在深度学习顶会ICLR 2020上,Transformer模型有什么新进展?
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要11分钟
跟随小博主,每天进步一丢丢


ICLR是机器学习社群最喜爱的会议平台之一。如今,机器学习领域的会议已成为预印本里论文质量的标志和焦点。但即使这样,论文的发表数量还是越来越庞大,这使得紧跟最新进展变得困难。
在Zeta Alpha,我们会密切关注自然语言处理(NLP)和信息检索(IR)领域研究的最新进展。本着这种精神,在我们的语义搜索引擎的帮助下,我们从ICLR 2020 40篇与Transformer模型相关的论文中精选了9篇,涵盖了架构改进,训练创新和其他应用这三个方面。
架构改进
了解transformer模型的最近更新。
ALBERT:用于语言表征自监督学习的轻量BERT模型
Transformer模型在很大程度上已过参数化,因为这是在很多NLP任务中表现优异的一种有效方式。而ALBERT则是一个可以使BERT减少资源占用,同时又保持出色性能的很有影响力的例子。
这些优化包括:
-
因式分解词向量参数:通过使用不同的隐单元大小,而不是词向量原来大小,词向量参数可被因式分解,让其大小从O(Vocab × Hidden) 降低到 O(Vocab × Emb + Emb × Hidden) 。如果其中Hidden 远大于 Emb的话,参数量的降低将是巨大的; -
交叉层参数共享:共享不同transformer组件的参数,例如FFN 或注意力权重; -
句子排序目标任务:作者认为下句预测在原始的BERT模型中不够具有挑战性,因此引入了这一新的句子层级的自监督目标。
结果如何?以比BERT-large少18倍的参数实现相当的性能和稍快的运算。
论文链接:
https://openreview.net/pdf\?id=H1eA7AEtvS
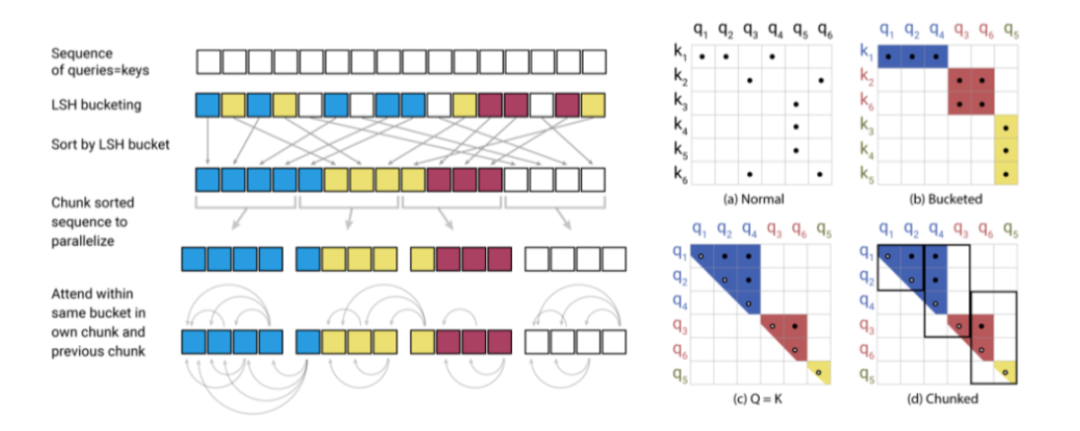
Reformer:一种高效的Transformer
早期Transformer模型的一大局限性在于,注意力机制的计算复杂度与序列长度成二次关系。这篇文章介绍了一些提高计算效率的技巧,使得模型能实现更长的注意力序列(长度从512上升到64K!)。
