摘要
知识图谱(KGs)以头-关系-尾三元组的形式捕捉知识,是许多人工智能系统的关键组成部分。关于知识图谱的推理有两个重要的任务:(1) 单跳知识图谱补全,即预测知识图谱中的个体链接;(2) 多跳推理,目标是预测哪些KG实体满足给定的逻辑查询。基于嵌入的方法解决了这两个任务,首先计算每个实体和关系的嵌入,然后使用它们来形成预测。然而,现有的可扩展的KG嵌入框架仅支持单跳知识图谱完成,不能应用于更具挑战性的多跳推理任务。在这里,我们提出了可扩展的多跳推理(SMORE),第一个单跳和多跳推理的KGs通用框架。SMORE的运行性能的关键是一种新的双向拒绝采样,实现了在线训练数据生成复杂性的平方根降低。此外,SMORE利用异步调度、基于重叠CPU的数据采样、基于GPU的嵌入计算和频繁的CPU-GPU IO。与之前的多跳KG框架相比,SMORE增加了2.2倍的吞吐量(即训练速度),且对GPU内存的需求最小(2GB用于在86m节点Freebase上训练400维嵌入),并实现了GPU数量的近似线性加速。此外,在更简单的单跳知识图谱完成任务上,SMORE在单GPU和多GPU设置上都达到了与最先进的框架相当甚至更好的运行时性能。
引言
知识图谱(KG)是一种异构的图结构,它捕获以头-关系-尾三元组形式编码的知识,其中头和尾是两个实体(即节点),关系是它们之间的边(例如,(Paris, CapitalOf, France))。知识图谱构成了跨广泛领域的许多人工智能系统的支柱: 推荐系统(Wang et al., 2018; Ying et al., 2018; Wang et al., 2019; Wu et al., 2019),问答(Berant et al., 2013; Sun et al., 2018; 2019a; Saxena et al., 2020; Ren et al., 2021)、常识推理(Lin et al., 2019; Feng et al., 2020; Yasunaga et al., 2021; Lv et al., 2020)、个性化医学(Ruiz et al., 2021)和药物发现(Zitnik et al., 2018; Ioannidis et al., 2020)。
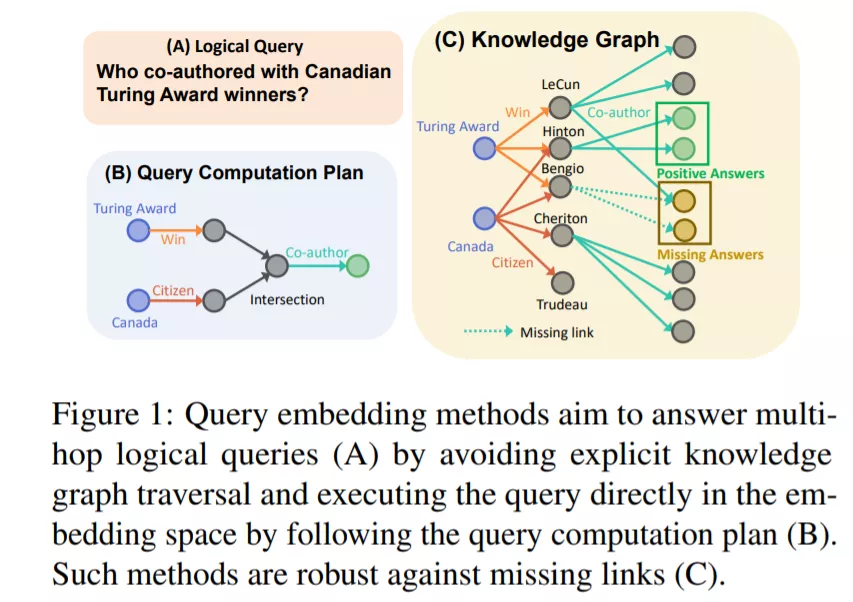
对此类KGs的推理包括两类任务: (1)单跳链接预测(也称为知识图谱补全),其中给定一个头和一个关系,目标是预测一个或多个尾实体。例如,图灵奖?(即,谁是图灵奖得主?),目标是预测实体GeoffHinton, DonKnuth等; (2)多跳推理,其中一个需要预测(一个或多个)多跳逻辑查询的尾部。例如,回答“谁是加拿大图灵奖得主的合作者?””(图1 (A)))。寻找这类查询的答案需要输入和预测两条并行路径上的多条边,同时还需要使用逻辑集运算(如交集、并集)。图1(B)显示了查询计算计划,为了确定实体是如此复杂的多跳查询的答案,通常需要隐式地推断缺失的链接,如图1(C)所示。请注意,这两个任务彼此密切相关。知识图补全可以看作是一个多跳推理任务的特殊情况,当查询由单个关系(例如,France-CapitalOf - ?)组成。多跳推理是知识图谱补全的一种严格的推广方法,具有更广泛的适用性,但也有其独特的计算和可扩展性挑战。
目前还没有框架支持在海量知识图谱上的多跳推理。例如,在最近的多跳推理(Hamilton et al., 2018; Ren et al., 2020; Ren & Leskovec, 2020; Sun et al., 2020; Guu et al., 2015; Das et al., 2017; Chen et al., 2021; Liu et al., 2021; Kotnis et al., 2021; Zhang et al., 2021; Choudhary et al., 2021)使用的最大KG只有63K个实体和592K个关系。此外,尽管存在可扩展的单跳KG完井框架(Zhu et al., 2019; Lerer et al., 2019; Zheng et al., 2020; Baidu NLP and Paddle Team, 2020; Mohoney et al., 2021),这种框架不能直接用于多跳推理,因为多跳推理任务的性质更加复杂。
