数据科学在金融风控模型中的应用

分享嘉宾:严澄 度小满 风控模型负责人
编辑整理:王鑫彤
出品平台:DataFunTalk
导读:众所周知,信息时代下的数据就是能源,就是生产力。但是面对海量、纷繁的数据,特别是在金融领域,如何充分地利用数据是核心问题。本次分享主要想和大家一起探讨下,在金融风控场景下,如何通过数据对齐模型和业务目标,哪些数据、方法可以应用于风控模型,通过哪些指标可以正确地评估模型效果,以及最终如何用数据科学解释模型结果。今天的介绍会围绕下面四点展开:
科学定义数据
科学应用数据
科学评估数据
科学解释数据
1. 金融风险管理
信贷业务本质是储蓄转化为投资的一种形式。类比于其他的互联网业务,电商平台的推荐系统实现的是客户和商品需求之间的精准匹配,广告平台的投放系统实现的是客户和潜在兴趣之间的精准匹配,互联网信贷业务的风险管理目标就是实现资金供给方和资金需求方的精准风险匹配。在风险匹配的两端,资金供给方期望的风险目标是明确的,所以风险管理的核心是预测资金需求方的风险,从而进行精准匹配。接下来我们讲讲风险定义以及如何科学地预测风险。
2. 科学定义数据

在信贷行业内,对风险最常见的定义是年化风险,即年化不良金额除以年化余额。 这是因为简化收益大多是按照年化定价 - 年化风险 - 年化资金成本来计算的。一整包资产的年化风险受很多因素影响:逾期的用户分布,逾期的金额分布,放款的久期分布。虽然年化风险从业务上来看是个非常直观的指标,但如果要直接预测年化风险则是非常困难的。从更易实现的角度来看,预测逾期的用户分布会更直接而简单。
假设有一个模型可以较好地预测人数逾期率,那么我们怎么与年化风险目标挂钩呢?即模型的目标如何与业务的目标对应。在真实的业务场景中,我们很容易发现,资产的年化风险与人数逾期率(MOB12)的比值是一个在1附近的数值。对于这个数值的解读,即当年化风险除以人数逾期率显著大于1时,意味着整体额度过高,尤其是风险相对低的客户的风险敞口没有控制好;当年化风险与人数逾期率接近时,意味着额度和风险匹配得比较好;而当年化风险除以人数逾期率显著小于1时,意味着整体的额度策略过于保守,虽然从风险角度讲是好事,但从业务视角看其实是制约了整体的余额规模。经过一定量的迭代以后,往往都会使得年化风险和人数逾期率之间的关系趋近于1。这时候如果人数逾期率预测得足够准确,那么意味着年化风险预测就会很容易。
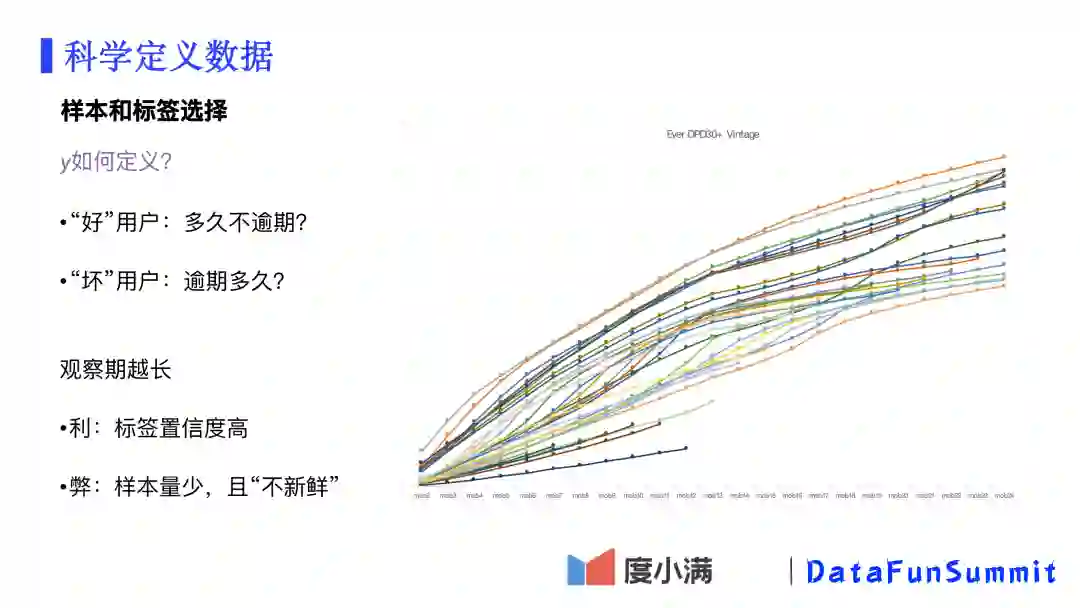
在前面的定义中提到了“逾期”的概念,那么如何定义逾期,以及如何定义用户的“好”“坏”呢?
