KDD 18 & AAAI 19 | 异构信息网络表示学习论文解读

作者丨崔克楠
学校丨上海交通大学博士生
研究方向丨异构信息网络、推荐系统
本文要介绍的两篇论文在 metric learning 和 translation embedding 的角度对异构信息网络中的节点进行学习,都受到了 knowledge graph 的模型如 TransE,TransR 的影响,所以在这里一起来进行对比说明。
异构信息网络专题论文集:
https://github.com/ConanCui/Research-Line
KDD 2018


待解决的问题
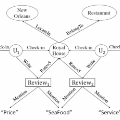
目前大多数异构信息网络(HIN)对于点之间相似度的衡量方式,都是在低维空间使两个点的 embedding 的内积 (dot product)尽可能的大。这种建模方式仅能考虑到一阶关系(first-order proximity),这点在 node2vec 中也提到;
相比于同构信息网络,异构信息网络中包含多种 relationship,每种 relationship 有着不同的语义信息。
同时 relationship 的种类分布非常不均匀。
解决的方法
1. 使用 metric learning(具体可参见论文 Collaborative Metric Learning [1],它具有 triangle inequality 特性)来同时捕捉一阶关系和二阶关系(second-order proximity)。
2. 在 object space 学习 node 的 embedding,在 relation space 学习 relation 的 embedding。计算时,先将 node embedding 从 object space 转移到 relation space,然后计算 proximity。
3. 提出 loss-aware 自适应采样方法来进行模型优化。
模型的动机
相比于同构网络的 embedding,异构网络中节点之间的 proximity 不仅仅指两个节点在 embedding space 的距离,同时也会受到 relation 中所包含关系的影响。
