如何应用TFGAN快速实践生成对抗网络?

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
本文主要讲解 TFGAN 如何应用于原生 GAN、CGAN、InfoGAN、WGAN 等场景,如下所示:

其中,原生 GAN 生成的 Mnist 图像不可控:CGAN 可按照数字标签生成相应标签的数字图像;InfoGAN 可认为是无监督的 CGAN,前两行表示用分类潜变量控制数字的生成类别,中间两行表示用连续型潜变量控制数字的粗细,最后两行表示用连续型潜变量控制数字的倾斜方向;ImageToImage 是 CGAN 的一种,实现图像的风格转换。
GAN 由 Goodfellow 首先提出,主要由两部分构成:Generator(生成器),简称 G;Discriminator(判别器), 简称 D。生成器主要用噪声 z 生成一个类似真实数据的样本,样本越逼真越好;判别器用于估计一个样本来自于真实数据还是生成数据,判定越准确越好。如下图所示:
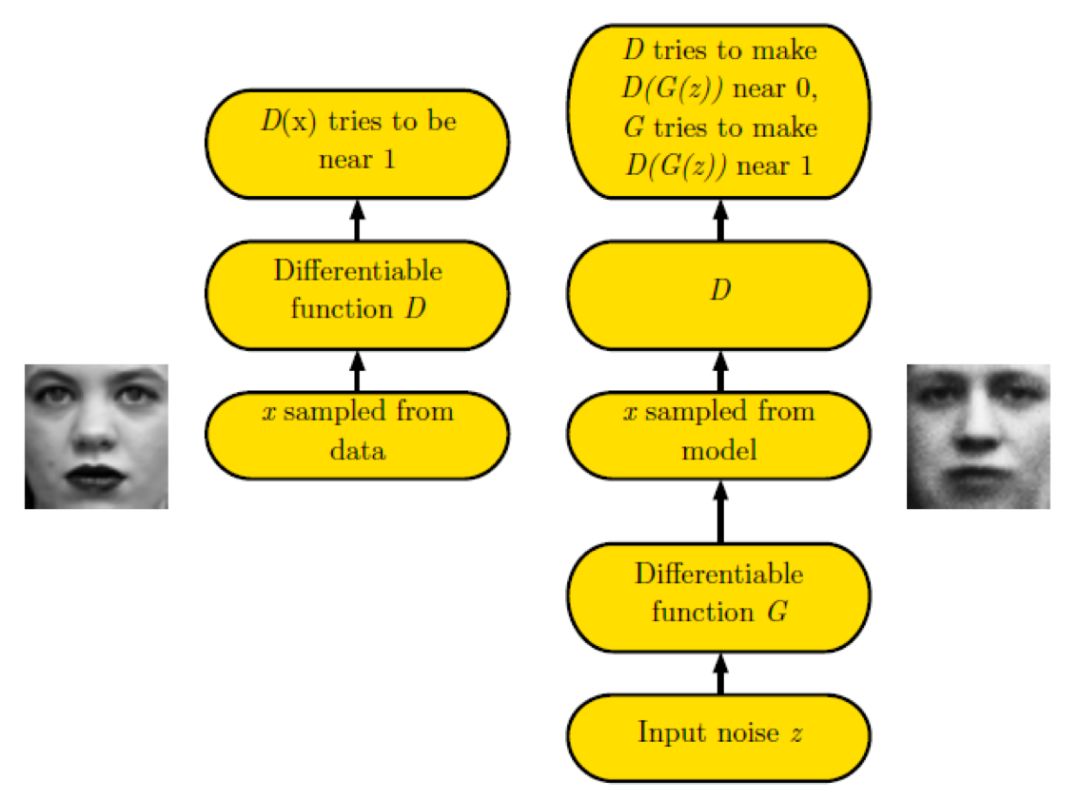
上图中,对于真实的采样数据,通过判别网络后,生成 D(x)。D(x) 的输出是 0-1 范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。这样对于真实数据,D(x) 越接近 1 越好。对于随机噪声 z,通过生成网络 G 后,G 将这个随机噪声转化为生成数据 x。如果是图片生成问题,G 网络的输出就是一张生成的假图片,用 G(z) 表示。判别模型 D 要使得 D(G(z)) 接近与 0,即能够判断生成的图片是假的;生成模型 G 要使得 D(G(z)) 接近于 1,即要能够要欺骗判别模型,使得 D 认为 G(z) 生成的假数据是真的。这样通过判别模型 D 和生成模型 G 的博弈,使得 D 无法判断一张图片是生成出来的还是真实的而结束。