逾期本身是一个随时间变化的状态量, 比如在约定还款的15天内都没有还款,而在第16天成功还款,那么在前15天是逾期的,而第16天之后则不是逾期状态。显然,逾期的时间越长越坏,最终逾期的概率越高。如何选择一个合适的时间尺度去定义一个用户是逾期的“坏”用户?在实际操作中,我们往往通过观察逾期N天后到最终逾期180天以上的概率。比如说当这个概率已经大于90%时,我们就可以认为这个N已经是一个很好的时间刻度了。在实际业务中,我们一般取N=30。
同样的,对于“好”的定义,一样有一个时间问题。显然,观察越长时间没有逾期发生,用户“好”的概率越高。然而对于用户的观察时间越长,会导致可用于学习的样本量越少(尤其是新发展的业务本身数据就很少),并且样本都是过去很久以前的数据(这在内外环境快速变化的情况下影响更大)。
那么如何设定一个合适的观察时间窗呢?通过右侧的vintage曲线图,我们可以看到,随着时间的推移,不断有新的用户发生逾期,但新逾期发生的增速在缓慢地下降(斜率在变小)。理想情况下,我们希望找到斜率为0的那个时间点作为观察窗口;而在实际操作中,我们往往根据业务的发展阶段和vintage曲线的斜率变化来决策观察窗口。在我们的实际业务中,一般取MOB=12作为中长期的风险表现观察窗口。
