21秒看尽ImageNet屠榜模型,60+模型架构同台献艺
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
转自机器之心,已获得授权,不得二次转载
机器之心编译 参与:一鸣、思
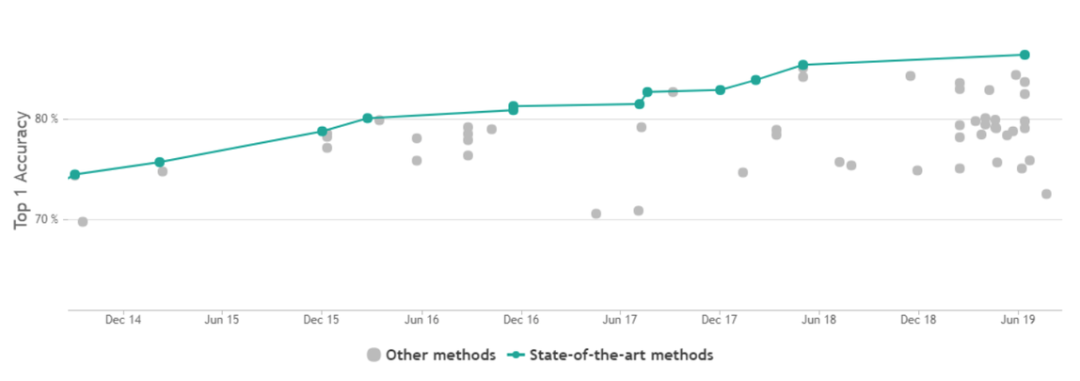
60+模型架构,历年十几个 SOTA 模型,这 21 秒带你纵览图像识别的演进历史。
AlexNet
提出时间:2012/9
Top-1 准确率:62.5%
参数量:60M
-
论文地址:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
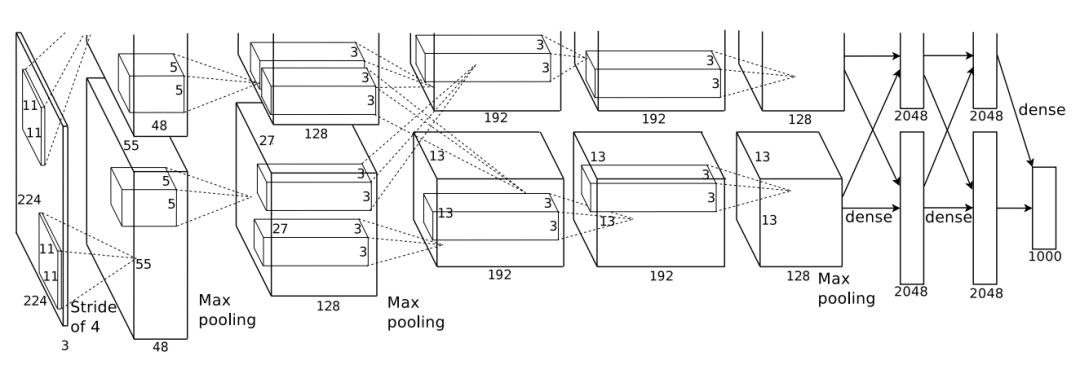
AlexNet 的架构示意图。
ZFNet
提出时间:2013/11
Top-1 准确率:64%
-
论文地址:https://arxiv.org/pdf/1311.2901v3.pdf
Inception V1
提出时间:2014/9
Top-1 准确率:69.8%
参数量:5M
论文地址:https://arxiv.org/pdf/1409.4842v1.pdf
VGG-19
提出时间:2014/9
Top-1 准确率:74%
参数量:144M
论文地址:https://arxiv.org/pdf/1409.1556v6.pdf
PReLU-Net
提出时间:2015/2
Top-1 准确率:75.73%
论文地址:https://arxiv.org/pdf/1502.01852v1.pdf
Inception V3
提出时间:2015/12
Top-1 准确率:78.8%
参数量:23.8M
论文地址:https://arxiv.org/pdf/1512.00567v3.pdf
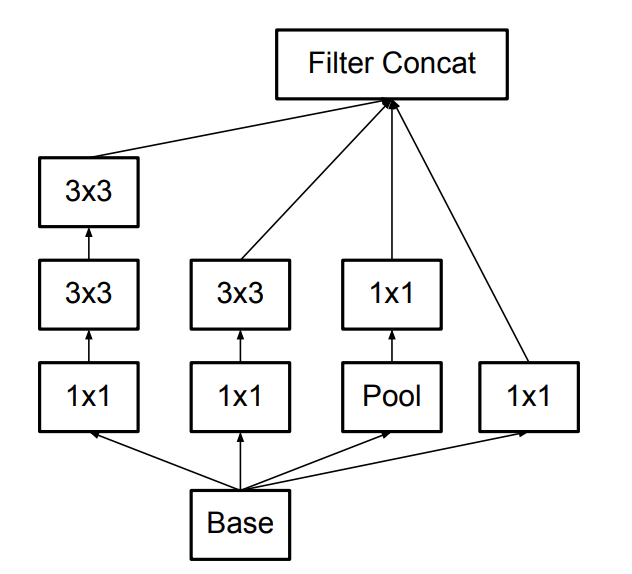
Inception V3。
ResNet 152