为此,该模型主要包括:
-
仅允许在整个模型中 存储单个激活单元副本的可逆层; -
用位置敏感哈希法(LSH)近似用快速最近邻算法计算的注意力值。这一方法用计算复杂度为O(L log L)的注意力层替代了之前计算度为O(L^2)的注意力层。
论文链接:
https://openreview.net/pdf\?id=rkgNKkHtvB
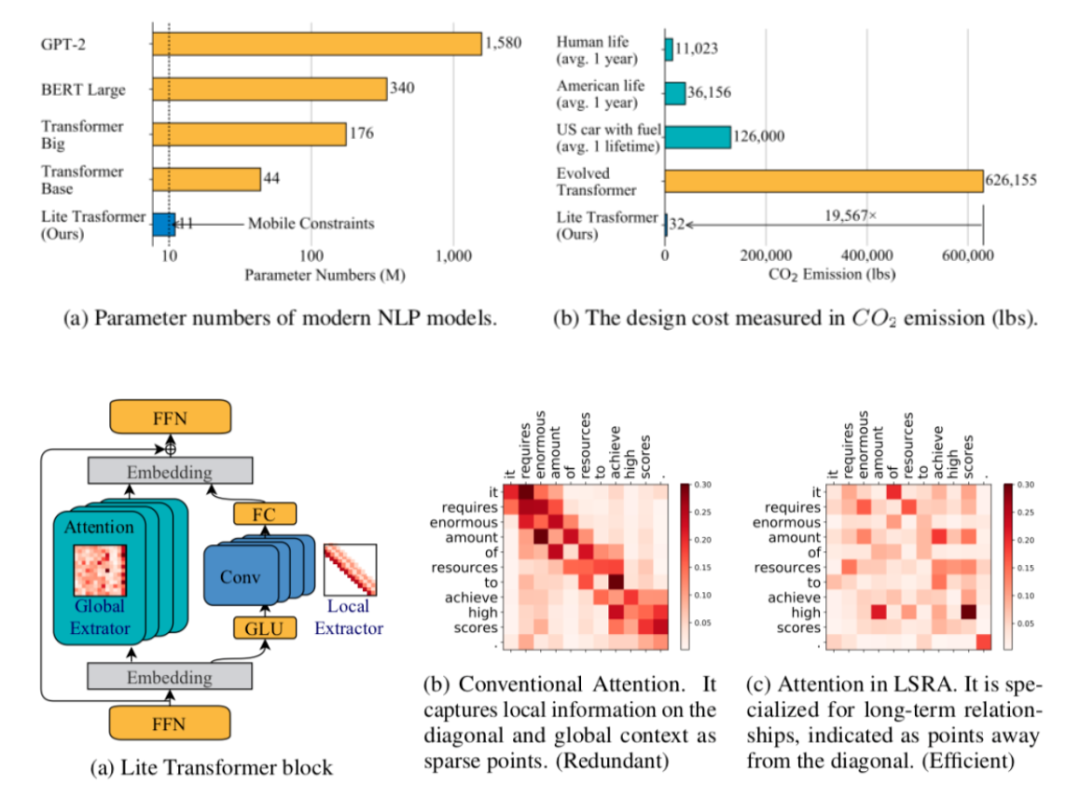
使用长短距离注意力模型(LSRA)的轻量级Transformer
另一个针对解决Transformer模型远程相关性和高资源需求问题的方案是施加“移动约束”。通过对短期相关性使用卷积层,对长期相关性使用经筛选的注意力层,他们构建了一个新的效率更高的Transformer组件LSRA。
尽管结果比不上其他成熟的Transformer模型,其基本的架构设计和经过深思的研究动机使其值得关注。
论文链接:
https://openreview.net/pdf\?id=ByeMPlHKPH
提名奖(Honorable mentions)
Transformer-XH:
https://openreview.net/pdf\?id=r1eIiCNYwS
Depth-Adaptive Transformer:
https://openreview.net/pdf\?id=SJg7KhVKPH
Compressive Transformer:
https://openreview.net/pdf\?id=SylKikSYDH
关于训练方法
模型如何进行训练学习和模型架构同样重要,所以一些新的文章在这方面有了突破。
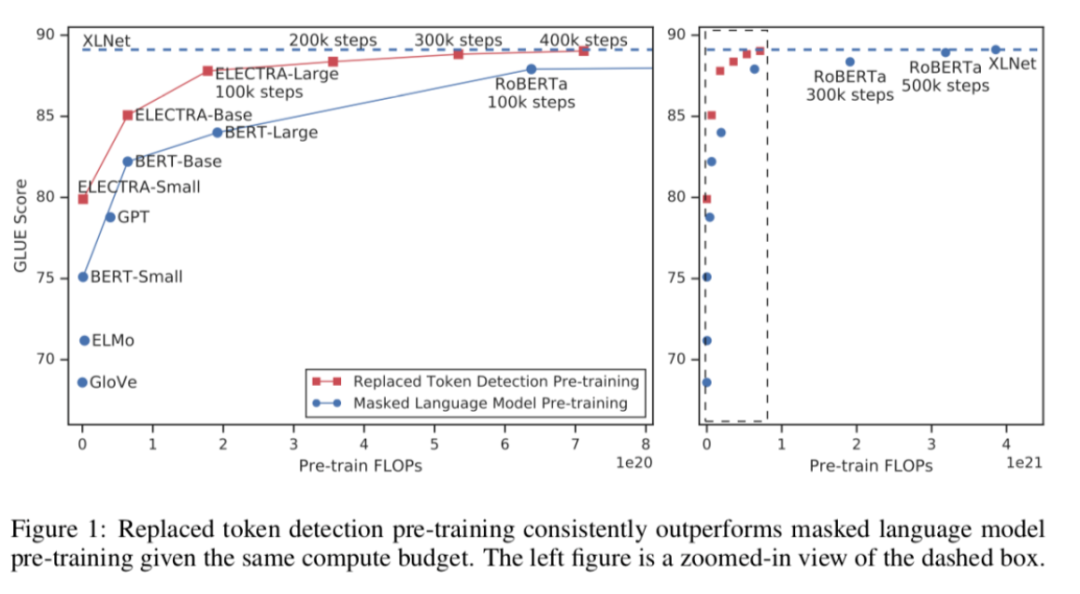
ELECTRA:预训练文本编码器作为区分器而不是生成器
从BERT引入之后,掩码语言模型(MLM)一直是预训练任务的基础模型。这篇文章提出了一种更低耗更快速的方法:替换字符检测 (Replaced Token Detection)。