dot product 仅能够保证一阶关系,而 metric learning 能够更好同时保存一阶关系和二阶关系。
由于 metric learning 直接应用会存在 ill-posed algebraic 的问题,所以不能直接应用。同时我们还要考虑到异构网络中存在不同的 relation,这点也需要建模。
以往异构网络中,对于不同种类的 relation 比例差距悬殊的问题,有人提出对每一种 relation 进行等比例采样, 但这会造成有的 relation 被欠采样,有的过采样,并且不同 relation 的难度不同,需要采样的数量也不同。
模型
学习 embedding 的 loss 如下:
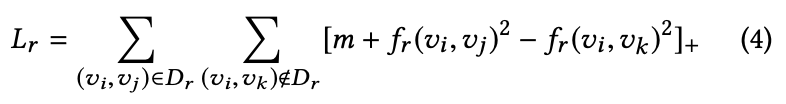
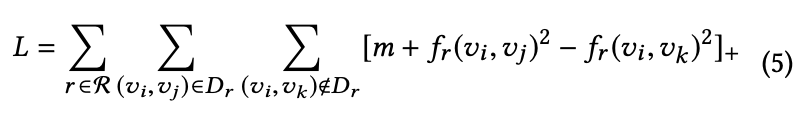
其中:
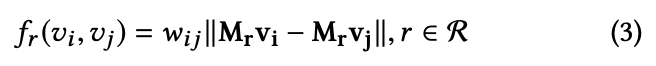
可以看出,上述 loss 的目的是让不同的点在某一种 relation space 中尽可能地接近,同时是的学到的 embedding 保留一阶和二阶特性。需要学习的参数为 node embedding v, 和从 object space 映射到不同 relation space 的映射矩阵Mr。
上式中,所有负样本都加入训练集,会导致复杂度急剧上升,在这里采用双向负采样(Bidirectional Negative Sampling Strategy),所以 loss 修改如下:
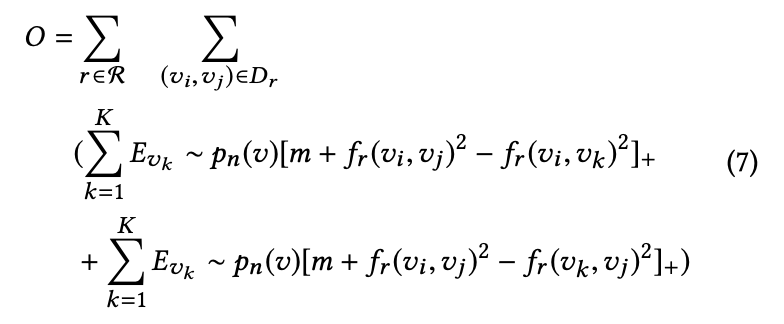
对于每个 epoch,我们会把每个种类的网络的 loss 记录下来,如下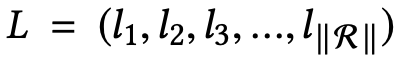
最终整体的算法流程为:

实验
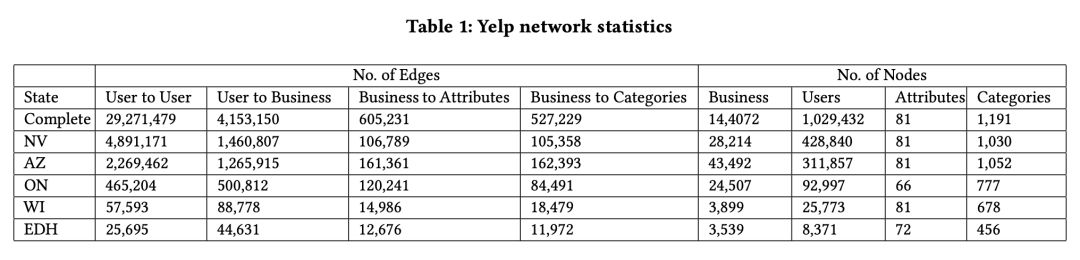
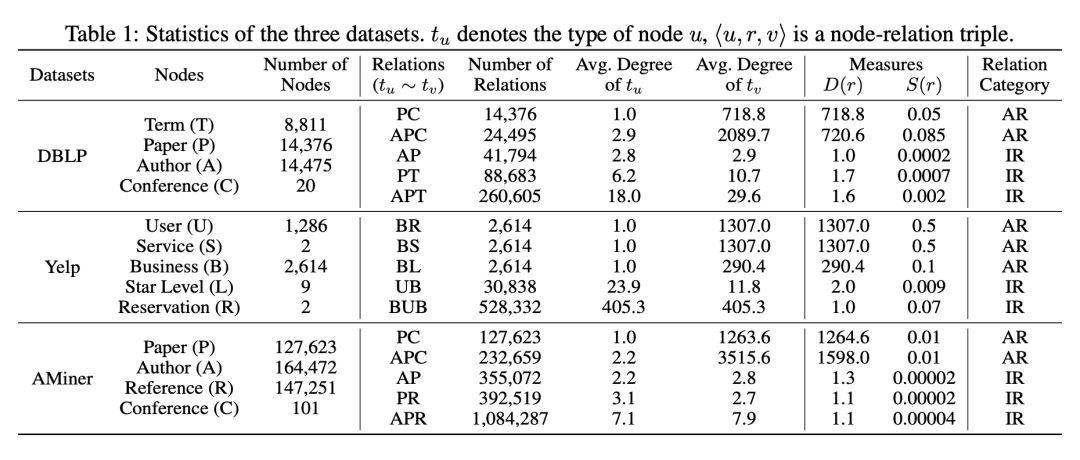
