论文浅尝 | 面向开放域的无监督实体对齐
笔记整理 | 谭亦鸣,东南大学博士生

来源:DASFAA’21
链接:https://arxiv.org/pdf/2101.10535.pdf
概述与动机
知识图谱对齐的目的是建立两个不同知识图谱之间实体的对应关系,如图1,本文作者发现现有的实体对齐方法依赖于标注数据,且无法很好的识别出“不存在对齐”的实体。为了解决这个问题,本文提供了一个面向开放域的无监督对齐框架UEA(非监督实体对齐)。具体做法是,模型首先从图谱的边缘信息挖掘出可用特征,然后建立一个“无匹配实体”预测模块,用于过滤图谱中“不存在对齐”的实体。过滤得到的初步结果被用做“伪标注数据”,作用于一种渐进式学习框架,生成图谱的结构表示,这些结构与边缘信息的结合能够提供更加全面的对齐视图。最后渐进式学习框架基于上一迭代的对齐结果生成新的伪标注数据,并不断增强对齐模型的性能。在不依赖标注数据的情况下,本文模型在DBP15K等常规对齐数据集上取得了较好的结果。
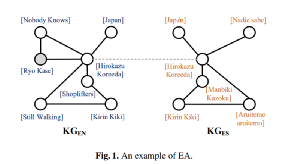
图2描述了UEA模型的主要流程,首先模型从待对齐的两个知识图谱的边缘信息中抽取有用的特征,这里的边缘信息主要指实体命名,通过语义级别以及字符串级别的特征信息,作者构建了图谱中实体之间的距离矩阵:
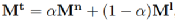
其中,α是一个平衡权重的超参,Mn表示KG上实体命名的语义距离矩阵,Ml则表示字符串级别的距离矩阵。
通过这一步所获取的距离矩阵被用于建立“无匹配实体”模块,用于生成对齐结果,该对齐结果被视作伪对齐用于知识图谱结构embedding中,从而形成一个迭代过程。
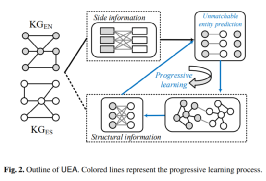
非对齐实体模块
现有的对齐模型只考虑了如何建立对齐,而忽略了有些实体之间是不可能存在对齐关系的情况,例如类型不同的实体。因此这里作者采用了一个新的策略,如算法1所描述的TBNNS(带阈值双向最近邻搜索),对于一个给定的source实体u,及target实体v,如果u和v相互是最近邻,那么他们之间的相似性则低于一个给定的阈值θ,(u,v)就为一堆对齐实体组,M(u,v)是度量两者是否符合阈值的距离矩阵。

渐进学习框架
非匹配实体模块得到的伪标注被用于学习统一的KG embedding,在这里作者使用GCN用来捕捉实体的邻居信息。算法2给出了渐进学习模块对应的算法:
首先使用初始伪对齐学习KG结构embedding,并得到结构距离矩阵Ms,Ms与非匹配模块中定义的Mt矩阵共同构成精确的对齐距离信号矩阵M。利用M可用生成更多的精准匹配,而后迭代强化自身。

与其他对齐模型一样,本文的实验性能在DBP15K的三组语言对上给出,数据的相关统计信息如表1
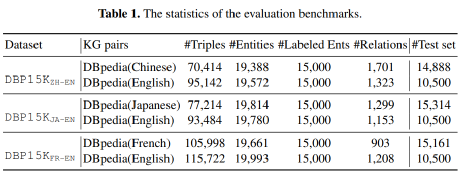
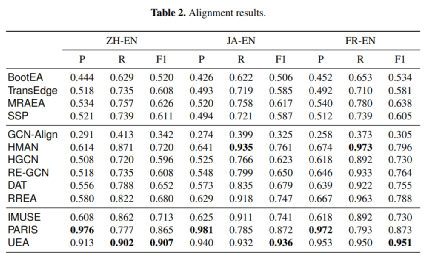
表2的对比结果来看,该非监督方法在性能上以及接近或超过了许多已有的有监督学习的模型。
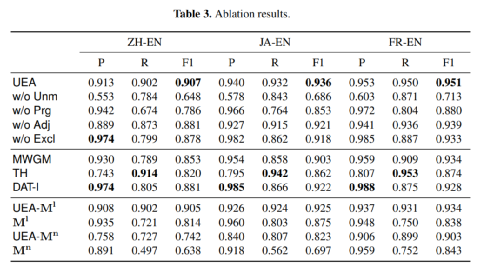
接着作者在消融实验中重点验证了是否调整阈值,是否在迭代过程中从实体集除去实体的对齐结果等等,结果如表3所展示。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。





