论文浅尝 | KGQR: 用于交互式推荐的知识图谱增强Q-learning框架

笔记整理:李爽,天津大学
链接:https://dl.acm.org/doi/pdf/10.1145/3397271.3401174
动机
交互式推荐系统(IRS)以其灵活的推荐策略和考虑最佳的长期用户体验而备受关注。为了处理动态用户偏好,研究人员将强化学习(reinforcement learning,RL)引入到IRS中。然而,RL方法有一个普遍的样本效率问题,即训练有效的推荐策略需要大量的交互数据,这是由于稀疏的用户响应和由大量候选项组成的大的行为空间造成的。此外,在网络环境中,通过探索性政策收集大量数据是不可行的,这可能会损害用户体验。在这项工作中,作者研究了利用知识图谱(KG)来处理IRS RL方法存在的这些问题,它为推荐决策提供了丰富的侧面信息。在两个真实世界的数据集上进行全面的实验,证明了作者提出的方法与先进技术相比有显著的改进。
亮点
KGQR的亮点主要包括:
1.通过利用KG中的先验知识进行候选项选择和从稀疏用户反馈中学习用户偏好,KGQR可以提高基于RL的IRS模型的样本效率;2.采用图神经网络的方法,考虑项目之间的语义相关性,能够更准确地表示用户的动态偏好。
概念及模型
模型的整体框架如下图所示。
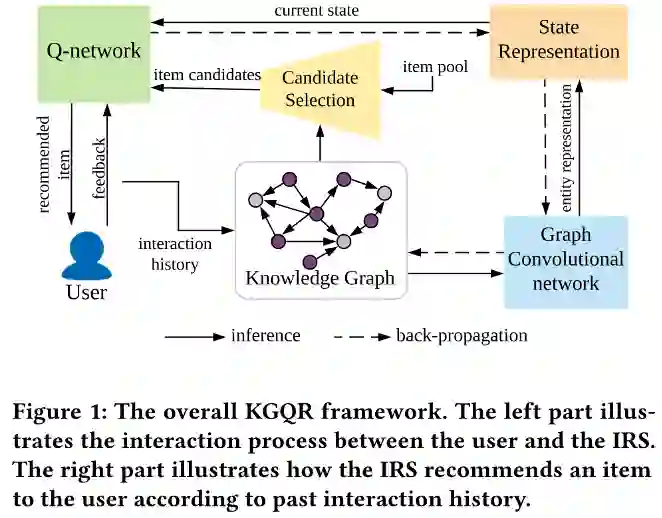
•KG增强的状态表示
在IRS场景中,不可能直接获得用户的状态,可以直接观察到的是记录的用户系统交互历史。
(1)图卷积嵌入层
为了将图中的结构和语义知识提取为低维稠密的节点表示,作者使用了图卷积网络(GCN)。在单个图卷积嵌入层中,节点表示的计算分为两步:聚合和集成。这两个过程可以扩展到多跳,使用符号k来标识第k跳。在每个层中,首先聚合给定节点h的相邻节点的表示:
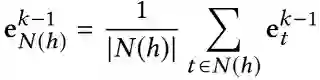
其中N(h)=N(head)={tail | (head,relation,tail)∈G} 是h的相邻节点集合。其次,将邻居的表示与h的表示集成为
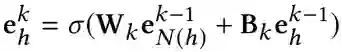
(2)行为聚合层
由于交互式推荐是一个连续的决策过程,因此在每一步中,模型都需要用户的当前观察作为输入,并提供推荐项作为输出。作者使用带有门控循环单元(GRU)的RNN作为网络单元,以聚合用户的历史行为并提取用户的状态s_t (G)。GRU单元的更新函数定义为
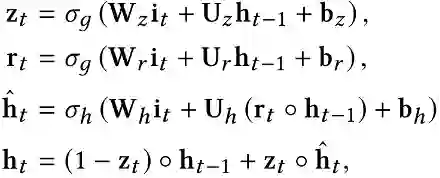
•基于邻居的候选项选择
