在Python中使用SpaCy进行文本分类
【导读】在这篇文章中,我们将学习如何使用SpaCy进行文本分类, spaCy是Python中流行且易于使用的自然语言处理库。它提供了当前最佳的准确性和效率,并且有一个活跃的开源社区支持。大家感兴趣的话可以尝试使用一下。
作者 | Susan Li
编译 | 专知
参与 | Yingying, Hujun

Machine Learning for Text Classification Using SpaCy in Python
在Python中使用SpaCy进行文本分类
spaCy是Python中流行且易于使用的自然语言处理库。它提供了当前最佳的准确性和效率,并且有一个活跃的开源社区支持。但是,由于SpaCy是一个相对较新的NLP库,并没有像NLTK那样被广泛采用。当前SpaCy并没有足够的教程。
https://spacy.io/
在这篇文章中,我们将演示如何使用spaCy实现文本分类。
1.数据
在这里,我们使用在会议论文数据集。数据集可以在这里找到。
https://raw.githubusercontent.com/susanli2016/Machine-Learning-with-Python/master/research_paper.csv
2.探索
示例代码:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import base64
import string
import re
from collections import Counter
from nltk.corpus import stopwords
stopwords = stopwords.words('english')
df = pd.read_csv('research_paper.csv')
df.head()

没有缺失值。
df.isnull().sum()
Title 0
Conference 0
dtype: int64
将数据拆分为训练和测试集:
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.33, random_state=42)
print('Research title sample:', train['Title'].iloc[0])
print('Conference of this paper:', train['Conference'].iloc[0])
print('Training Data Shape:', train.shape)
print('Testing Data Shape:', test.shape)
Research title sample: Cooperating with Smartness: Using Heterogeneous
Smart Antennas in Ad-Hoc Networks.
Conference of this paper: INFOCOM
Training Data Shape: (1679, 2)
Testing Data Shape: (828, 2)
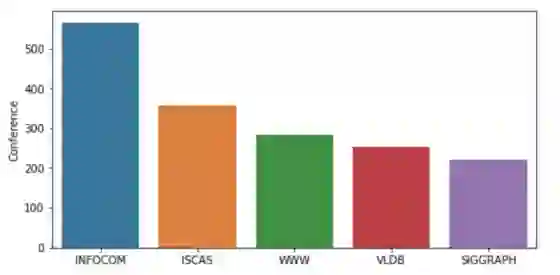
该数据集由2507个简短的研究论文标题组成,已被分为5类(通过会议)。 下图总结了不同会议的研究论文。
fig = plt.figure(figsize=(8,4))
sns.barplot(x = train['Conference'].unique(), y=train['Conference'].
value_counts())
plt.show()
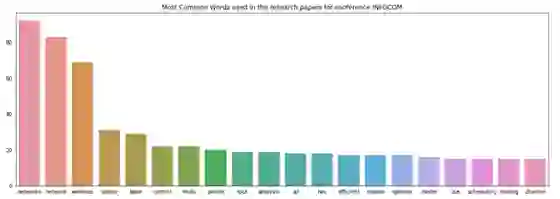
以下是在SpaCy中进行文本预处理的一种方法。 之后,我们试图找出提交给第一和第二类(会议)的论文中使用的热门词 - INFOCOM和ISCAS
import spacy
nlp = spacy.load('en_core_web_sm')
punctuations = string.punctuation
def cleanup_text(docs, logging=False):
texts = []
counter = 1
for doc in docs:
if counter % 1000 == 0 and logging:
print("Processed %d out of %d documents." % (counter,
len(docs)))
counter += 1
doc = nlp(doc, disable=['parser', 'ner'])
tokens = [tok.lemma_.lower().strip() for tok in doc if
tok.lemma_ != '-PRON-']
tokens = [tok for tok in tokens if tok not in stopwords
and tok not in punctuations]
tokens = ' '.join(tokens)
texts.append(tokens)
return pd.Series(texts)
INFO_text = [text for text in train[train['Conference'] == 'INFOCOM']
['Title']]
IS_text = [text for text in train[train['Conference'] == 'ISCAS']
['Title']]
INFO_clean = cleanup_text(INFO_text)
INFO_clean = ' '.join(INFO_clean).split()
IS_clean = cleanup_text(IS_text)
IS_clean = ' '.join(IS_clean).split()
INFO_counts = Counter(INFO_clean)
IS_counts = Counter(IS_clean)
INFO_common_words = [word[0] for word in INFO_counts.most_common(20)]
INFO_common_counts = [word[1] for word in INFO_counts.most_common(20)]
fig = plt.figure(figsize=(18,6))
sns.barplot(x=INFO_common_words, y=INFO_common_counts)
plt.title('Most Common Words used in the research papers for conference
INFOCOM')
plt.show()
IS_common_words = [word[0] for word in IS_counts.most_common(20)]
IS_common_counts = [word[1] for word in IS_counts.most_common(20)]
fig = plt.figure(figsize=(18,6))
sns.barplot(x=IS_common_words, y=IS_common_counts)
plt.title('Most Common Words used in the research papers for conference
ISCAS')
plt.show()
INFOCOM中的热门词汇是“networks”和“network”。 显然,INFOCOM是网络相关领域的会议。
ISCAS的主要词汇是“base”和“design”。 它表明ISCAS是数据库、系统设计相关主题的会议。
3.机器学习与spaCy
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.base import TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.stop_words import ENGLISH_STOP_WORDS
from sklearn.metrics import accuracy_score