大规模基于嵌入的多跳KG推理方法是许多真实世界人工智能应用的关键需求,但在很大程度上仍未探索。存在两个重大挑战: (1)在算法方面,给定一个巨大的KG(数以亿计的实体),实现训练实例不再可行,训练数据需要以高吞吐量进行有效的动态采样,以确保GPU得到充分利用。(2)在系统方面,最近的单跳大规模KG嵌入框架是基于图划分的(Zhu et al., 2019; Lerer et al., 2019; Zheng et al., 2020; Mohoney et al., 2021),这对于多跳推理是有问题的。多跳推理需要遍历图中的多个关系,这些关系通常跨越多个分区。
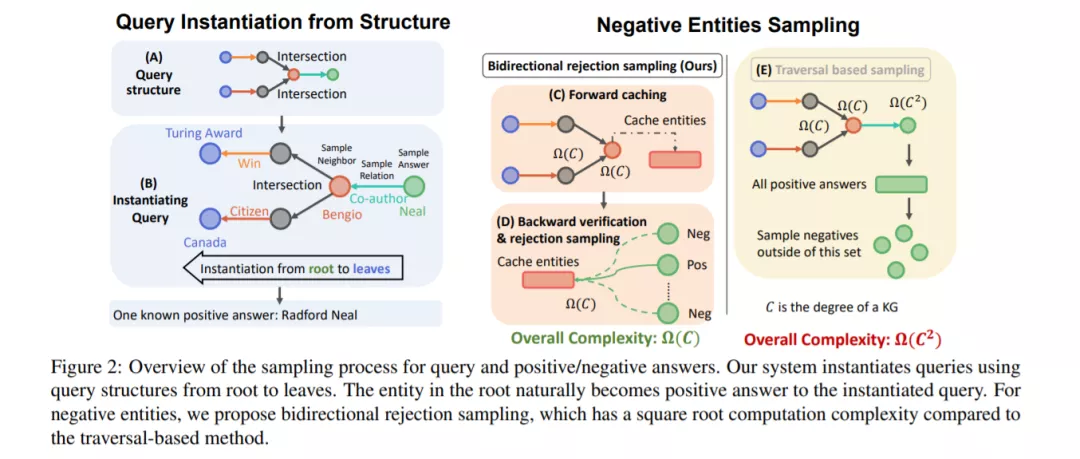
为了应对这些挑战,我们提出了可扩展多跳推理(Scalable MultihOp REasoning, SMORE),这是第一个在大规模KGs上进行单跳和多跳推理的通用框架。在算法方面,关键是在线高效地生成训练实例。为了生成具有一组正实体和负实体的训练示例,我们首先从一组查询逻辑结构(图2(a))实例化给定KG(图2(B))上的查询。实例化查询的根代表一个已知的正(答案)实体。为了获得一组负实体(非答案),简单执行查询计算计划(图1(B)),使用KG遍历(图1(C))来识别正/负实体,其复杂性与查询的跳数呈指数关系。因此,我们提出了一种双向拒绝抽样方法来有效地获取实例化查询的高质量负实体。训练数据采样器的关键思想是通过动态规划确定计算方案的最优节点割(图2(C)中的红色节点),同时进行正向KG遍历(图2(C))和反向验证(图2(D)),从而实现双向拒绝采样。最优切割中的节点缓存前向KG遍历的中间结果;对于向后验证,我们提出正的和负的候选实体,向后遍历最优切割,并基于前向和后向集的重叠执行拒绝抽样。这将最坏情况的复杂性降低了一个平方根,这使得在运行中生成一个训练查询、一个正答案实体和一个负非答案实体是可行的。
在系统端,SMORE直接在有多个GPU的共享内存环境中对整个KG进行操作,同时将嵌入参数存储在CPU内存中,以克服GPU内存的限制。该设计方案的选择绕过了目前KG嵌入系统中图划分用于多跳推理的潜在缺陷,但也带来了效率方面的挑战。我们设计了一个异步调度器,通过重叠采样、异步嵌入读写、神经网络前馈和优化器更新,使GPU计算的吞吐量最大化,如图5所示。结果,我们得到了一个有效的实现,可以实现线性加速与gpu的数量。
我们在三种多跳推理算法(GQE (Hamilton et al., 2018)、Q2B (Ren et al., 2020)、BetaE (Ren & Leskovec, 2020)、六种单跳KG完成方法(TransE (Bordes et al., 2013)、RotatE (Sun et al., 2019b)、DistMult (Yang et al., 2015)、ComplEx (Trouillon et al., 2016)、Q2B (Ren et al., 2016)上演示了SMORE的可扩展性。最大的是Freebase KG (Bollacker et al., 2008;Zheng et al., 2020),包含86M节点和338M边,比之前考虑的多跳推理的最大KG大约1500倍。新的采样技术将枚举搜索的最坏情况运行时提高了4个数量级。在小KGs上,与现有的(不可扩展的)多跳推理框架相比,SMORE运行速度快2.2倍,GPU内存使用量少30.6% (Ren, 2021)。SMORE还支持单跳推理。在这里,SMORE在单GPU和多GPU设置上都实现了与最先进的框架(不支持多跳推理)相当甚至更好的效率。
SMORE可以很容易地部署在对GPU内存容量有最低要求的单机环境中。例如,当使用8600万个实体在Freebase KG上训练400维的嵌入时,它使用不到2GB的GPU内存。SMORE的吞吐量几乎与GPU的数量成线性关系。SMORE还提供了一个易于使用的接口,在该接口中实现新的嵌入模型只需要不到50行代码。与基准一起,SMORE为加速未来在KGs上的多跳推理研究提供了一个测试平台。SMORE的开源地址为https://github.com/googleresearch/smore。