作者基于KG中的k-hop邻居执行采样策略。在每个时间步中,用户的历史交互项充当种子集E_t^0={i_1,i_2,…,i_n}。从种子实体开始的k-hop邻居集表示为

然后,将当前用户状态的候选操作集定义为
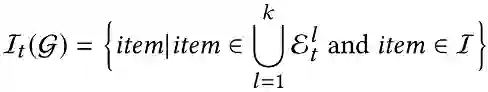
•学习深度Q-Network
在对用户状态s_t (G)进行建模并获得候选集I_t (G)后,需要设计Q-Network来结合这些信息,并改进交互式推荐过程的推荐策略。
(1)深度Q-Network
使用两个网络分别计算值函数V(i_t (G))和优势函数A(i_t (G),s_t (G)),Q值可以计算为,
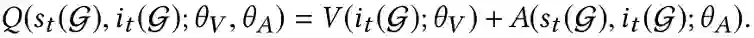
(2)模型训练
在交互式推荐过程中,在时间步t,推荐代理从用户的观察结果o_t中获取用户的状态s_t,并通过ϵ-贪婪策略推荐项目i_t。然后,代理从用户的反馈中接收奖励r_t,并将经验(o_t, i_t, r_t, o_(t+1))存储在缓冲区D中。从D开始,对小批量的经验进行采样,并最小化均方损失函数以改进Q-Network,定义为
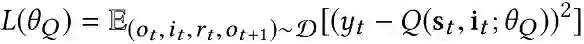
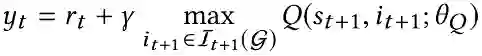
为了缓解原始DQN中的过拟合问题,利用了目标网络Q′和在线网络Q(即双DQN结构)。在线网络在每个训练步骤反向传播和更新其权重。目标网络是在线网络的副本,并随训练延迟更新其参数。然后,在线网络更新的目标值更改为
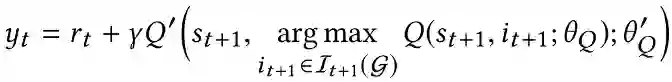
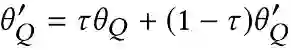
理论分析
实验
作者通过两个真实的基准数据集Book-Crossing和Movielens-20M对模型进行评估。实验中采用了三种指标进行评估:
① Average Reward:
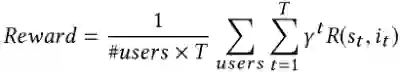
② Average Cumulative Precision@T:
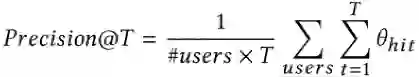
③ Average Cumulative Recall@T:
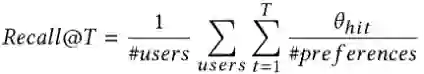
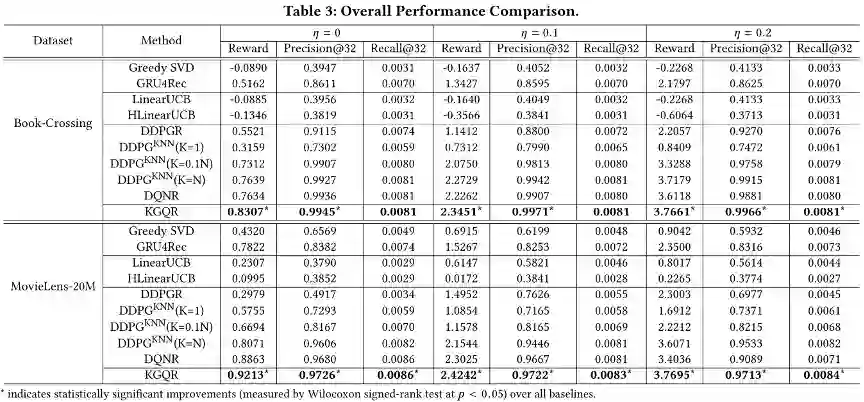