其中心思想十分简单:不是让模型猜测被掩盖的字符,而是需要其区分哪些字符已被一个小的生成网络替换,该生成网络将产生合理但错误的token。作者声称这个任务更具有样本有效性,因为该任务是在整个序列上训练而不仅仅是被掩盖的字符上。如果结果证明它们很容易被复现,那这一方法很可能成为无监督学习的新标准。
论文链接:
https://openreview.net/pdf\?id=r1xMH1BtvB
TabFact:一个基于表的事实验证大规模数据集
现代Transformer 模型缩小了机器和人类表现上的差距,很多经典的NLP数据集也随着被废弃,这意味着需要创造出更多新的有挑战性的基准测试来激励前进。因此,一个新的数据集被提出,用于解决对基于事实信息的自然语言表达进行建模的问题。
这一数据集用包括来自维基百科的1万6千个表格和来自人工标注为ENTAILMENT或者REFUTED的11万8千个标签来表示事实数据。目前基模型的表现还很一般,所以现在如何创新性地解决这一问题仍令人激动。

论文链接:
https://openreview.net/pdf\?id=rkeJRhNYDH
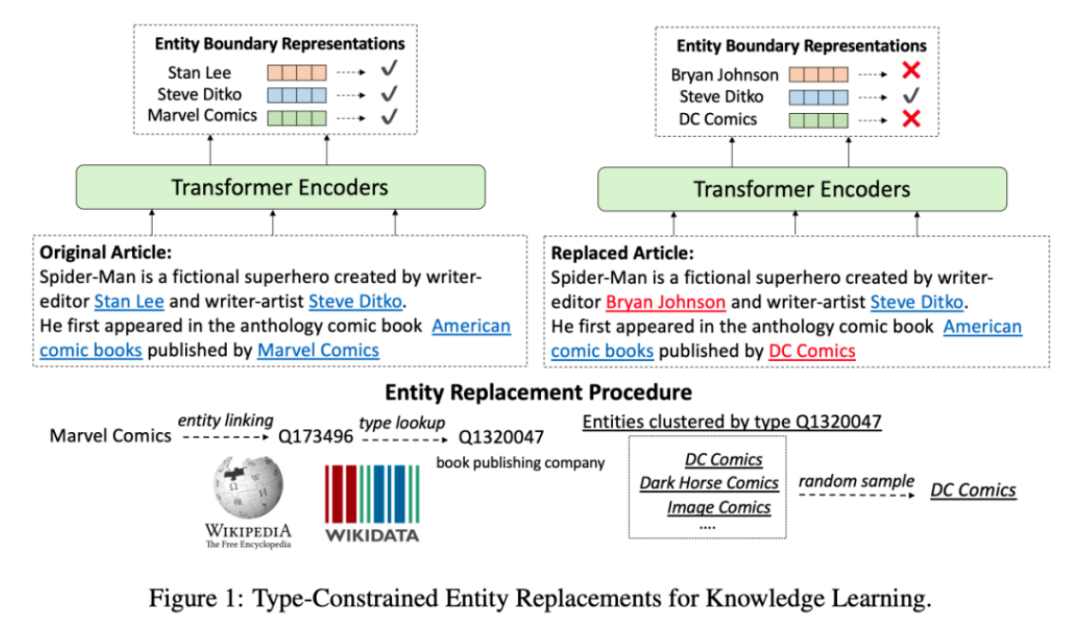
经过预训练的百科全书:弱监督知识预训练语言模型
这篇文章用更结构化的数据:维基百科和它其中实体来研究自监督训练的能力,而不是应用普通的MLM模型。他们用其他相似类型的实体(如ELECTRA)替换了文本中的实体,模型学习通过上下文来识别这种被替换的句子。通过这种方法,模型被强制学习了现实世界实体的信息,以及它们之间的关系。
这一任务与经典的MLM在预训练时的结合,其能够大大提高Zero-shot实现以及以实体为中心的任务(例如问答和实体输入)的表现。
论文链接:
https://openreview.net/pdf\?id=BJlzm64tDH
提名奖(Honorable mentions):
A Mutual Information Maximization Perspective of Language Representation Learning:
https://openreview.net/pdf\?id=rkxoh24FPH
Improving Neural Language Generation with Spectrum Control:
