加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:Quoc V. Le 等
来源:机器之心
参与:思源、一鸣
ImageNet 上的图像分类模型似乎已经成熟,要达到新的 SOTA 已经非常难。
近日,Quoc Le 等提出了一个新的方法,在这一数据集上再次提高了 SOTA 性能一个点。
而且这一方法让模型在鲁棒性上也有很大的提升。
论文地址:https://arxiv.org/abs/1911.04252
谷歌大脑负责人 Jeff Dean 和该论文的作者之一 Quoc Le 今天都在 Twitter 上介绍了这项研究工作,新方法能利用更多的未标注图像数据,并提升最终效果。
![]()
在本文中,研究者首先在标注的 ImageNet 图像上训练了一个 EfficientNet 模型,然后用这个模型作为老师在 3 亿无标签图像上生成伪标签。
然后研究者训练了一个更大的 EfficientNet 作为学生模型,使用的数据则是正确标注图像和伪标注图像的混合数据。
这一过程不断迭代,每个新的学生模型作为下一轮的老师模型,在生成伪标签的过程中,教师模型不会被噪声干扰,所以生成的伪标注会尽可能逼真。
但是在学生模型训练的过程中,研究者对数据加入了噪声,使用了诸如数据增强、dropout、随机深度等方法,使得学生模型在从伪标签训练的过程中更加艰难。
这一自训练模型,能够在 ImageNet 上达到 87.4% 的 top-1 精确度,这一结果比当前的 SOTA 模型表现提高了一个点。
除此之外,该模型在 ImageNet 鲁棒性测试集上有更好的效果,它相比之前的 SOTA 模型能应对更多特殊情况。
ImageNet 需要更多的大数据
ImageNet 已经是大数据集了,大量标注图像已经足够我们学习一个不错的模型。
但是它还需要更多的未标注图像,即使有一些图像根本不在要识别的类别之内也没关系。
当模型见过广大的未标注数据,它才能做更好的 ImageNet 分类。
在本文中,研究者利用未标注图像来提升当前最优 ImageNet 的精确度,并表明精确度增益对鲁棒性具有非常大的影响。
基于此,研究者使用了包含未标注图像的更大语料库,其中一些图像并不属于 ImageNet 的任何类别。
研究者在训练模型的过程中使用了自训练框架,分为以下三步:
在标注图像上训练一个教师模型;
利用该教师模型在未标注图像上生成伪标签(pseudo label);
