

执行摘要
收购分析和政策办公室是国防部负责收购和维持的副部长办公室(OUSD(A&S))的一部分,该办公室委托IDA评估使用机器精益分析主要国防收购项目(MDAPs)合同的可行性。分析的目的是从合同中提取数据,并预测项目绩效。该研究分为三个阶段:爬行、步行和跑步。
爬行
爬行阶段包括建立一个数据集。在分析的这一阶段,收集和处理合同。所选择的合同在1997年12月至2018年12月期间被列入选定的采购报告(SARs),并且来自截至2019年11月不再报告的MDAPs。对这一时期的合同进行检查,确保了每个项目都有90%以上的完整性。此外,数据集被限制在这一时期,因此计划的绩效结果是已知的,这在使用机器学习算法进行预测时是必要的。我们收集了24,364份PDF格式的合同文件,涉及149个合同号和34个MDAPs。(最后,我们使用国防分析研究所的文本分析(IDATA)功能,将收集到的文件变成机器可读的数据集。
步行
在步行阶段,通过在我们的数据上训练机器学习算法来评估合同数据,以回答相对简单的问题。这项活动确保了数据集具有合理的质量,机器学习算法运行正常,并能产生合理的答案。在这个阶段,每个程序都产生了词云。下图显示了两个程序的词云,分别是CH-47F和ATACMS-APAM。

ATACMS-APAM计划的词云
字云显示了每个计划的合同中各种词汇的频率,去掉了 "和"、"的"等常见词汇。这些图形对于揭示每个项目的文件中最频繁使用的词语很有帮助,并有助于确保我们收集到合理的数据。
接下来,我们在这些数据的训练集上训练了一个天真贝叶斯分类器,并要求它将每份合同按五个类别之一进行区分:(1)研究、开发、测试和评估(RDT&E);(2)RDT&E修改;(3)采购;(4)采购修改;以及(5)采购运营和维护(O&M)修改。这些类别很容易由人类确定,预计机器学习也会产生同样的结果。下表显示了合同类别的分布和每种合同类型的数量。

该算法对80%的文件进行了训练,然后用来预测其余20%的文件的类别。下面的混淆矩阵显示了该算法预测合同类型的效果。
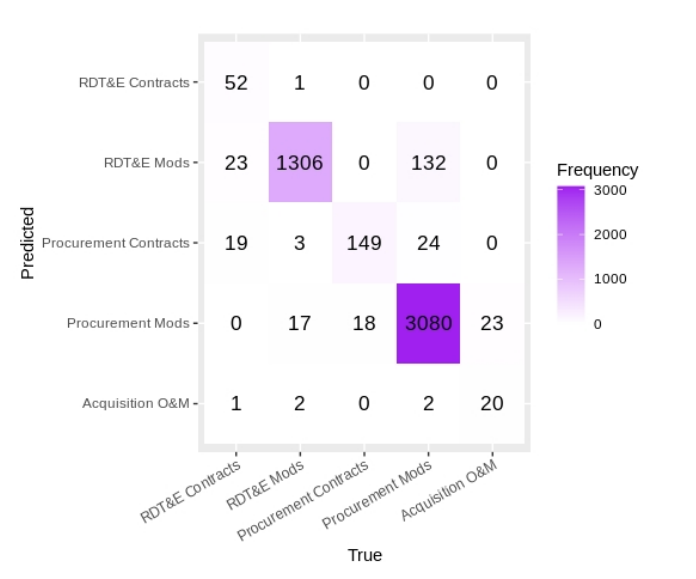
文件类型识别的混淆矩阵
对角线元素,也就是最大的数字,显示了算法在测试样本中正确识别合同类型的地方。总的来说,该算法对4872个文件中的4607个进行了正确分类,导致总体准确率为94.6%。准确率取决于样本大小。例如,该算法预测测试数据中的52个文件是RDT&E合同,而95个文件是RDT&E合同,导致近55%的准确率,而3238个采购模式中的3080个,或刚刚超过95%,被正确分类。
后面描述的其他模型表明,合同被成功地转化为数据。因此,这表明有可能将我们的算法应用于这个数据集,提出相对简单的问题并获得合乎逻辑的答案。
跑步
在跑步阶段,我们提出了更难的预测问题,以测试机器学习算法使用合同数据集来预测项目绩效的能力。我们使用Q-比率作为数量增长的衡量标准,使用数量调整后的项目采购单位成本作为成本增长的衡量标准,以及项目结束日期。使用70%的项目来训练支持向量机(SVM)模型,并对其余30%的项目的绩效指标进行预测。支持向量机无法比随机猜测更好地预测绩效。我们还研究了使用聚类来识别类似程序。尽管我们可以识别相似的程序,但很难确定这些程序为什么相似,这表明在这个领域还需要更多的研究。
结论
我们发现,文本分析和机器学习算法很适合从合同中提取信息,并将这些信息转化为结构化的数据集。尽管我们的分析使用了几个不同的指标,表明提取的数据对描述性的目的是有用的,但我们无法确定机器学习算法是否能预测项目的表现。然而,这一结果并不意味着用合同数据集预测项目绩效是不可行的。它可能意味着,更完整(或不同)的合同集、其他绩效指标或替代算法将改善预测结果。此外,为了改善预测,可能有必要将合同数据与其他来源的数据相结合。