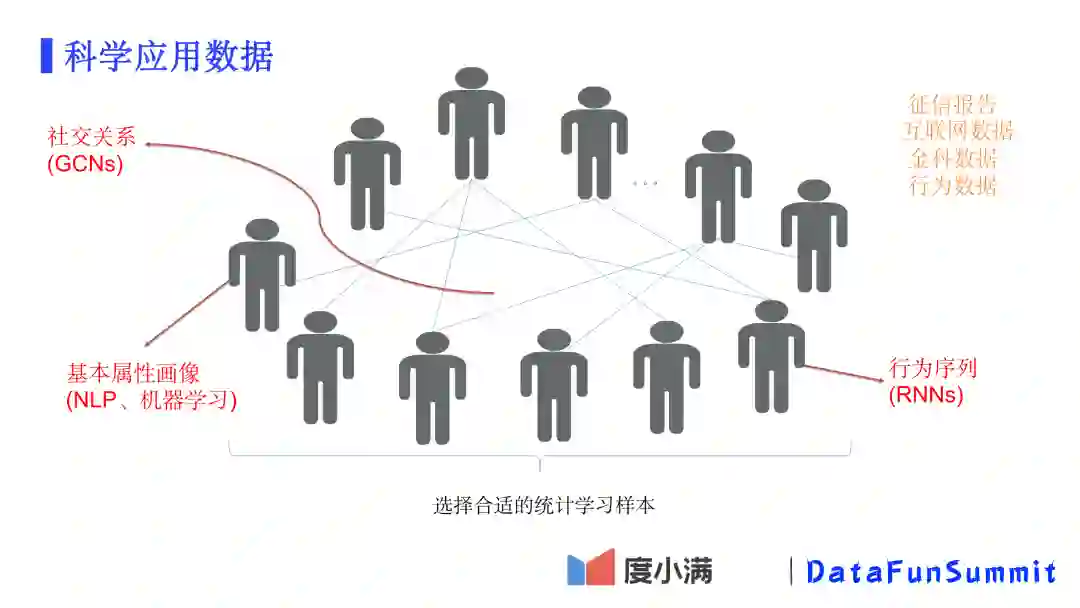
当有了样本和模型的目标以后,接下来看哪些特征数据可以应用于风控模型。从整个金融视角来看,可用数据类型有以下几类:
征信报告:用户历史信用记录
互联网数据:用户在互联网上的各种数据
第三方金融科技公司的合规数据
用户在自身产品下的行为数据
从三个视角来描述用户:
基本属性画像:描述用户的基本属性画像,如年龄、性别、婚姻、职业、文化水平、兴趣爱好、人生阶段、常驻地等(通过各种机器学习、NLP等算法预测);
行为序列:用户在一段时间内的行为,总是有很强的相关性。尤其在信贷场景下,行为序列很好地反映了用户的需求(通过各种RNNs做序列建模);
社交关系:物以类聚,人以群分。比如通过用户周围人的收入及消费能力,例如同小区的人或者同事,可以一定程度从侧面反映用户的资产能力(通过各种GNNs做关联网络的建模)。
以下是一些简单的模型、特征设计示例,由于我们今天主要讨论数据科学,就不详细展开了。
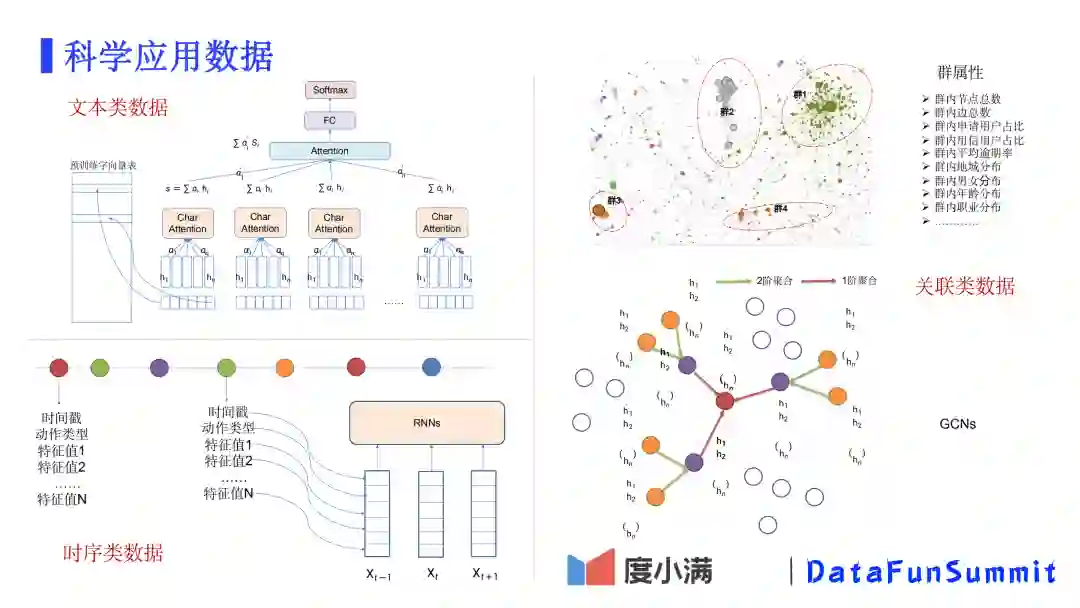
