作者
布鲁斯-纳吉(Bruce Nagy)是海军空战中心武器部的研究工程师。他的研究重点是先进的博弈论技术、人工智能和机器学习在战术决策辅助工具中的应用。纳吉先生获得了四个学位:一个是数学学位,两个是电子工程学位,还有一个是来自城堡大学和海军研究生院的生物学学位。他领导开发了先进的算法和衡量标准,为国防部解决了卫星通信方面的国防问题。在加州大学洛杉矶分校研究生工作期间,他与美国国立卫生研究院合作,研究了脑干与肌肉群在细胞水平上的通信模型。
摘要
在处理机器学习(ML)/人工智能(AI)部署的产品时,商业界和国防部(DoD)都面临着系统安全问题的挑战。国防部在部署可能存在伤害人群和财产的武器时,这个问题更为严重。商业制造商的动机是利润,而国防部的动机是防御准备。两者都在竞赛中,可能会因为过于关注终点线而遭受不利后果。需要建立正式的监督以确保安全的算法性能。本文提出了一种测量方法,对开发ML/AI算法时使用的训练数据的质量和数量进行仔细检查。测量训练数据的质量和数量可以增加对算法在 "现实 "操作环境中表现的可信度。将模式与测量相结合,可以确定:(1)如何策划数据以支持现实的环境部署;(2)在训练过程中,哪些属性优先,以确保数据的稳健构成;以及(3)属性优先如何反映在训练集的大小上。测量结果使人们对操作环境有了更多的了解,考虑到了数据缺失或稀疏时产生的问题,以及数据源如何在部署期间向算法提供输入。
1 引言
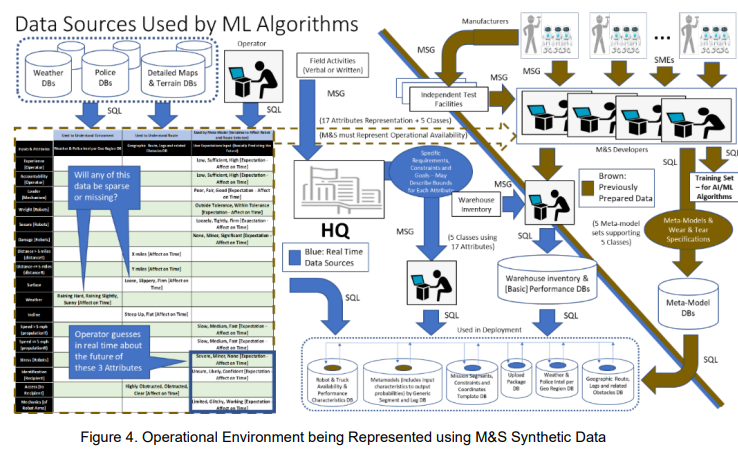
相对于传统的软件开发技术,机器学习(ML)/人工智能(AI)创建的功能需要使用训练数据集配置的模型。传统的代码被用来管理训练过程。训练集是由属性组合组成的,有时称为特征。当我们提到图像内的一个特征时,我们是在描述图像内容中包含的一段信息。在这种情况下,特征描述的是图像的某个区域,它具有某些属性,而不是另一个流行的定义,即特征是图像中的单个像素。属性的聚合可以包含在一个来源中,例如,拍摄面部照片的相机,或者各种传感器的输入,如雷达和通信链。在本文中,我们将根据属性的模式来区分属性是由一个还是多个来源产生的。正如将要描述的那样,了解模式的类型并创建具有适当质量和数量的实例/样本的训练数据集,以复现部署期间经历的变化、异常和噪音,是提高算法行为可信度的关键。
1.1 无告警
第一位被自动驾驶汽车杀死的女性(Schmelzer 2019)为人工智能在部署环境中的行为可靠性提出了质疑。另外,1896年出现第一个被人类司机杀死的人。谁犯了错?它被确定是司机。当一个自主系统犯错时,是汽车还是司机(Gurney 2013)有错?有许多工厂对汽车中的故障机制进行召回,如刹车。这与人工智能软件系统有什么不同吗?许多汽车开发商的目标是,与其他制造商相比,他们使用自主权能使汽车多么安全(Griffith E 2016)。这是他们广告的关键,以促进消费者的接受和采购。
埃隆-马斯克表示,一个主要的担忧是人工智能系统可能被秘密开发(Etherington 2012),从而限制了监督。例如,微软对OpenAI的文本生成软件拥有独家权利(Hamilton 2020)。这违背了埃隆-马斯克作为OpenAI创始人之一的最初策略,其目标是开发开源技术。在过去十年及以后,汽车公司的主要动机是收益。在20个月的时间里,一家生产无人驾驶汽车技术的公司涉及18起事故(Wiggers 2020)。这家公司拒绝支持一个专注于自动驾驶汽车 "安全第一 "指导原则(Wiggers 2019)。相反,该公司公开表示,他们支持法律和法规。从法律的角度来看,现有的法律是否适用是相当不确定的(Moses LB 2007)。正因为如此,汽车制造商可能没有适当的激励来开发安全系统(Cooter 2000)。即使这家公司的公众反对主动关注安全,即使在20个月内发生了18起事故,他们仍然能够筹集到超过30亿美元的资金。一些法律思想支持有限的监管,但要注意激励商业制造商只开发有益/有用的人工智能(McGinnis JO 2010)。无论好坏,关于经济学、法律和哲学的讨论(Russell 2015)正试图形成什么是有益/有用的答案。如何内在地激励(Baum 2017)开发者创造有益的人工智能?挑战在于,人们基于需求来证明行动的合理性(Kunda 1990)。商业制造商必须支持他们的底线,而国防部则有一套不同的目标体系。
1.2 美国防部独特的人工智能挑战——这是秘密!