上表显示了KGQR与几种基线模型性能比较的结果。可以看出,KGQR始终在所有环境设置上获得了最好的性能。对于传统的评价指标,KGQR在两个数据集中分别将Precision@32提高了0.5%和1.9%。这表明,利用KG中的先验知识显著提高了推荐性能。在大多数情况下,非RL方法的表现都不如基于RL的方法。一方面,除了GRU4Rec外,其他非RL方法在不考虑序列信息的情况下,对用户偏好建模的能力有限。另一方面,它们专注于即时道具奖励,而不将整个序列的整体表现的值带入当前决策中,这使得这些模型在给予更多未来奖励的环境中表现更差。
利用KG的动机之一是在基于RL的推荐中提高样本效率,即减少实现相同性能所需的交互数据量。作者分析了每个基于DRL的模型实现相同性能所需的交互次数,如下图表所示。
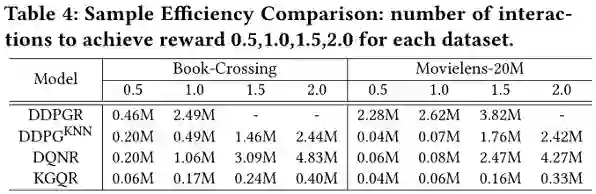
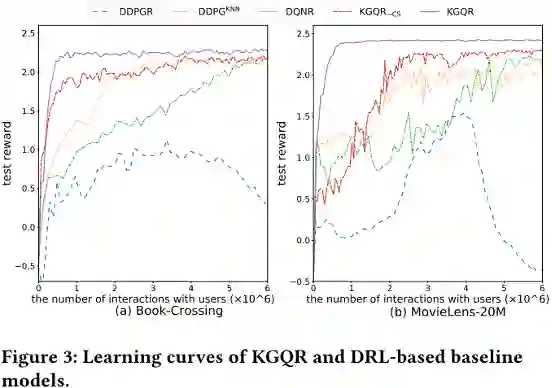
可以看出, KGQR可以用最少的交互次数实现与其他基于RL的方法相同的性能,这一结果验证了利用语义和相关信息提高样本效率的有效性。
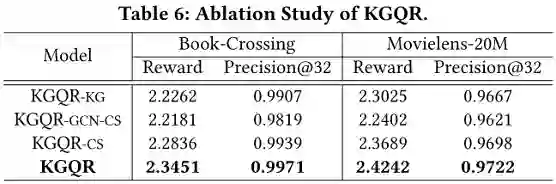
在KGQR中,有三个利用KG的组件可能会影响KGQR的性能:KG增强的项目表示、状态表示中的GCN传播和基于邻居的候选项选择。为了研究这些成分的有效性,作者评估了四种不同的KGQR变体,即KGQR_(-KG),KGQR_(-CS),KGQR_(-GCN-CS)和KGQR。下表显示了这四种变体的性能。
为了研究基于邻居的候选项大小的影响,在{1000, 2000, 3000, 5000, 10000}范围内改变候选项大小,并将推荐性能呈现在下图中。
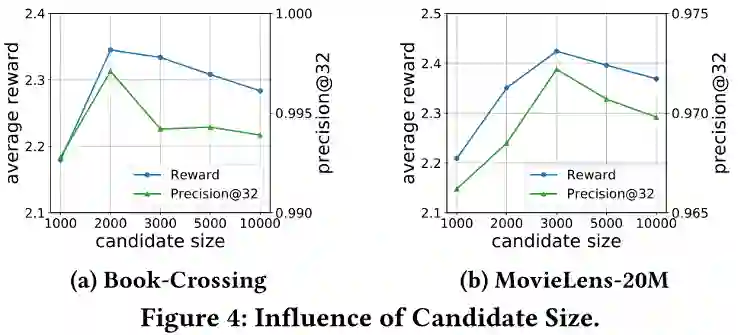
可以观察到推荐性能首先随着候选大小的增加而增长,因为较小的候选大小限制了推荐算法的可能选择。然而,由于基于邻居的候选选择预先过滤了一些不相关的项目,候选大小的进一步增加会降低性能。这些不相关的项目被推荐和收集反馈的机会非常有限,这使得它们无法通过推荐算法很好地学习,最终对性能产生负面影响。
总结
文章提出了一个用于交互式推荐的知识图谱增强Q-learning框架(KGQR)。这是首次在基于RL的交互式推荐系统中利用KG的工作,在很大程度上解决了样本复杂性问题,并显著提高了性能。此外,作者利用知识图谱的结构信息直接缩小行为空间,有效地解决了行为空间大的问题。在基于两个真实数据集的实验表明,与现有技术相比,该模型具有更高的采样效率和更高的性能。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。