https://openreview.net/pdf\?id=ByxY8CNtvr
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes:
https://openreview.net/pdf\?id=Syx4wnEtvH
其他应用
Transformer模型不仅仅使用于语言建模中,有些其他的工作也巧妙地应用了这一模型的能力来解决相关问题。
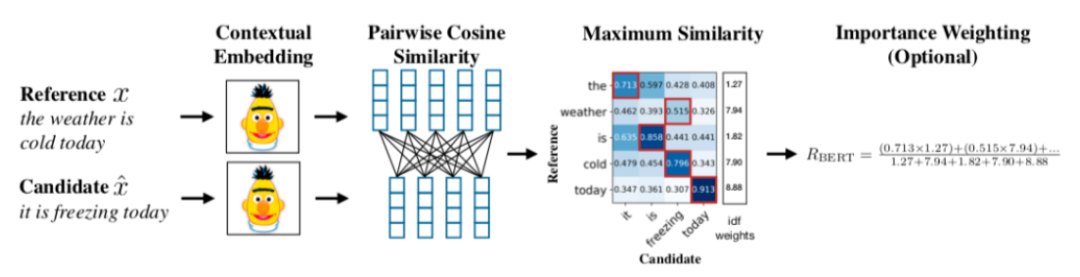
BERTScore:用BERT评估文本生成
在定义宽松的环境(如核心文本生成)中客观地评价质量具有固有的挑战性。在语言中,BLUE评分,作为一种与人类对于文本生成任务(如翻译或问题回答)的判断能够较好吻合的文本相似度代理,被广泛使用。但它并不完美。
这一工作解决了这一问题,展示了一个用于序列配对的基于Bert的评分功能如何被设计用于文本生成评估,并能更好地与人类评估吻合。这一过程非常直观,并需要任何精调:只需要经过预训练的上下文嵌入,cosine相似度和基于频率的权重。
尽管在解释性上有些不足,这种经过学习的评分是否会成为一种新的标准呢?这还要交给时间来判断了。
论文链接:
https://openreview.net/pdf\?id=SkeHuCVFDr
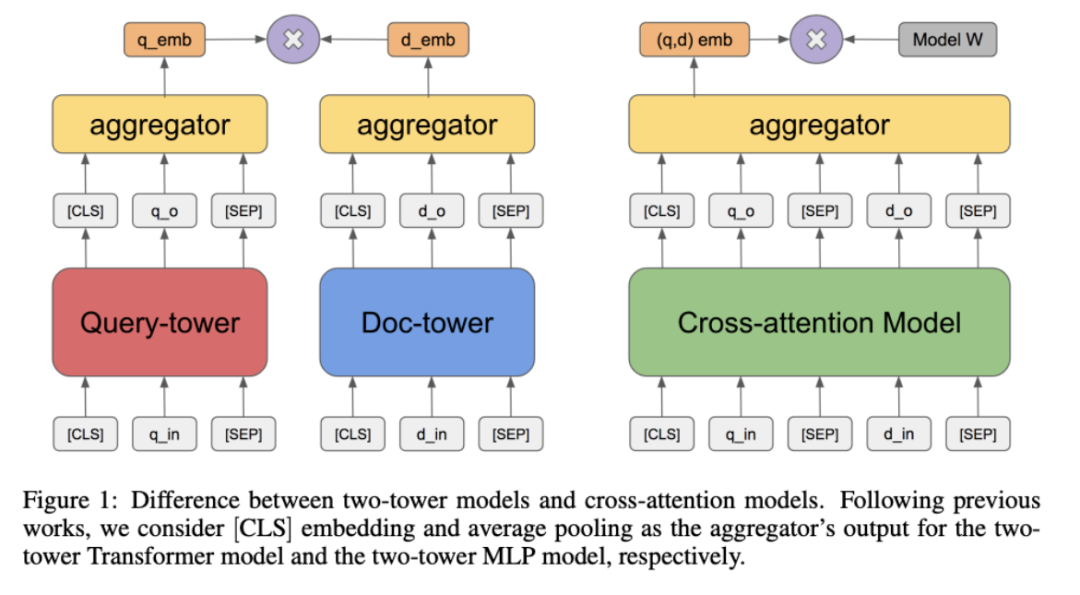
用于基于向量大规模检索的预训练任务
考虑到像BM25这样的基准方法的强大和难以击败,信息检索领域已经落后于神经革命。
现在大多数神经增强的SOTA方法需要两个关键步骤:
-
基于类似BM25的算法对全文档数据集快速过滤;
-
通过神经网络对query和一个较小的文档子集进行处理实现再排序。
这种方法有很多局限性,第一步忽略掉的文档将不会再被处理,而且在推断阶段完全处理query和文档对的计算成本会严重限制其在现实场景中的应用。
这篇文章探索了只通过预计算好文档表示的向量相似度分数来进行推断的问题,使得大规模的端到端的基于Transformer模型的检索成为可能。
其中关键在于具有段落级自监督任务的预训练,而token级的MLM对于这一任务的作用则几乎可忽略不计。在结果部分,他们展示了即使在相对缺乏监督的训练集下,这一方法也在问答任务中击败BM25。