文本类数据:利用Attention网络提取大量文本的核心数据;
时序类数据:利用大量借还款行为做RNNs模型预测用户未来风险;
关联类数据:1)分群算法:群属性作为特征;2)基于深度图卷积网络,充分利用相邻节点的信息。
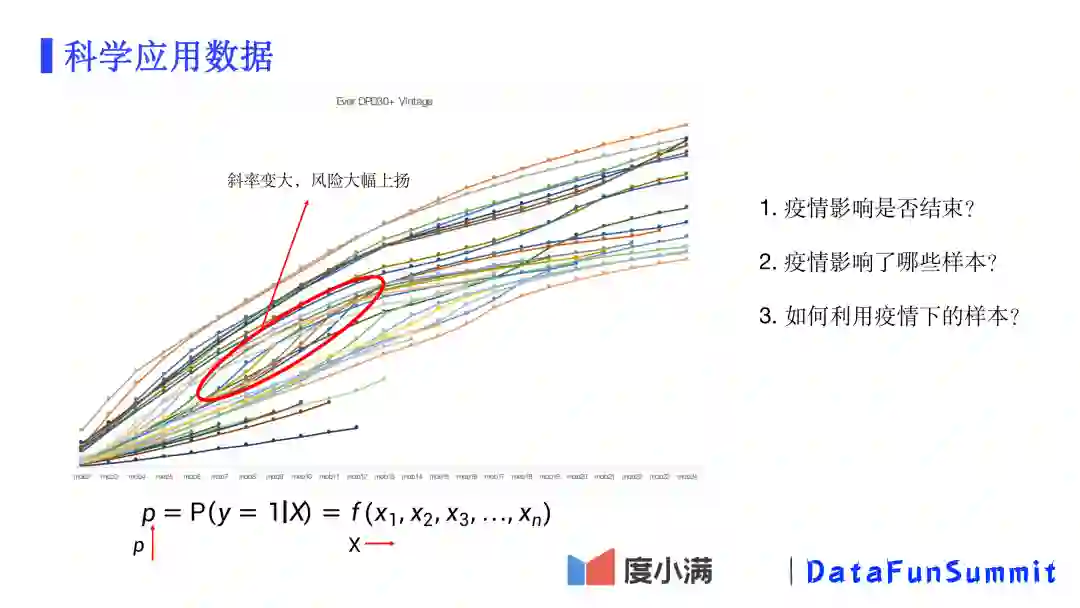
回顾之前关于选择观察期窗口的vintage图表。如上图红框中所示,可以看到很多月份的曲线斜率突然大幅上扬。按时间去对应的话,就会发现这段时间正是2020年初新冠疫情爆发的时间。疫情的爆发导致逾期率大幅上涨,而对疫情的影响我们没有任何历史经验,也就是说历史学习到的特征X(用户属性)与目标Y(逾期率)之间的关系已经不适用在疫情场景下了。于是针对当下,我们需要考虑三个问题:
疫情影响是否结束?这涉及到我们该选择什么样的X—Y关系用于建模和预测。
疫情影响了哪些样本?疫情显然是特殊场景,不应该和正常环境下的数据混合在一起。
如何利用疫情下的样本?
疫情持续反复,但影响在不断减弱,我们主要探讨下面两个问题。
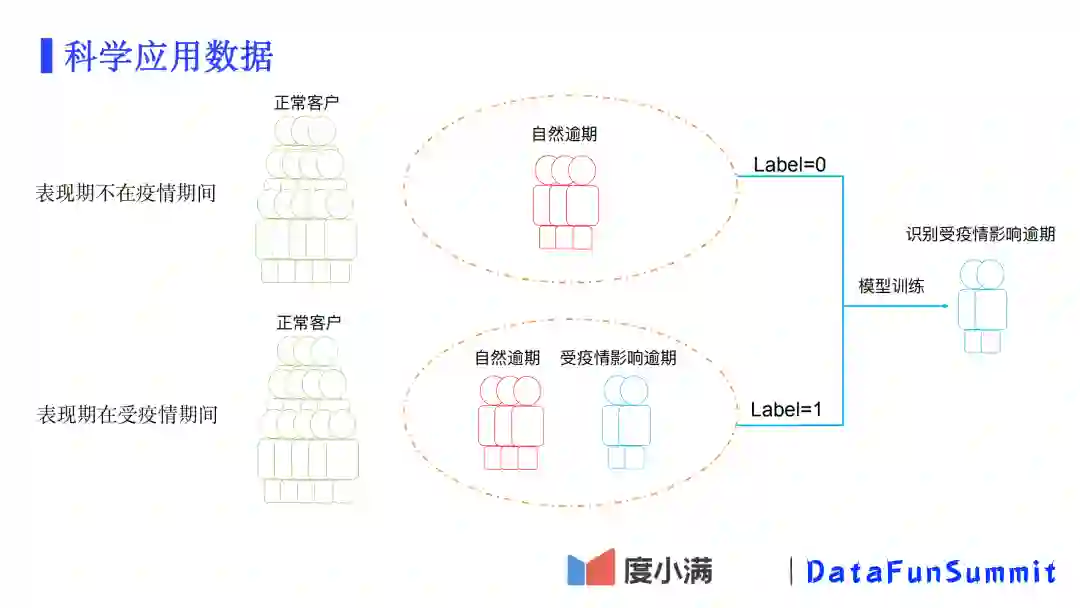