实验采用了来自五个州的 Yelp 数据集,点的种类包括用户(User),物品(Business),物品属性(Attribute),物品种类(Category),如 Table 1 所示。
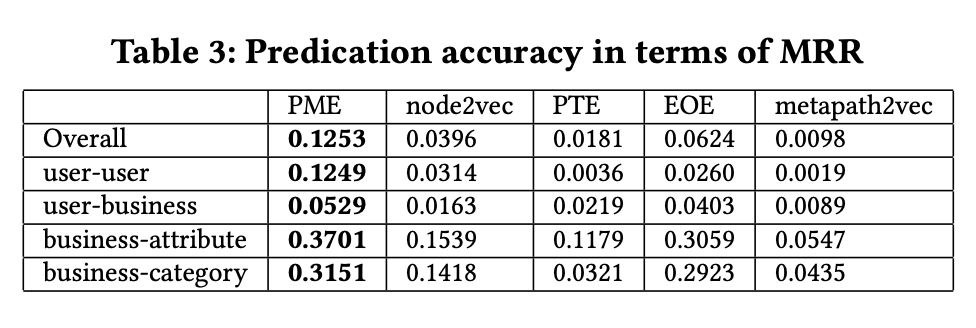
在 AZ 州的数据集上计算 Hits@K 和 MRR,结果如 Figure 2 和 Tabel 3 所示。
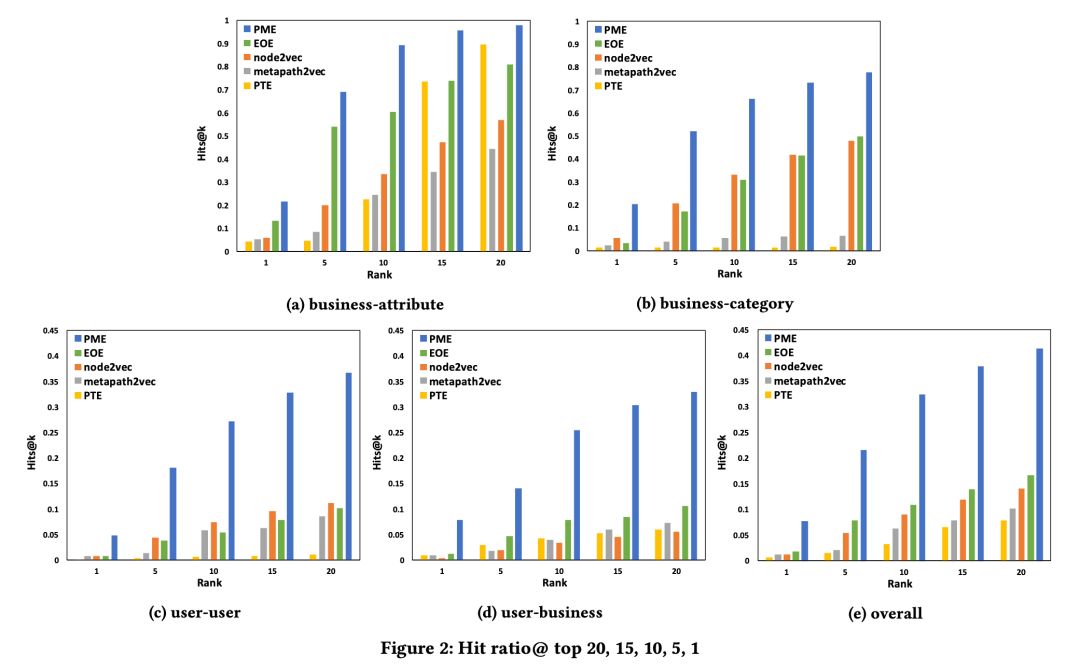
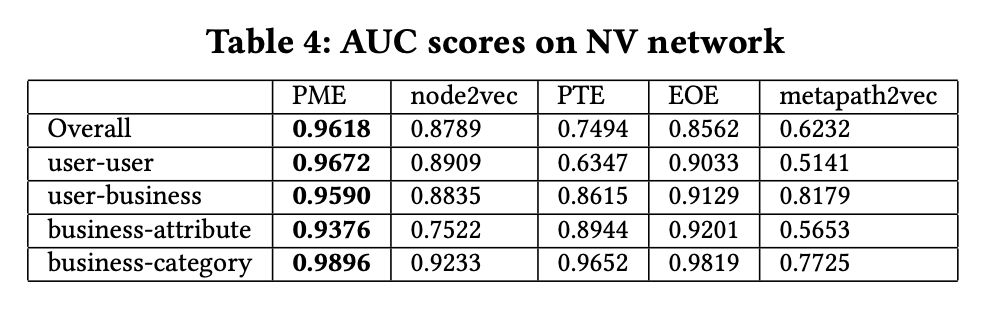
在 NV 州数据集做 link prediction 任务,具体为判断当前便是否存在在测试集当中,具体指标使用 AUC,结果如 Tabel 4 所示。
总结
该篇文章整体的贡献点为:
1. 使用 metric learning 来解决 HIN 中的二阶关系,并借用 TransR 中的映射矩阵来解决 metric learning 存在的 ill-posed algebraic 问题,对于多种 relation 建立多个 relation space。
2. 提出 loss-aware adaptive 采样方法,解决了 HIN 中存在的 relation skewed 的问题。
但是可能存在的问题是,该篇文章仅仅考虑基础的 relation,另外在 HIN 中还有常见的 composite relations 是使用 meta-paths 来表示的。
比如在 DBLP 这样的参考文献数据集上,存在 (A, author,P,paper,C,conference) 这些节点。而像 APA (co-author relation),以及 APC (authors write pa- pers published in conferences) 这样包含着丰富的信息的 composite relations,在这篇文章中没有考虑到。
AAAI 2019


待解决的问题
1. 异构网络中存在着很多的 relations,不同的 relations 有着不同的特性,如 AP 表现的是 peer-to-peer,而 PC 代表的是 one-centered-by-another 关系。如何区分不同的 relations?