假设 P_r 和 P_g 分别代表真实数据的分布与生成数据的分布,这样判别模型的目标函数可以表示为:
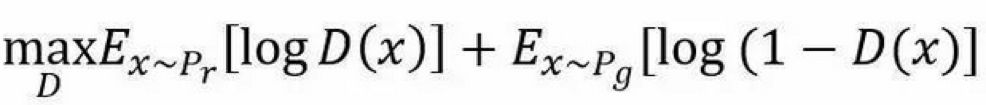
而生成模型的是让判别模型 D 无法区别真实数据与生成数据,这样优化目标函数为:
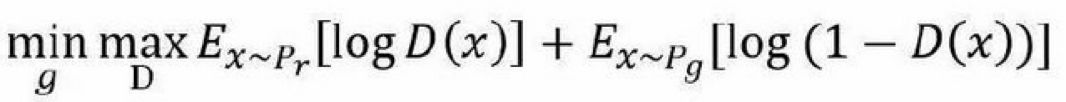
TFGAN 库的地址为 https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/gan, 主要包含以下几个组件:
核心架构,主要包括创建 TFGAN 模型,添加 Loss 值,创建训练 operation,运行训练 operation。
常用操作,主要提供了梯度修剪操作,归一化操作及条件化操作等。
损失函数,主要提供了 GAN 中常用的损失和惩罚函数,如 Wasserstein 损失、梯度惩罚、互信息惩罚等。
模型评估,提供了 Inception Score 和 Frechet Distance 指标,用于评估无条件生成模型。
示例,谷歌同时开源了常用的 GAN 网络示例代码,包括 unconditional GAN,conditional GAN, InfoGAN,WGAN 等。相关用例可从 https://github.com/tensorflow/models/tree/master/research/gan/ 地址下载。
使用 TFGAN 库训练 GAN 网络主要包含如下几个步骤:
确定 GAN 网络的输入,如下所示:
设定 GANModel 中的生成模型和判别模型,如下所示:
设定 GANLoss 中的损失方程,如下所示:
设定 GANTrainOps 中的训练操作,如下所示:
运行模型训练,如下所示:





