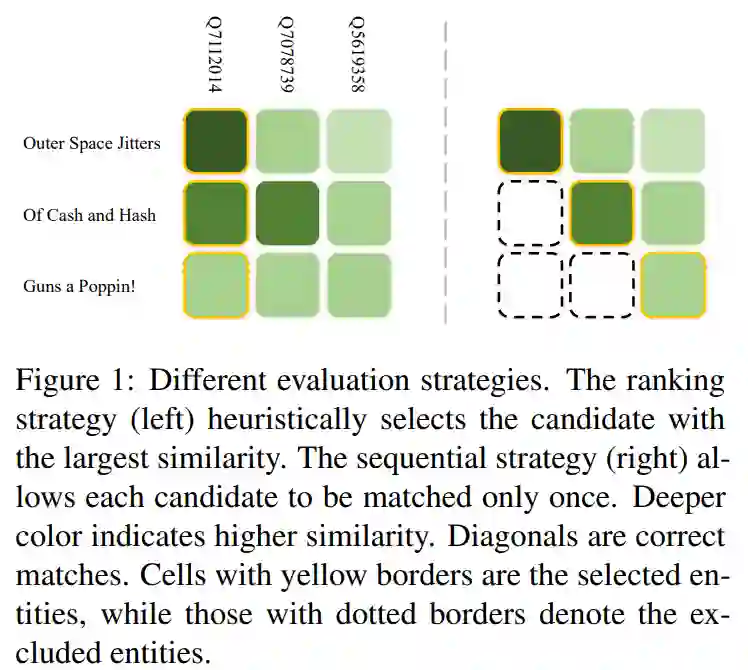
二、基于强化学习的知识图谱实体对齐
上述序列决策方式尽管能够正确地排除一些候选实体,但也存在着累积错误的风险。因此,本文提出了一种基于强化学习的方法来克服这一缺陷,其并不直接使用实体嵌入的相似度作为判断依据,而是直接把嵌入作为输入,训练一个策略网络(Policy Network)使其能够寻找到尽可能多的实体对,以实现最大回报(Reward)。同时,本文还采用了一种课程学习(Curriculum Learning)的策略,在训练过程中逐步增加难度,避免因任务复杂性而导致学习失败。
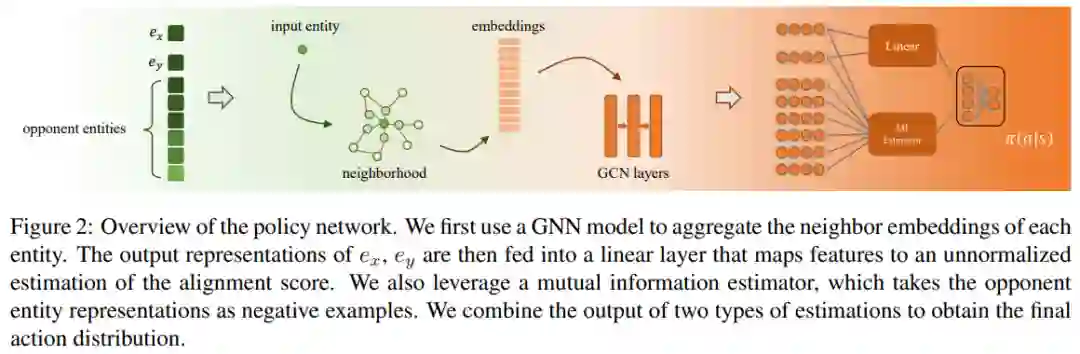
下图展示了策略网络的基本构成,对于输入实体和候选实体,我们选择了额外k个与输入实体接近的实体(即 opponent entities)作为context信息,可以用于拒绝当前匹配。对于每个实体,我们使用GNN模型同时编码其邻居向量以得到中间表示。除了线性层以外,最终的输出层还考虑了实体对间的互信息,综合两个评估器得到最终的输出标签,即匹配或不匹配。
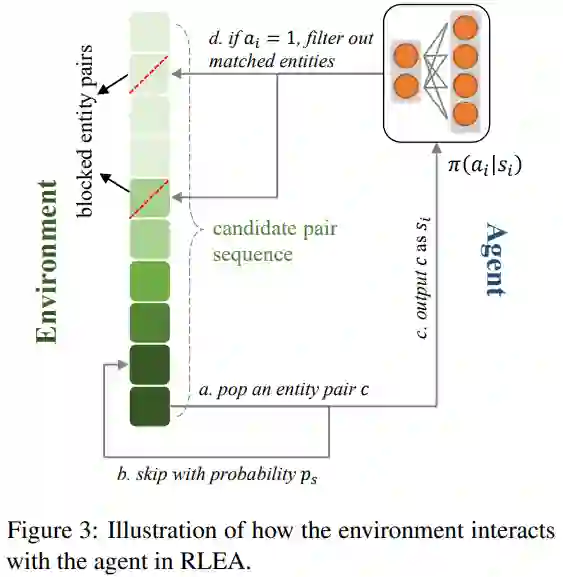
下图中展示了学习过程中,策略网络是如何与环境(Environment)互动的。在环境中维持了一个匹配对序列,其排序方法为实体对间的相似度,以保证在测试阶段该序列仍可用。