2. 针对不同的 relations,目前的模型都采用相同的方法来对他们进行处理。如何区分建模?
3. 如果建立多个模型,如何协调优化?
解决的方法
1. 根据结构特性定义了两种 relations,Affiliation Relations (ARs) 代表 one-centered-by-another 的结构,而 Interaction Relations (IRs) 代表 peer-to-peer的关系。
2. 对于 AR,这些点应当有共同的特性,所以直接用节点的欧几里得距离作为 proximity。对于 IR,将这种关系定义为节点之间的转移(translation)。前者借鉴了 collaborative metric learning,后者借鉴了模型 TransE。
3. 因为两个模型在数学形式上相似,所以可以一起优化。
数据分析
不同于上篇文章,这篇文章从数据分析入手,并给出两种 structural relation 的定义。三个数据集整合如 Table 1 所示。
对于一个 relation 的三元组 <u,r,v>,其中作者定义了一个指标如下:
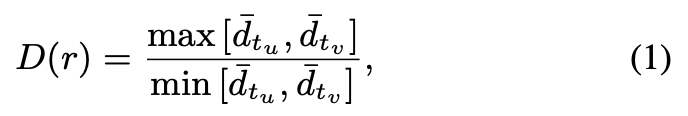
该指标由 u 和 v 种类的节点的平均度(degrees)来决定。如果 D(r) 越大,代表由 r 连接的两类节点的不平衡性越大,越倾向于 AR 类型,否则倾向 IR 类型。同时定义了另外一个稀疏度指标如下:
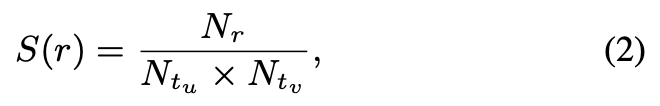
其中代表该种类 relation 的数量,
代表头节点所在种类节点的数量,如果数据越稠密,则越倾向于 AR,因为是 one-centered-by-another,而 IR 关系的相对来说应该较为稀疏。
模型