CGAN(Conditional Generative Adversarial Nets),针对 GAN 本身不可控的缺点,加入监督信息,训练从无监督变成有监督,指导 GAN 网络进行生成。例如输入分类的标签,可生成相应标签的图像。这样 CGAN 的目标方程可以转换为:
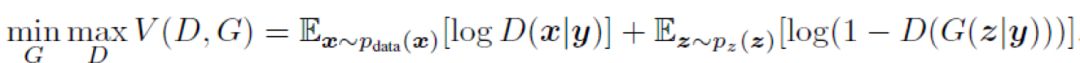
其中,y 是加入的监督信息,D(x|y) 表示在 y 的条件下判定真实数据 x,D(G(z|y)) 表示在 y 的条件下判定生成数据 G(z|y)。例如,MNIST 数据集可根据数字 label 信息,生成相应标签的图片;人脸生成数据集,可根据性别、是否微笑、年龄等信息,生成相应的人脸图片。CGAN 的架构如下图所示:
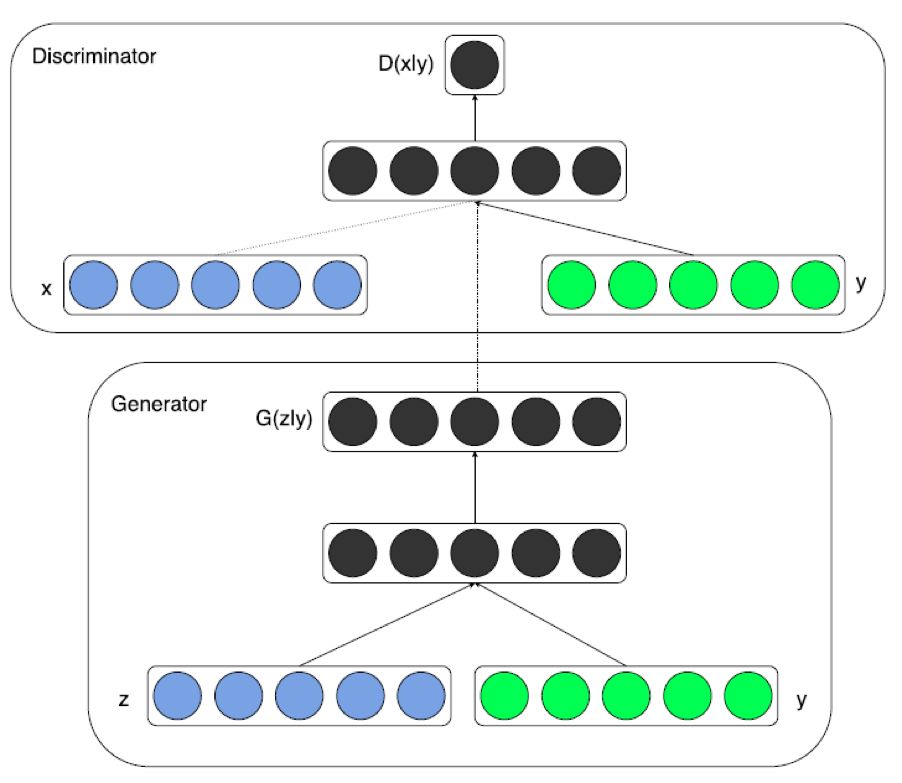
在 TFGAN 中提供了,基于 one_hot_labels 变量和输入 tensor 生成 condition tensor 的 API,如下所示:
tfgan.features.condition_tensor_from_onehot
(tensor, one_hot_labels, embedding_size)其中,tensor 为输入数据,one_hot_labels 为 onehot 标签,shape 为 [batch_size, num_classes],embedding_size 为每个 label 对应的 embedding 大小,返回值为 condition tensor。
Phillip Isola 等提出了基于 CGAN 的图片生成图片的对抗神经网络《Image-to-Image Translation with Conditional Adversarial Networks》。网络设计的基本思想如下所示:
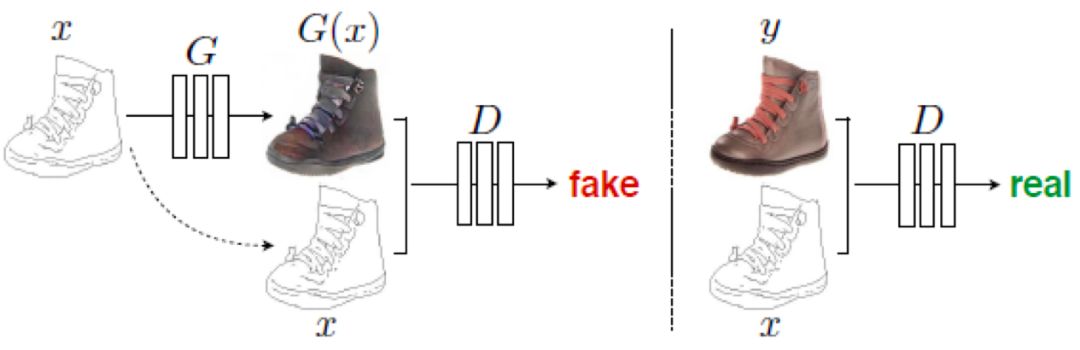
其中,x 为输入的线条图,G(x) 为生成图片,y 为线条图 x 对应渲染后的真图片,生成模型 G 用于生成图片,判断模型 D 用于判定生成图片的真假。判别网络能够最大化判断 (x,y) 的数据为真,判断 (x,G(x)) 数据为假。而生成网络使得判别网络判断 (x,G(x)) 数据为真,从而进行生成模型和判别模型的相互博弈。为了使生成模型不仅能够欺骗判别模型,还要使得生成图像要像真实图片,这样在目标函数中加入了真实图像和生成图像的 L1 距离,如下所示:
TFGAN 库,提供了 ImageToImage 生成对抗网络的相关损失方程 API 使用示例,如下所示:
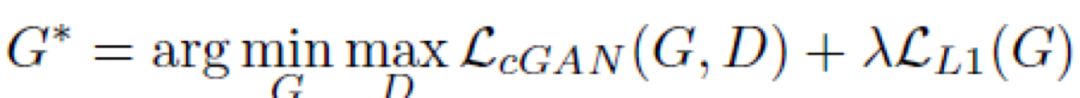
# 定义真实数据与生成数据的 L1 损失