找出受疫情影响的用户,可以把客户分成以下两种:
表现期不在疫情期间:包括正常用户和自然逾期的用户;即这些用户是不受疫情影响的。
表现期在受疫情影响期间:包括正常用户和逾期用户,而逾期用户里必然有自然逾期和受疫情影响而逾期的用户。
我们将表现期不在疫情期间逾期的用户标识为0,将表现期在受疫情期间的逾期用户标识为1,基于二分类模型进行训练。经过模型训练以后,那些预测高概率为1的用户就是那些受疫情影响而逾期的用户,而那些预测高概率为0的用户就是不管有没有疫情都大概率会逾期的客户。这样,我们设定一个阈值,就可以将大部分受疫情影响而逾期的用户找出来。
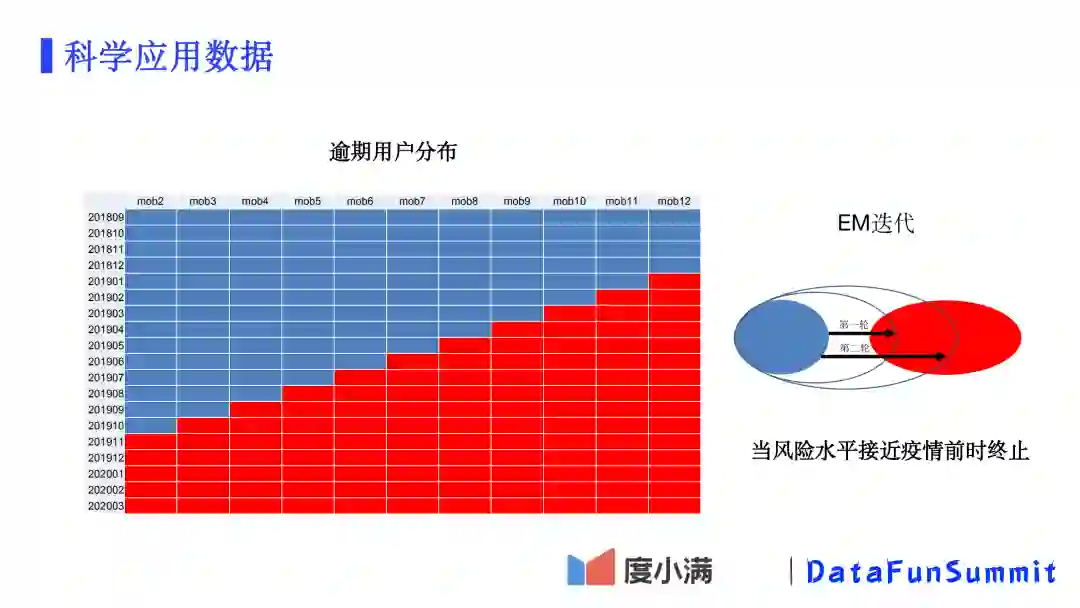
另一种方法是通过EM迭代进行识别。如上图所示,我们按照授信月的各个MOB是否在疫情发生时期来对逾期客户标记颜色。蓝色:自然逾期;红色:在疫情期间内逾期。
通过每一轮的EM迭代,我们可以将红色分布里面近似于蓝色分布的部分逐渐找出来并加入到蓝色区块内。当整体的风险水平接近疫情前时停止,那么依然留在红色区域内的逾期用户就是受疫情影响而逾期的用户了。