对于 AR 类型,采用类似于上篇文章 PME 中的 metric learning 角度建模,原因除了 metric learning 能够保留 second- order proximities 外,metric learning 和 AR 的定义契合,及被该关系连接的节点之间欧式距离要尽量的小。
而对于 IR 类型为何用 translation 来进行建模,没有更好的说明,只是在模型的数学形式上和 metric learning 较为接近,容易结合。
则对于 AR 类型的 loss 为:
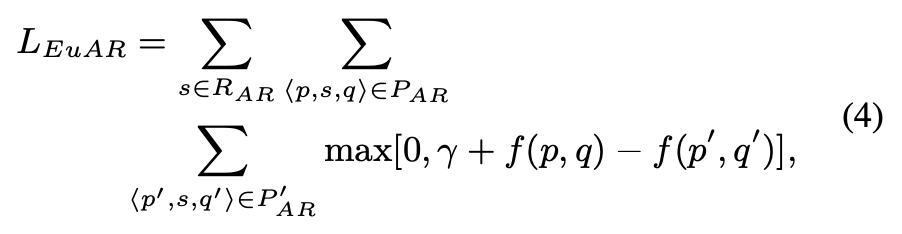
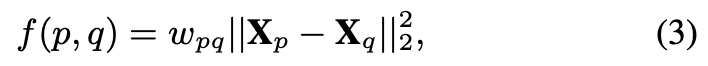
而对于 IR 类型的 loss 为:
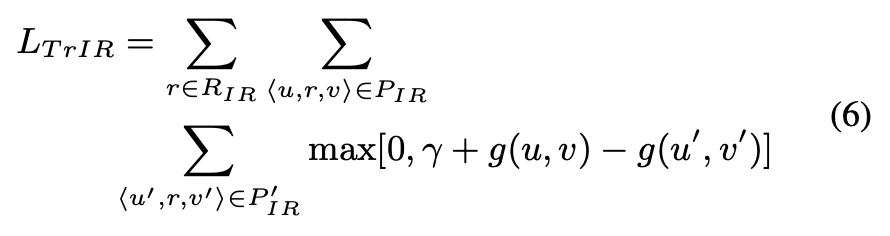
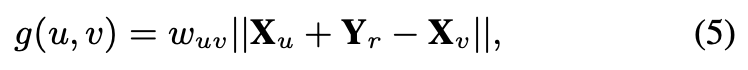
对于整个模型来说,就是简单的把两部分的 loss 相加,没有上一篇 PME 中考虑的更合理。
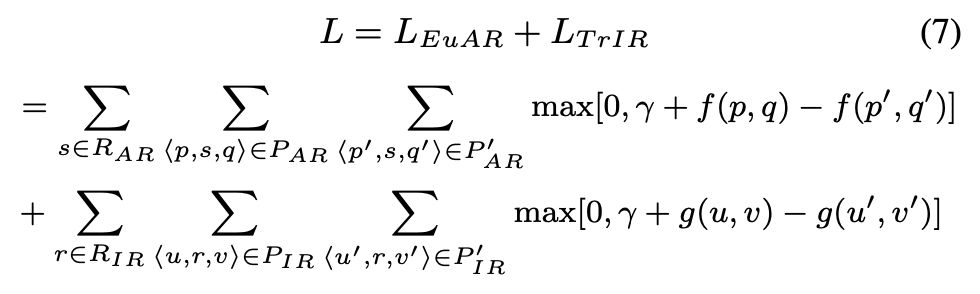
正负采样的方法也没有上一篇当中有过多的技巧,relation 的正采样就直接按照数据集中的比例来进行采样,不考虑 relation 种类是 skewed 的情况。而对于负采样,和 TransE 和上篇文章中 PME 相同的方法,即双向负采样。
实验
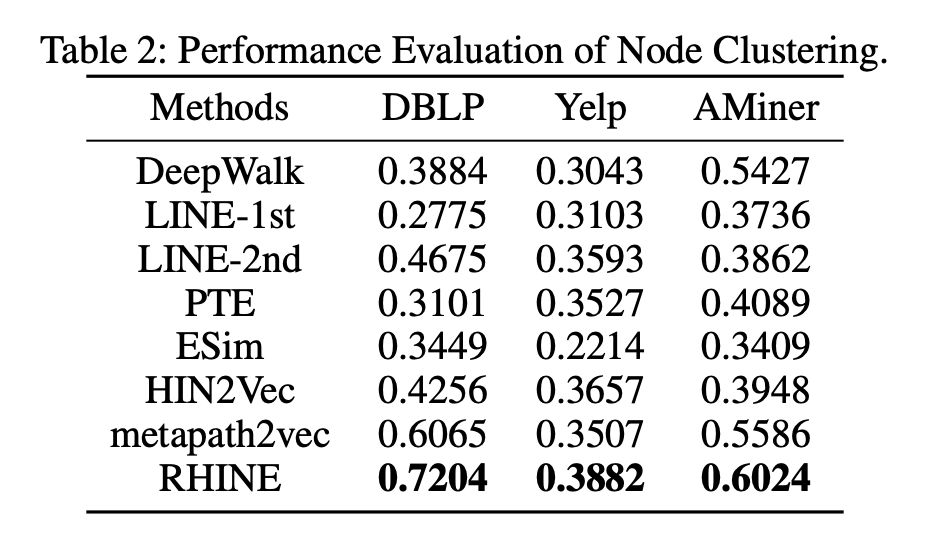
实验采用 Table 1 中的数据集,首先看在聚类任务上效果的好坏,具体指标采用 NMI,结果在表格 2 中所示。
接着看了模型在 Link prediction 上的效果好坏,具体为判断当前边是否在测试集中。具体指标采用 AUC 和 F1,结果见 Table 3。