在标注和伪标注混合图像上训练一个学生模型。最后,通过将学生模型当做教师模型,研究者对算法进行了几次迭代,以生成新的伪标签和训练新的学生模型。
研究者表示,实验说明,一项重要的方法是,学生模型在训练中应当被噪声干扰,而教师模型在生成伪标签的时候不需要。这样,伪标签能够尽可能逼真,而学生模型则在训练中更加困难。
为了干扰学生模型,研究者使用了 dropout、数据增强和随机深度几种方法。为了在 ImageNet 上实现稳健的结果,学生模型也需要变得很大,特别是要比普通的视觉模型大很多,这样它才能处理大量的无标注数据。
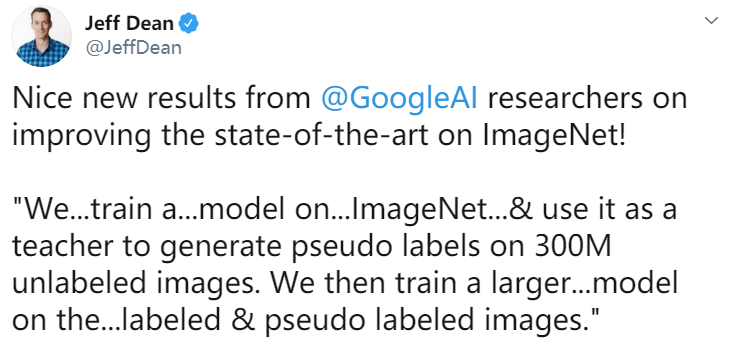
使用自训练的带噪声学生模型,加上 3 亿的无标注图像,研究者将 EfficientNet 的 ImageNet top-1 精确度提升到了新 SOTA。
![]()
表 1:
和之前的 SOTA 模型指标的对比结果。
带有 Noisy Student 的自训练到底是什么
下图算法 1 给出了利用 Noisy Student 方法展开自训练的总览图,算法的输入包括标注和未标注图像。
![]()
研究者首先利用标准交叉熵损失和标注图像来训练老师模型。然后,他们使用该老师模型在未标注图像上生成伪标签。这些伪标签既可以是柔性的(连续分布),也可以是硬性的(onehot 分布)。接着,研究者训练学生模型,该模型最小化标注和未标注图像上的联合交叉熵损失。最后,通过将学生和老师模型的位置互换,他们对训练过程进行了几次迭代,以生成新的伪标签和训练新的学生模型。
该算法基本上是自训练的,这是一种半监督的方法。
在本文中,研究者主要的改变是给学生模型增加了更多的噪声源,这样可以在移除教师模型中的噪声后,让它生成的伪标签具有更好的效果。
当学生模型被刻意干扰后,它实际上会被训练成一个稳定的教师模型。
当这个模型在生成伪标签的时候,研究者不会去用噪声干扰它。
此外,教师模型与学生模型的架构可以相同也可以不同,但如果要带噪声的学生模型更好地学习,那么学生模型需要足够大以拟合更多的数据。
实验结果
在这一部分中,研究者描述了实验的各种细节与实现的结果。他们展示了新方法在 ImageNet 上的效果,并对比了此前效果最佳的模型。此外,研究者还重点展示了新方法在鲁棒性数据集上的卓越表现,即在 ImageNet-A、C 和 P 测试集,以及在对抗样本上的鲁棒性。
如下表 2 所示,以 EfficientNet-L2 为主要架构的 Noisy Student 实现了 87.4% 的 Top-1 准确率,它显著超越了之前采用 EfficientNet 的准确率。