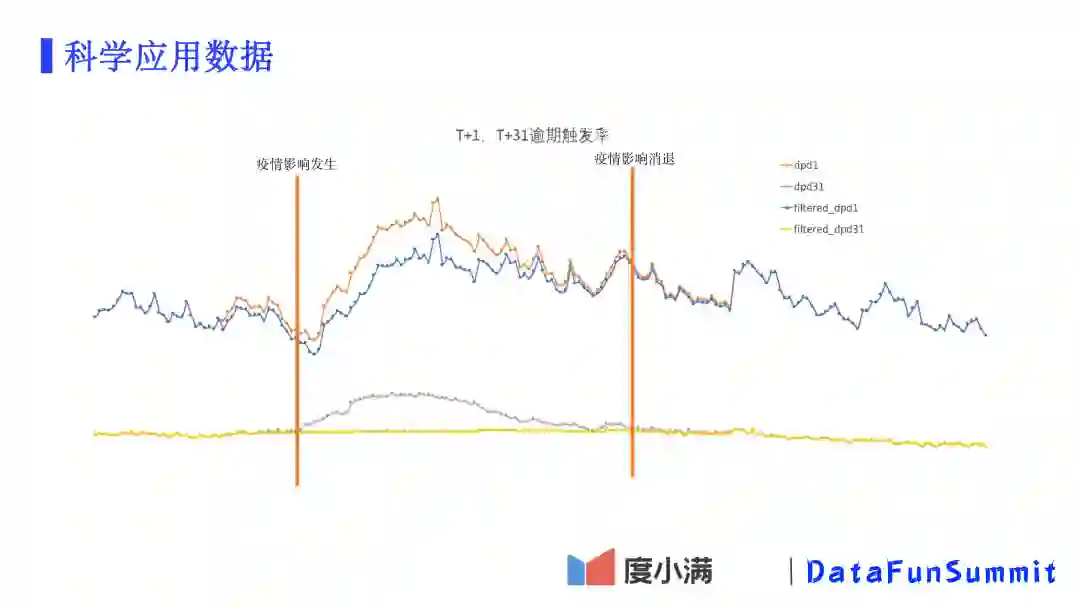
通过以上两种方法过滤后,我们再观察下随时间的逾期率变化。从上图可以看到,原先逾期30天以上的曲线在疫情发生期间是大幅上扬的,但过滤后整个线就比较平了。
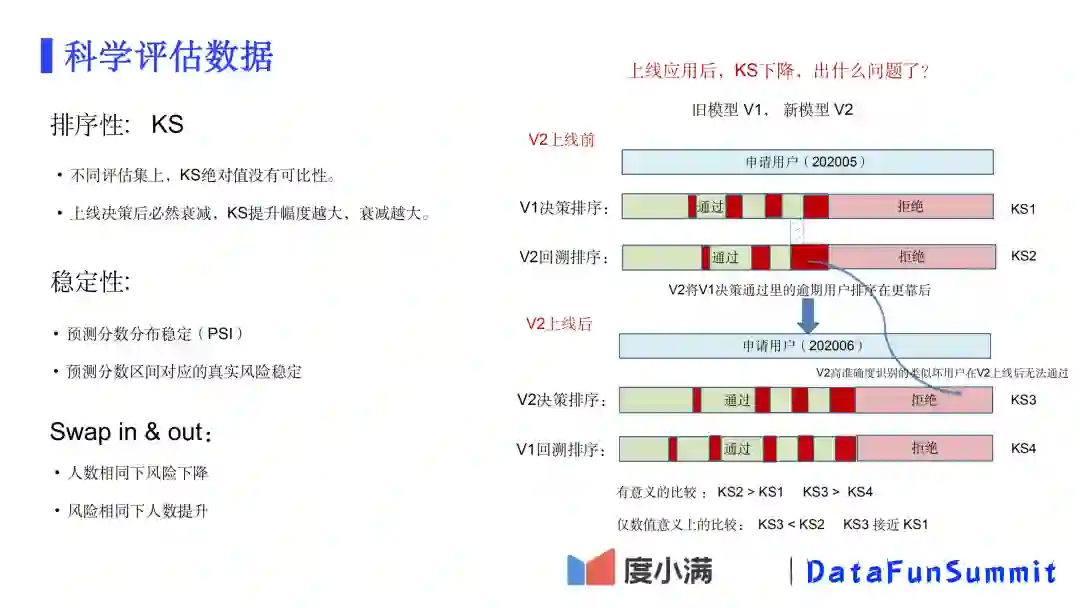
接下来讲一下如何科学准确地评估模型的效果。
风险模型最核心的指标就是排序指标KS。KS值可以很好地度量一个集合内好坏用户的排序分布。一个常见的情形是,离线评测模型的KS值很高,但是等到上线应用后,模型的KS很快就大幅“衰减”了,而且很多时候都是离线提升的越多,线上衰减越大。那么是模型出问题了吗?这里其实有个观察的误区,所谓的“衰减”是指在不同时期的不同用户集合上的KS值比较,而实际上不同集合间的KS绝对值是没有比较意义的。
举一个简单的例子,某一场考试预测排名,试想对全校去年成绩前50的学生进行排序预测容易还是对任意一个班的学生预测排序容易,显然对后者的预测必然会更准确一些。上图中右边部分描述模型上线后KS“衰减”的原因。新模型V2的排序能力高于V1,它可以将V1授信通过的用户中更多的坏用户排到靠后。