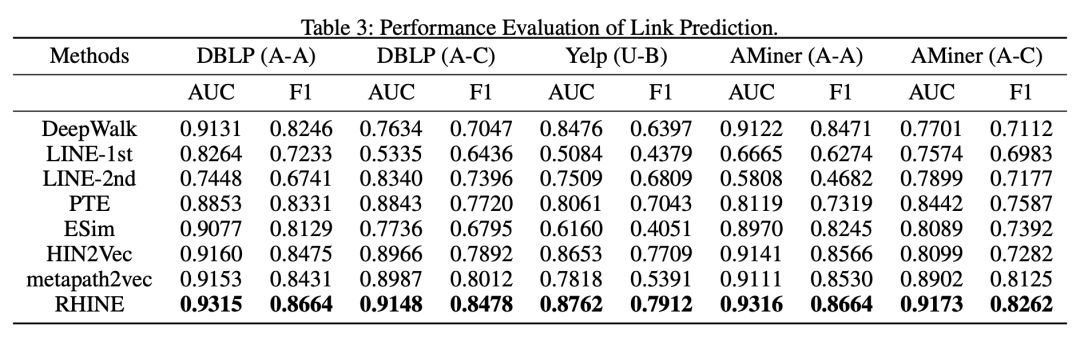
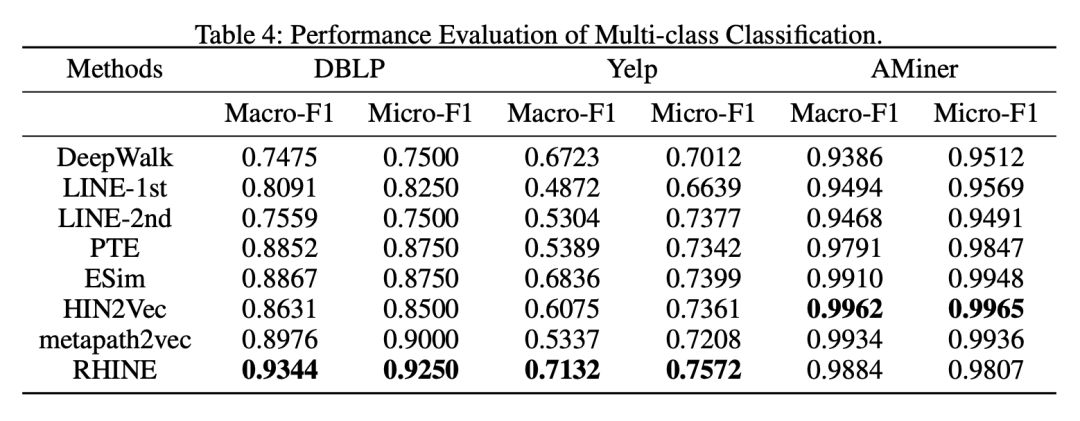
另外看了模型在 multi-class classification 任务上的表现,看学到的节点是否保留有节点种类信息,具体为对已经学习到的节点 embedding,训练一个分类器,结果如 Table 4 所示。
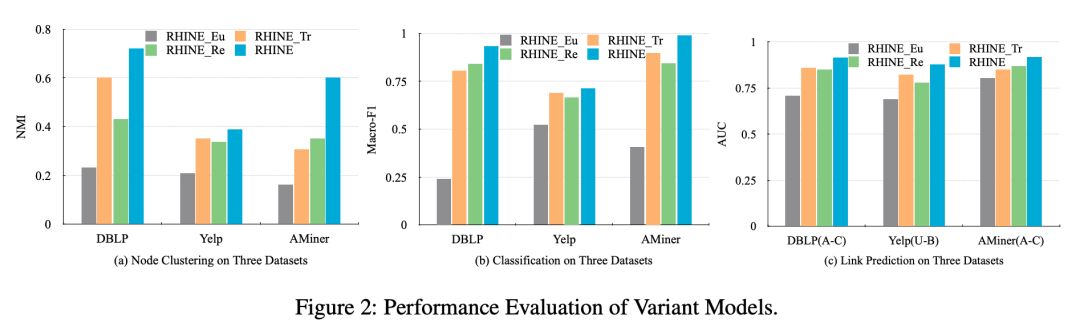
另外,为了探讨区分两种 relation,并利用 metric learning 和 translation 进行建模是否有效,作者进行了 ablation study。提出如下三种 variants:

其实验结果如 Figure 2 所示:
总结
总的来说,作者从分析数据入手,对于 HIN 中具有不同 structural 的 relation 进行了区分,并且分别采用不同的方法对不同 structural 的 relation 进行建模,在一定程度上给出了这两种方法的建模 motivation。
相比于 PME,作者对于两部分的 relation 的 loss 结合较为粗糙,不过作者的重点也不在于此,没有什么问题。
参考文献
[1]. Hsieh C K, Yang L, Cui Y, et al. Collaborative metric learning[C]//Proceedings of the 26th international conference on world wide web. International World Wide Web Conferences Steering Committee, 2017: 193-201.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