谷歌自动重建了完整果蝇大脑神经图:40万亿像素,可在线交互,用了数千块TPU
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

乾明 发自 凹非寺
本文转载自:量子位(QbitAI)
研究大脑神经网络,又有新进展。
谷歌AI发布博客文章宣布最新研究成果:
用Flood-Filling网络和Local Realignment,基于果蝇的大脑切片自动重建出了完整的果蝇大脑神经图。
论文链接:
https://www.biorxiv.org/content/early/2019/08/04/605634.full.pdf
整个脑神经图的像素高达40万亿,重建的过程用了数千块TPU。
谷歌AI,还开发了一个名为Neuroglancer的3D交互界面,任何人都可以下载或在线浏览结果。

而且,相应的工具与算法,谷歌AI也已经开源了。
在线观看链接:
https://bit.ly/2GKmDF2
社交媒体上,也有网友给出了这项技术的应用前景:
如果算法是正确的,就意味着我们现在可以映射整个@realDonaldTrump的大脑。
也有人感叹,自己13年前也参与了果蝇大脑的重建工作,但不幸的是,当时没有TPU和SECGAN。
如何自动重建果蝇脑神经图?
根据谷歌AI的介绍,重建果蝇大脑大体分为3个步骤:
首先,他们在霍华德·休斯医学研究所(HHMI)的研究合作伙伴,将果蝇的大脑切片,做成了成千上万个超薄的40纳米薄片。
其次,用透射电子显微镜成像技术对每一片进行成像,产生了超过40万亿像素的大脑成像。
最后,将这些2D图像对齐成3D果蝇大脑图像。

整个过程,谷歌AI使用了数千个TPU进行计算,而且应用了Flood-Filling网络来自动追踪果蝇大脑中的每一个神经元。
虽然算法整体表现良好,但他们发现,由于对齐不完善(连续切片中的图像内容不稳定),会出现多个切片在成像过程中丢失的情况,这直接会导致性能下降。
为了解决这个问题,谷歌AI采取了两个措施。
一是,估计3D图像中各个区域中切片到切片的一致性,在Flood-Filling网络跟踪每个神经元的时候,局部稳定图像内容。
二是,应用分割-增强CycleGAN(SECGAN)来计算缺失的切片。
谷歌AI介绍称,当使用SECGAN的图像数据时,Flood-Filling网络能够更好地追踪多个缺失切片的位置。
40万亿像素下的可视化
拼接好了之后,怎么呈现?
谷歌AI表示,处理包含数万亿像素的3D 图像和具有复杂形状的物体时,可视化既是必要的,也是困难的。
他们设计了一个新的工具Neuroglancer,就有可扩展性和强大的功能。只要有支持 WebGL 的浏览器都可以访问。
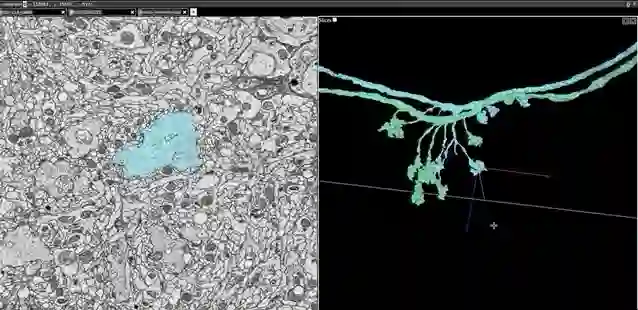
而且,也支持许多高级功能,比如对任意轴横截面重新排列、多分辨率网格,以及通过与 Python集成开发自定义分析工作流的强大能力。
目前,这个工具已经开源,被艾伦脑科学研究所、哈佛大学、HHMI、马克斯普朗克研究所、麻省理工学院、普林斯顿大学和其他地方的研究者大量使用。
项目链接:
https://github.com/google/neuroglancer
下一步的研究
在谷歌AI的规划中,这只是一个开始。
谷歌表示,他们在HHMI和剑桥大学的合作者,已经开始使用这种重建技术来加速研究果蝇大脑的学习、记忆和感知。
但是,上述结果还不是一个真正的神经元链接图,因为需要确定突触。
不过,谷歌AI表示,他们正在与HHMI的研究团队合作,利用“FIB-SEM”技术获得的图像,创建一个高度验证和详尽的果蝇大脑连接体。
谷歌AI博客链接:
https://ai.googleblog.com/2019/08/an-interactive-automated-3d.html
— 完 —
重磅!CVer学术交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!