当V2上线后,V2高准确度识别的类似坏用户无法通过了(也就是只剩下全校排名靠前的学生了),因此对V2决策通过的用户算KS自然就下降了。上图中,只有KS2与KS1、KS3与KS4是有比较意义的。
模型稳定性是另一个关键因素。分布稳定性最基础的指标是PSI,只有预测分数分布是稳定的,这样才有信心可以基于历史数据去预测未来的风险;性能稳定性则是指,要保证预测分数区间对应的真实风险是相对稳定的,比如600-650分之间对应的逾期风险是1%,那么我们希望在所有月份上真实风险都能稳定在1%的水平附近。
而在策略对模型的实际应用中, 核心则是基于Swap in & out的分析。通过分段交叉的矩阵,考量在人数相同的情况下,新模型的整体逾期率是否显著低于旧模型;而在相同逾期率的水平下,新模型的通过率提升多少,可以提升整体规模多少。
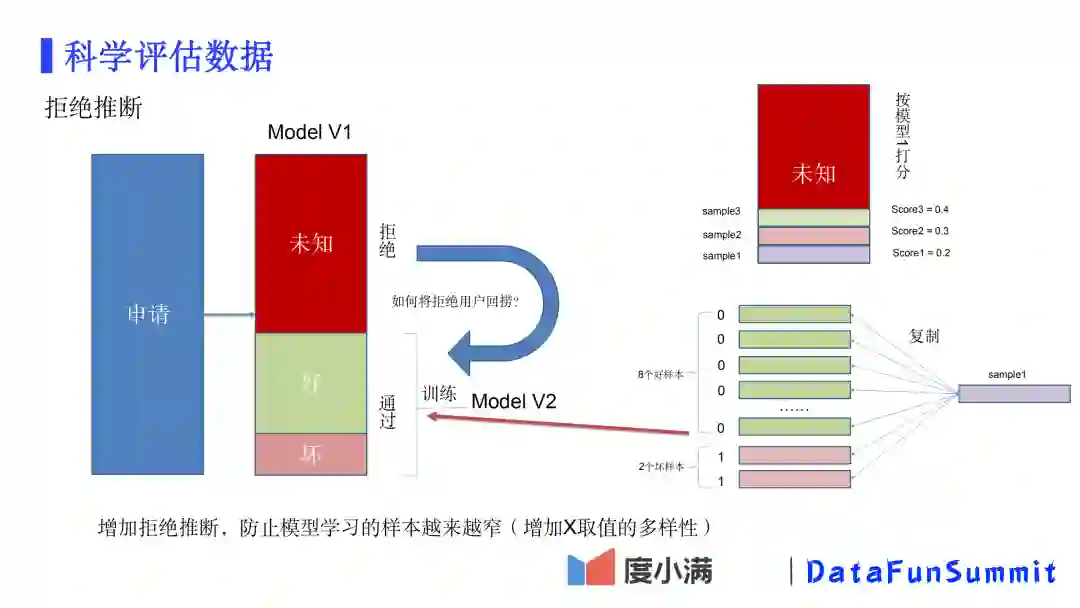
那些被拒绝掉的用户,是没有风险表现的,只有那些最终通过且发生信贷行为的用户才有风险表现。试想,用于学习的样本都是历代模型认为较好的客户,随着模型不断迭代,模型学习的样本向好用户收敛,样本的特征空间就越来越窄了。常见的一种方式是引入拒绝推断,给拒绝的用户赋予label,让其参与到模型训练里。上图介绍了一种做拒绝推断的方法。