提出时间:2015/12
Top-1 准确率:78.6%
-
论文地址:https://arxiv.org/pdf/1512.03385v1.pdf
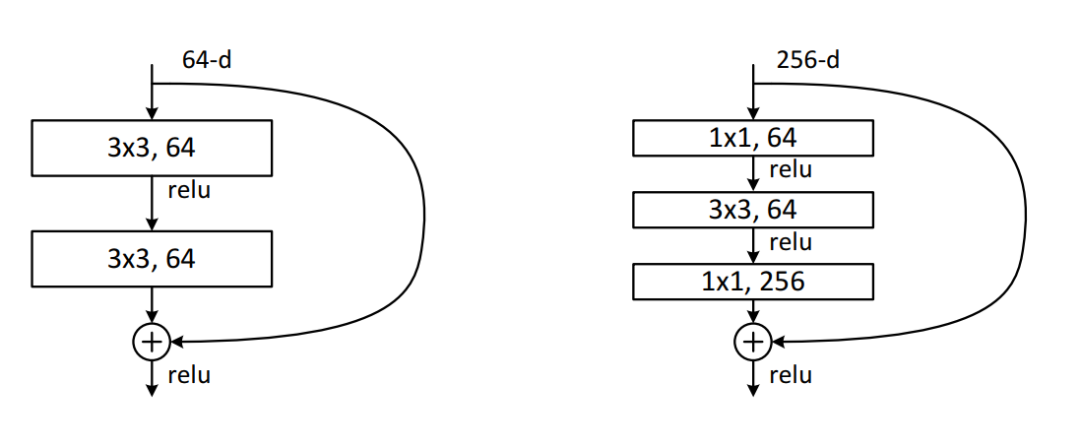
ResNet 的基本模块。Inception ResNet V2
提出时间:2016/2
Top-1 准确率:80.1%
论文地址:https://arxiv.org/pdf/1602.07261v2.pdf
DenseNet-264
提出时间:2016/8
Top-1 准确率:79.2%
-
论文地址:https://arxiv.org/pdf/1608.06993v5.pdf
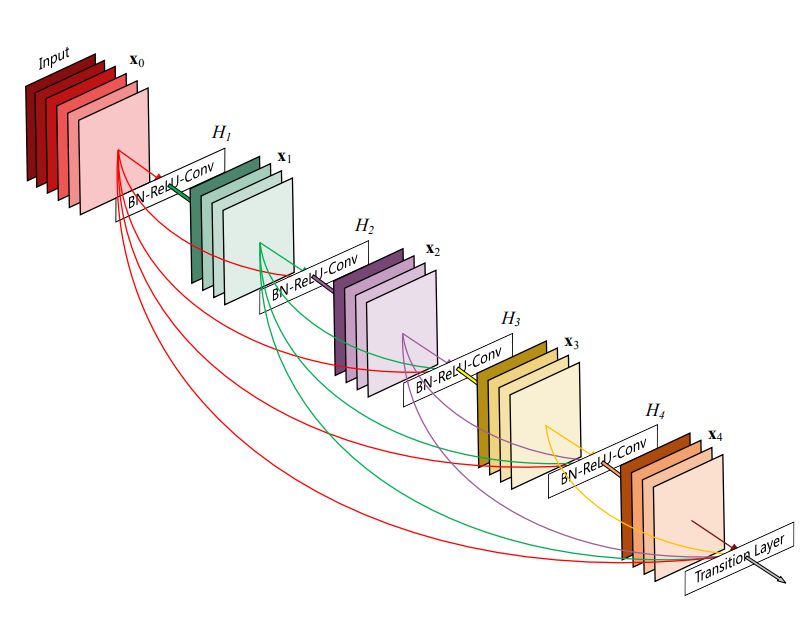
增长率为 4 的 DenseNet 架构。
ResNeXt-101 64×4
提出时间:2016/11
Top-1 准确率:80.9%
参数量:83.6M
论文地址:https://arxiv.org/pdf/1611.05431v2.pdf
PolyNet
提出时间:2016/11
Top-1 准确率:81.3%
参数量:92M
论文地址 https://arxiv.org/pdf/1611.05725v2.pdf
DPN-131
提出时间:2017/7
Top-1 准确率:81.5%
参数量:80M
论文地址:https://arxiv.org/pdf/1707.01629v2.pdf
NASNET-A(6)
提出时间:2017/7
Top-1 准确率:82.7%
参数量:89M
论文地址:https://arxiv.org/pdf/1707.07012v4.pdf
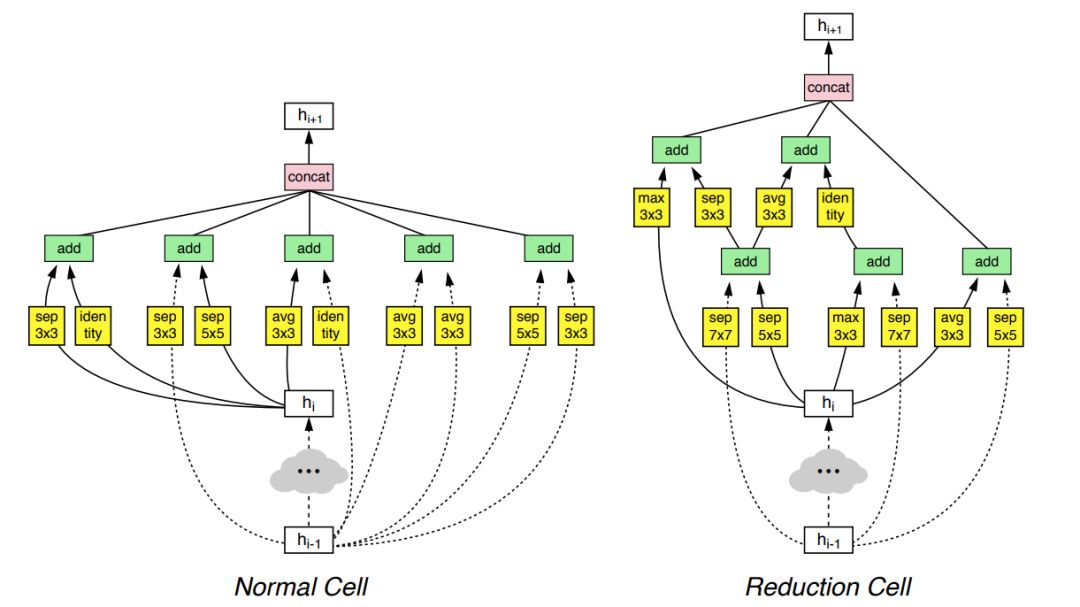
利用神经架构搜索(NAS)方法获得的模型(右图),相比左边的模型减少了参数量,效果得到了提升。
-
提出时间:2017/12 -
Top-1 准确率:82.9% -