如前文所述,相似度高的实体对未必真正匹配,因此在训练过程中本文通过对比实际标签与相似度信息来判断一个匹配对的难易程度,根据当前训练轮数,一些较高难度的匹配对将有更大的概率直接逃过训练。在一个情节(Episode)中,环境所给出的实体对将被策略网络一一判断,被认为匹配的实体对将会直接排除环境序列中的所有涉及这些实体的匹配对,这一过程一直持续到序列终止或所有实体均被匹配。
三、实验
本文选取了数个性能领先且具有不同特点的实体对齐模型作为对比,并在OpenEA数据集上进行了实验。结果如下表所示:本文所述方法RLEA在全部四种数据集上均相较原有方法有明显提升。Seq为仅仅采用序列决策而不涉及强化学习的对比方法,可以看出,其仍在绝大多数情况下也优于目前所采用的贪心策略。
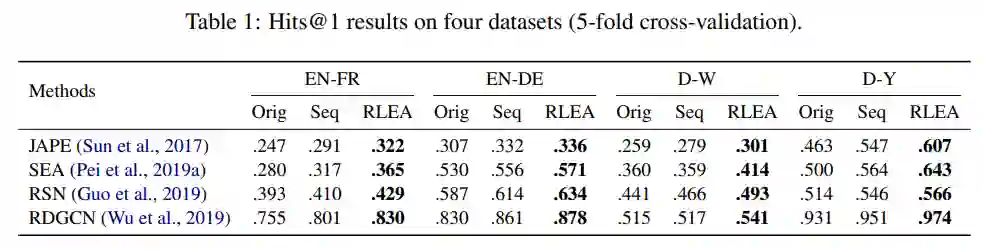
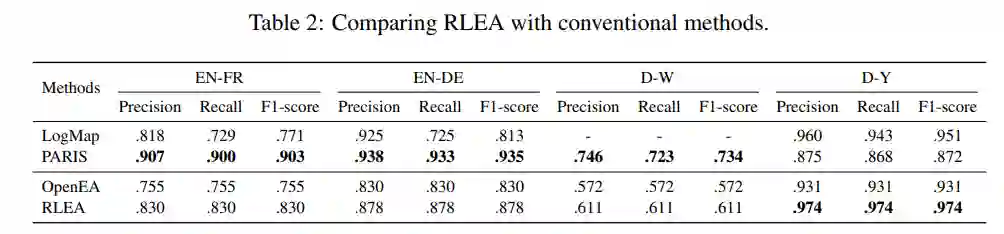
同时,本文还与传统实体对齐方法进行了对比。在此之前,尽管基于知识图谱嵌入的方法具有许多优点,但在绝对性能上与基于字符匹配等技术的传统方法有着较大差距。本文所提出的基于强化学习的方法不但缩小了这一差距,并且在一些数据集上(如D-Y)显著优于传统方法。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DREA” 就可以获取《ACL2022 | 基于强化学习的实体对齐》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~