其中 2.4% 的性能增益主要有两个来源:
更大的模型(+0.5%)和 Noisy Student(+1.9%)。
也就是说,Noisy Student 对准确率的贡献要大于架构的加深。
![]()
表 2:
Noisy Student 与之前 SOTA 模型在 ImageNet 上的 Top-1 与 Top-5 准确率,带有 Noisy Student 的 EfficientNet 能在准确率与模型大小上取得更好的权衡。
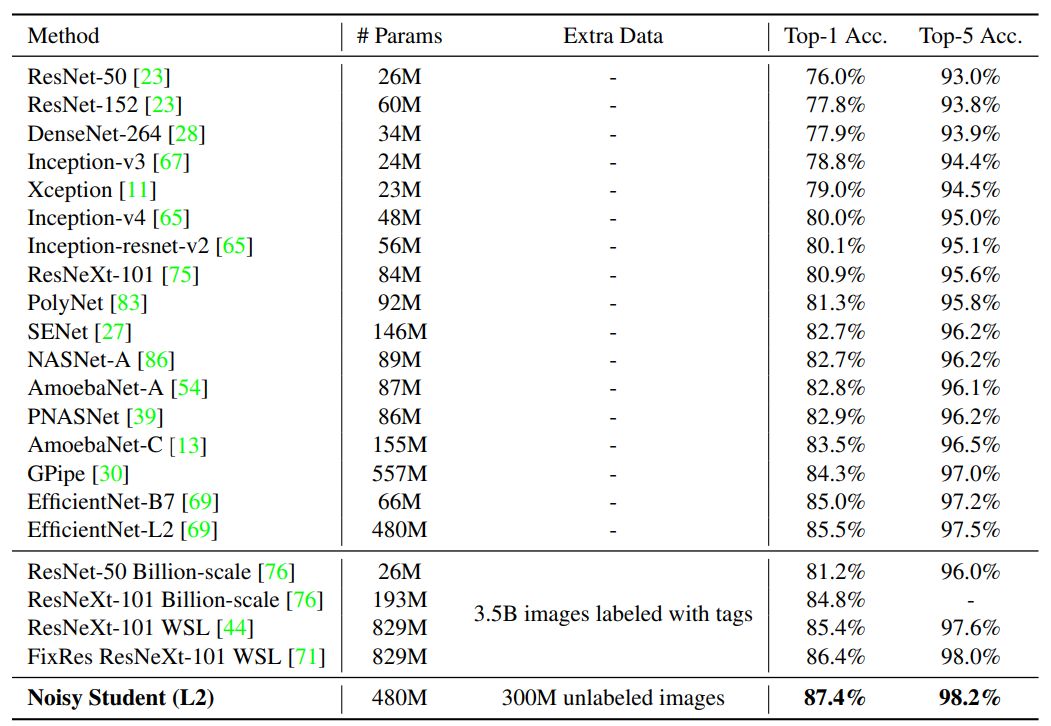
如下图 1 所示,Noisy Student 对于不同的模型大小都能带来 0.8% 左右的性能提升。
图 1:
Noisy Student 使得 EfficientNet 所有大小的模型都出现了显著的性能提升。
研究者对老师和学生模型使用了相同的架构,并且没有执行迭代训练。
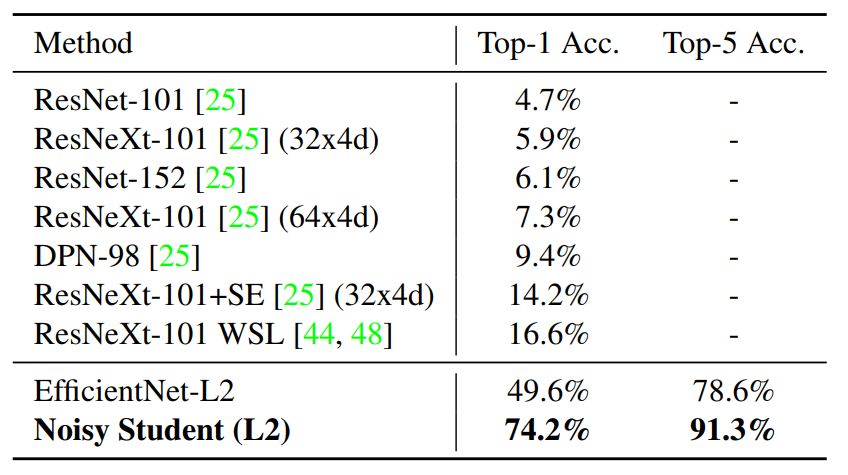
研究者将实现了 87.4% top-1 精确度的模型放到三个测试集中进行评估。
这三个测试集分别是 ImageNet-A、 ImageNet-C 和 ImageNet-P。
这些测试集包括了很多图像中常见的损坏和干扰,如模糊、雾化、旋转和拉伸。
ImageNet-A 测试集会让之前的 SOTA 模型精确度明显下降。
这些测试集被认为是「鲁棒性」的基准测试,因为它们要么非常难,如 ImageNet-A,要么和训练集非常不同,如 ImageNet-C 和 P。
![]()
![]()
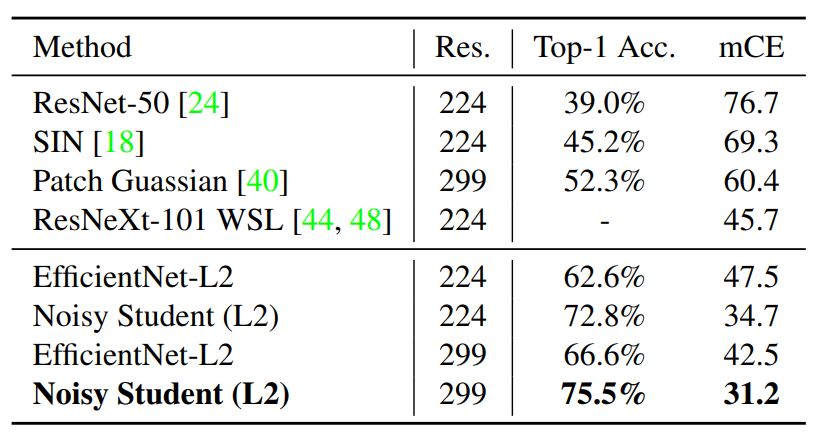
表 4:
ImageNet-C 的鲁棒性结果。
mCE 是不同侵蚀情况下的平均错误率,以 AlexNet 错误率为基准(数值越低越好)。
![]()
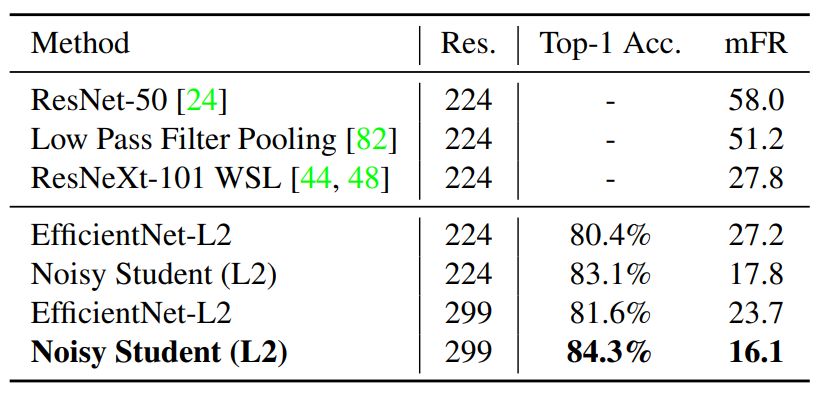
表 5:
在 ImageNet-P 上的鲁棒性结果,其中图片是通过一系列干扰生成的 mFR 使用 AlexNet 为基准,测量模型在扰动下翻转预测的概率(数值越低越好)。
为了直观理解三个鲁棒性基准的大幅度提升,下图中展示了一些图片,其中基准模型识别错误,而 Noisy Student 模型的预测则正确。
图 2:
从模型稳健性基准 ImageNet-A、C 和 P 中挑选的图片。
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()