参数量:86.1M 论文地址:https://arxiv.org/pdf/1712.00559v3.pdf MobileNetV2 -
提出时间:2018/1 -
Top-1 准确率:74.7% -
参数量:6.9M 论文地址:https://arxiv.org/pdf/1801.04381v4.pdf
AmoebaNet-A -
提出时间:2018/2 -
Top-1 准确率:83.9% -
参数量:469M -
论文地址:https://arxiv.org/pdf/1802.01548v7.pdf
ResNeXt-101 32×48d -
提出时间:2018/5 -
Top-1 准确率:85.4% -
参数量:829M -
论文地址:https://arxiv.org/pdf/1805.00932v1.pdf
ShuffleNet V2 2× -
提出时间:2018/7 -
Top-1 准确率:75.4% -
参数量:7.4M -
论文地址:https://arxiv.org/pdf/1807.11164v1.pdf
EfficientNet -
提出时间:2019/5 -
Top-1 准确率:84.4% -
参数量:66M -
论文地址:https://arxiv.org/pdf/1905.11946v2.pdf
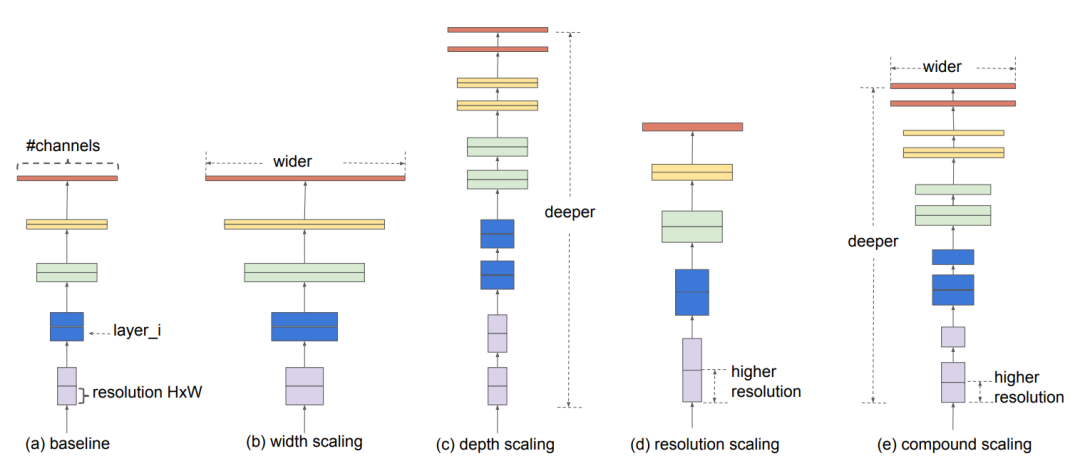
EfficientNet 论文中的架构对比。a)基线模型;b)- d)分别为对图像宽度、深度和分辨率的扫描架构;e)论文提出的可以将所有扫描架构融合在一起的网络结构。
FixResNeXt-101 32×48d
提出时间:2019/6
Top-1 准确率:86.4%
参数量:829M
-
论文地址:https://arxiv.org/pdf/1906.06423v2.pdf
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