from nltk.corpus import stopwords
import string
import re
import spacy
spacy.load('en')
from spacy.lang.en import English
parser = English()
以下是使用spaCy清洗文本的另一种方法:
STOPLIST = set(stopwords.words('english') + list(ENGLISH_STOP_WORDS))
SYMBOLS = " ".join(string.punctuation).split(" ") +
["-", "...", "”", "”"]
class CleanTextTransformer(TransformerMixin):
def transform(self, X, **transform_params):
return [cleanText(text) for text in X]
def fit(self, X, y=None, **fit_params):
return self
def get_params(self, deep=True):
return {}
def cleanText(text):
text = text.strip().replace("\n", " ").replace("\r", " ")
text = text.lower()
def tokenizeText(sample):
tokens = parser(sample)
lemmas = []
for tok in tokens:
lemmas.append(tok.lemma_.lower().strip() if tok.lemma_ !=
"-PRON-" else tok.lower_)
tokens = lemmas
tokens = [tok for tok in tokens if tok not in STOPLIST]
tokens = [tok for tok in tokens if tok not in SYMBOLS]
return tokens
定义一个函数来打印出最重要的特征:
def printNMostInformative(vectorizer, clf, N):
feature_names = vectorizer.get_feature_names()
coefs_with_fns = sorted(zip(clf.coef_[0], feature_names))
topClass1 = coefs_with_fns[:N]
topClass2 = coefs_with_fns[:-(N + 1):-1]
print("Class 1 best: ")
for feat in topClass1:
print(feat)
print("Class 2 best: ")
for feat in topClass2:
print(feat)
vectorizer = CountVectorizer(tokenizer=tokenizeText, ngram_range=(1,1))
clf = LinearSVC()
pipe = Pipeline([('cleanText', CleanTextTransformer()),
('vectorizer', vectorizer), ('clf', clf)])
# data
train1 = train['Title'].tolist()
labelsTrain1 = train['Conference'].tolist()
test1 = test['Title'].tolist()
labelsTest1 = test['Conference'].tolist()
# train
pipe.fit(train1, labelsTrain1)
# test
preds = pipe.predict(test1)
print("accuracy:", accuracy_score(labelsTest1, preds))
print("Top 10 features used to predict: ")
printNMostInformative(vectorizer, clf, 10)
pipe = Pipeline([('cleanText', CleanTextTransformer()),
('vectorizer', vectorizer)])
transform = pipe.fit_transform(train1, labelsTrain1)
vocab = vectorizer.get_feature_names()
for i in range(len(train1)):
s = ""
indexIntoVocab = transform.indices[transform.indptr[i]:
transform.indptr[i+1]]
numOccurences = transform.data[transform.indptr[i]:
transform.indptr[i+1]]
for idx, num in zip(indexIntoVocab, numOccurences):
s += str((vocab[idx], num))
accuracy: 0.7463768115942029
Top 10 features used to predict:
Class 1 best:
(-0.9286024231429632, ‘database’)
(-0.8479561292796286, ‘chip’)
(-0.7675978546440636, ‘wimax’)
(-0.6933516302055982, ‘object’)
(-0.6728543084136545, ‘functional’)
(-0.6625144315722268, ‘multihop’)
(-0.6410217867606485, ‘amplifier’)
(-0.6396374843938725, ‘chaotic’)
(-0.6175855765947755, ‘receiver’)
(-0.6016682542232492, ‘web’)
Class 2 best:
(1.1835964521070819, ‘speccast’)
(1.0752051052570133, ‘manets’)
(0.9490176624004726, ‘gossip’)
(0.8468395015456092, ‘node’)
(0.8433107444740003, ‘packet’)
(0.8370516260734557, ‘schedule’)
(0.8344139814680707, ‘multicast’)
(0.8332232077559836, ‘queue’)
(0.8255429594734555, ‘qos’)
(0.8182435133796081, ‘location’)
from sklearn import metrics
print(metrics.classification_report(labelsTest1, preds,
target_names=df['Conference'].unique()))
precision recall f1-score support
VLDB 0.75 0.77 0.76 159
ISCAS 0.90 0.84 0.87 299
SIGGRAPH 0.67 0.66 0.66 106
INFOCOM 0.62 0.69 0.65 139
WWW 0.62 0.62 0.62 125
avg / total 0.75 0.75 0.75 828
现在,我们就可以在SpaCy的帮助下完成了文本分类的任务。
原文链接:
https://towardsdatascience.com/machine-learning-for-text-classification-using-spacy-in-python-b276b4051a49
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知