# gan_loss 为目标函数损失
gan_loss = tfgan.losses.combine_adversarial_loss
(gan_loss, gan_model, l1_pixel_loss, weight_factor=FLAGS.
weight_factor)在 GAN 中,生成器用噪声 z 生成数据时,没有加任何的条件限制,很难用 z 的任何一个维度信息表示相关的语义特征。所以在数据生成过程中,无法控制什么样的噪声 z 可以生成什么样的数据,在很大程度上限制了 GAN 的使用。InfoGAN 可以认为是无监督的 CGAN,在噪声 z 上增加潜变量 c,使得生成模型生成的数据与浅变量 c 具有较高的互信息,其中 Info 就是代表互信息的含义。互信息定义为两个熵的差值,H(x) 是先验分布的熵,H(x|y) 代表后验分布的熵。如果 x,y 是相互独立的变量,那么互信息的值为 0,表示 x,y 没有关系;如果 x,y 有相关性,那么互信息大于 0。这样在已知 y 的情况下,可以推断出那些 x 的值出现高。这样 InfoGAN 的目标方程为:
InfoGAN 的网络结构如下所示:
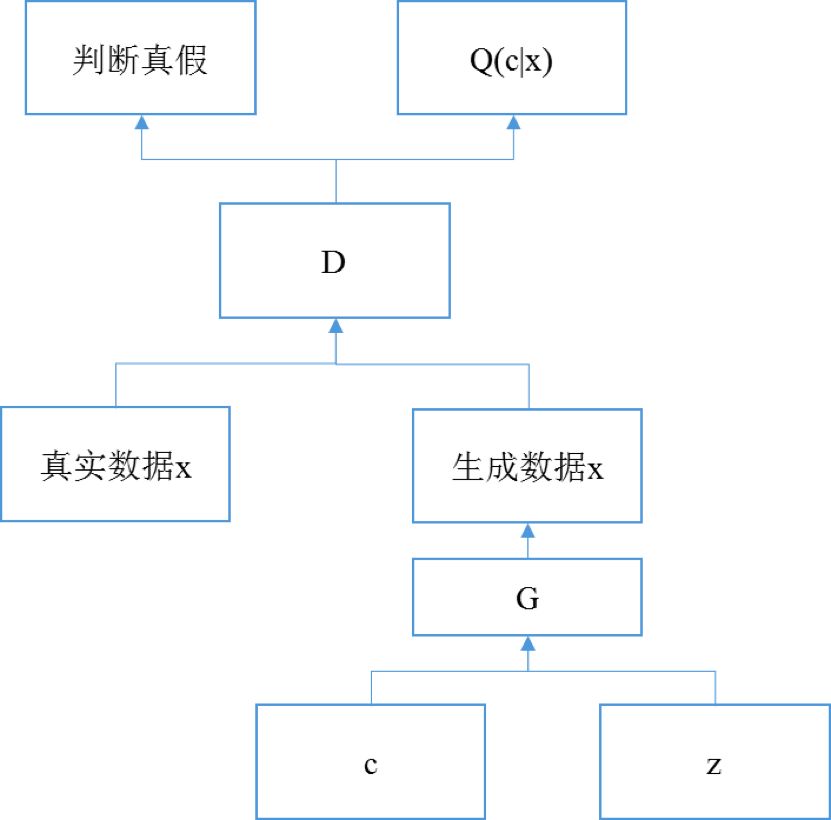
上图中 InfoGAN 与 GAN 的区别在于,对应判别网络的输出 D(x),生成变分分布 Q(c|x),从而能用 Q(c|x) 来逼近 P(c|x),从而增大生成数据与潜变量 c 的互信息。TFGAN 中提供了 InfoGan 相关 API,如下所示:
# 通过 tfgan.infogan_model,定义 infogan 模型