与商业需求相比,美国防部在什么是有益的方面有一套不同的标准。然而,我们可以从工业界学到很多东西。当然,国防部无法承担有关自主系统的国际事件,特别是在20个月内发生的一系列事件。重大的挑战是,国防部必须在一个隐蔽和隔离的环境中开发解决方案,甚至与其他机密项目隔离。即使是基于开放源码的监督也是有限的。这就是系统安全组织在国防部如此重要的原因,必须有标准、测量、政策和程序来支持他们的工作。无论是在商业界还是在国防部,人工智能的功能都被认为是不可预测的、无法解释的和目标不确定的(Yampolskiy,2020)。当我们谈论海军武器系统的AI安全问题时,这通常不包括可能影响功能性能的对抗性攻击。鉴于这种观点,使用DeepFakes等技术的AI对抗性网络攻击,将一个图像/视频放入另一个图像/视频中进行误判(Chauhan 2018),并没有包括在这项研究中,但可以考虑在未来进行调查。不可预测、无法解释和目标不确定仍然是人工智能部署技术的一个重要问题,即使开发人员有动力并尽了最大努力(Deci 1971, Krantz 2008)。即使是最好的,也还是在20个月内造成了18起事件。
国防部和商业制造商都面临的一个主要挑战是争分夺秒的开发方式(Armstrong 2016)。从核军备竞赛中是否可以学到一些东西?明显的教训是,我们需要在发展的早期阶段进行监督(Borrie 2014)。人工智能可能会产生同样的戏剧性效果,就像核军备竞赛一样。考虑一下将军用无人机和武器置于人工智能系统的完全控制之下的问题(Bohannon 2015)。考虑墨菲定律,"任何可能出错的事情都会出错"。当涉及到我们期望计算机做什么和它们实际会做什么时,特别是当开发变得更加复杂时,不想要的事件就更有可能发生(Joy 2000)。请注意,十多年前启动的涉及机器人 "决定 "和行动的大部分研究都是由军方资助的(Lin 2011)。
国防部必须问的是,"我们能否在安全关键功能中部署人工智能,即由人工智能驱动的武器自主行动?" 回答这个问题的挑战在于确定人工智能系统是否可以被 "修复",变得更加可靠,以支持安全需求,就像汽车的刹车。
对于商业和政府的人工智能发展,安全标准的需求正变得越来越突出(Ozlati 2017)。联邦政府已经采取了行动。国家标准与技术研究所(NIST)专注于创建标准,为人工智能发展提供监督。在他们52页的报告(NIST 2019)中,九个重点领域之一是衡量标准。本文考虑纳入NIST人工智能发展标准中,关于衡量训练数据的数量/大小和质量/构成。
1.3 海军武器系统安全
为了克服这些独特的挑战,确保海军武器装备有足够的安全和保障,海军军械安全和安保活动(NOSSA)成立。NOSSA是这项研究的资助组织,它认识到人工智能系统的安全可能需要一套特殊的政策、指导方针和衡量标准。他们关注的是,ML/AI算法不能使用传统的危险分析方法(MIL-STD 882E)进行分析,联邦航空管理局的严格准则(DO-178C)也不充分。NOSSA希望调查军事系统中人工智能发展的特殊分析要求(联合SSSEH v1.0)。NOSSA还想调查是否需要任何新的方法来对人工智能部署的武器系统进行充分的危险分析(JS-SSA-IF Rev. A)。
这项研究的动机是基于以下六个关键原因,即海军需要对部署在武器系统中的机器学习算法建立可衡量的可信度:
1.我们不能也不应该期望作战人员接受并使用人工智能作为一种社会规范(Lapinski 2005),即使是在有最好的可解释的人工智能技术的情况下,也不能首先让我们的采购团体对机器学习算法在现实作战环境中的部署建立可衡量的可信度。
2.如果对训练数据质量不信任,包括训练过程中可能产生的任何负面副作用(Everitt 2018),采办界就无法确定和认证ML算法的部署操作限制。
3.国防部采购团体在遵循商业系统安全准则时受到限制,因为商业世界在确保AI功能行为方面没有相同的严格要求。商业制造商受利润驱动,可能会受到客观推理(Lewandowsky 2015)的影响,与强调安全问题的动机冲突可能导致销售量降低。
4.海军记录项目的AI升级,最初是按照传统软件开发的能力成熟度模型(Shneiderman 2020)开发的,目前不包括ML/AI开发差异。采购社区需要支持和监督来填补这一空白。
5.当务之急是,"Speed to the fleet "的人工智能系统的部署必须克服其动机限制,并考虑人工智能的安全影响,使用规划、监督和审查委员会持续监测,包括对灾难的回顾性分析(Shneiderman 2016)。
6.海军武器系统爆炸物安全审查委员会(WSESRB)和其他审批监督机构在没有足够的指导和工具的情况下,其评估是有限的(Porter 2020, Jones 2019)。指导和工具需要成为国防部预算的一个优先事项。
人工智能具有创造技术飞跃的潜力(Eden 2013)。这种潜在的飞跃,特别是在处理武器系统时,需要仔细审查。这种审查的重点是训练数据的组成和规模的特殊性。这项研究将描述监督小组所需的审查,可以用来提高部署人工智能功能的安全性和可信度。