论文链接:
https://openreview.net/pdf\?id=rkg-mA4FDr
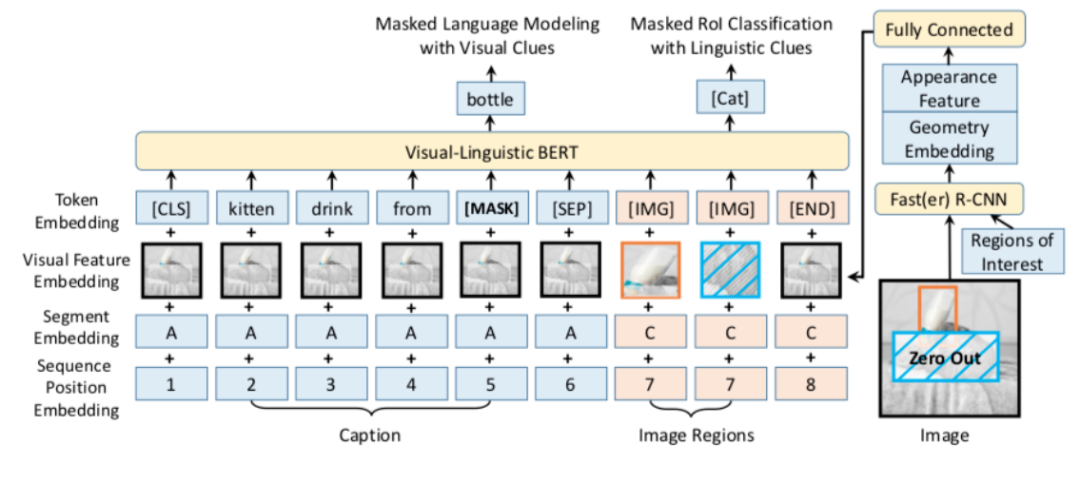
VL-BERT:通用视觉语言表征的预训练
预训练和精整框架如何应用于通用语言和可视化表示的结合学习中?我们找到一个很好的案例:Visual-Linguistic BERT 以Transformer架构为主干,与R-CNNs相结合。尽管这不是同类模型中的首个,但它是对现存模型的更新与提高,并且将Visual Commonsense Reasoning(VCR)的基准提高到一个新的高度。
这一预训练步骤依赖两大任务:
-
具有视觉线索的掩盖语言建模:和原始的MLM模型相似,但加入了被添加说明文字的图片区域的特征; -
具有语言线索的掩盖兴趣区域分类:在一定概率下,图片的一些区域被掩盖,目标是在给出语言信息的情况下预测这些被掩盖区域的类型。
论文链接:
https://openreview.net/pdf\?id=SygXPaEYvH
福利:自注意力与卷积层的关系
这一非传统的文章强有力地分析了注意力机制和卷积网络的共同点。有趣的是,他们找到了比大家先前预想的更多的重合点:他们的证据表明,注意力层通常会使用与CNN相似的像素-网格模式。
以计算机视觉为例,加上详细的数学推导,他们发现Transformer架构或许是CNN的一种推广,因为他们经常学习与CNN相同的模式,甚至因为能够同时学习局部和全局信息而展现出优势。

论文链接:
https://openreview.net/pdf\?id=HJlnC1rKPB
提名奖(Honorable mentions):
Deep Learning For Symbolic Mathematics:
https://openreview.net/pdf\?id=S1eZYeHFDS
Logic and the 2-Simplicial Transformer (for Deep RL)
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记

整理不易,还望给个在看!