# 通过 tfgan.gan_loss,生成 infogan 模型的 loss 值:

# InfoGan 的 Loss 值为在 GAN 的 loss 值上,加上互信息 I(c;G(z,c)),TFGAN 中提供了互信息计算的 API,如下所示。其中 structured_generator_inputs 为潜变量的噪音信息,predicted_distributions 为变分分布 Q(c|x)。

Martin Arjovsky 等提出了 WGAN(Wasserstein GAN),解决了传统 GAN 训练困难、生成器和判别器的 loss 很难指示训练进程、生成样本缺乏多样性等问题,主要有以下优点:
能够平衡生成器和判别器的训练程度,使得 GAN 的模型训练稳定。
能够保证生产样本的多样性。
提出使用 Wasserstein 距离来衡量模型训练的程度,数值越小表示训练得越好,成器生成的图像质量越高。
WGAN 的算法与原始 GAN 算法的差异主要体现在:
去掉判别模型最后一层的 sigmoid 操作。
生成模型和判别模型的 loss 值不取 log 操作。
每次更新判别模型的参数之后把模型参数的绝对值截断到不超过固定常数 c。
使用 RMSProp 算法,不用基于动量的优化算法,例如 momentum 和 Adam。
WGAN 的算法结构如下所示:

TFGAN 中提供了 WGan 相关 API,如下所示:
#生成网络损失方程
generator_loss_fn=tfgan_losses.wasserstein_generator_loss#判别网络损失方程
discriminator_loss_fn=tfgan_losses.wasserstein_discriminator
_loss本文首先介绍了生成对抗网络和 TFGAN,生成对抗网络模型用于图像生成、超分辨率图片生成、图像压缩、图像风格转换、数据增强、文本生成等场景;TFGAN 是 TensorFlow 库,用于快速实践各种 GAN 模型。然后讲解了 CGAN、ImageToImage、InfoGAN、WGAN 模型的主要思想,并对关键技术进行了分析,主要包括目标函数、网络架构、损失方程及相应的 TFGAN API。用户可基于 TFGAN 快速实践生成对抗网络模型,并应用到工业领域中的相关场景。
参考文献
[1] Generative Adversarial Networks.
[2] Conditional Generative Adversarial Nets.
[3] InfoGAN: Interpretable Representation Learning by Information MaximizingGenerative Adversarial Nets.
[4] Wasserstein GAN.
[5] Image-to-Image Translation with Conditional Adversarial Networks.
[6]https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/gan.
[7] https://github.com/tensorflow/models/tree/master/research/gan.


如果你希望看到更多类似的优质内容,记得点个赞再走!
┏(^0^)┛明天见!