给拒绝的用户按照模型1给出的打分,比如某个用户模型1的分数是0.2(逾期率20%),那么将这个用户的样本复制10份,其中8份样本的label设成0,2份设置成1。这样10份样本特征一样,但整体label为1的比例就是20%。当然也可以不复制样本,很多模型都支持设置样本权重。通过这种方式增加了X取值的多样性,可以一定程度提升模型的适用性。
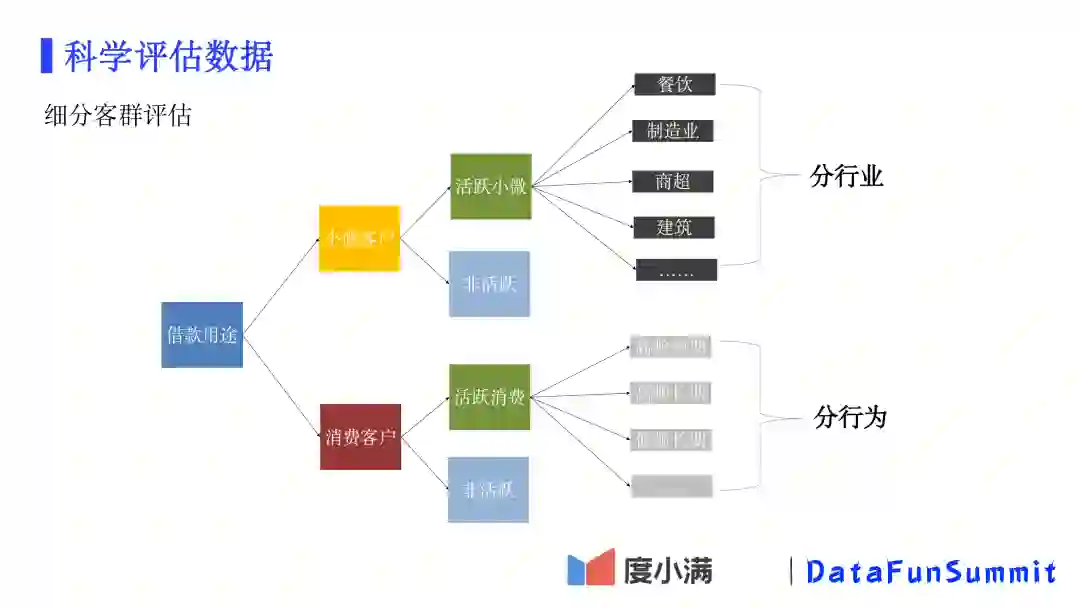
客户分群的方法有很多,上图展示了一种划分方法:最顶层先考虑实际的借款用途,区分为小微和消费;然后基于客户的活跃程度进一步划分成活跃和非活跃;最后再根据如行业或者行为上的差异进一步细分客群。细分客群的核心思想是,不同客群之间存在明显的差异性,一种是特征上的差异,一种是风险表现上的差异。这种情况下,细分客群建模,可以让每个模型充分学习自身样本的信息,而不是从全局上平均化地去拟合。但是,如果寻找不到显著的差异,特别是样本总量还不是很充足的时候,分客群不是一个好的选择。
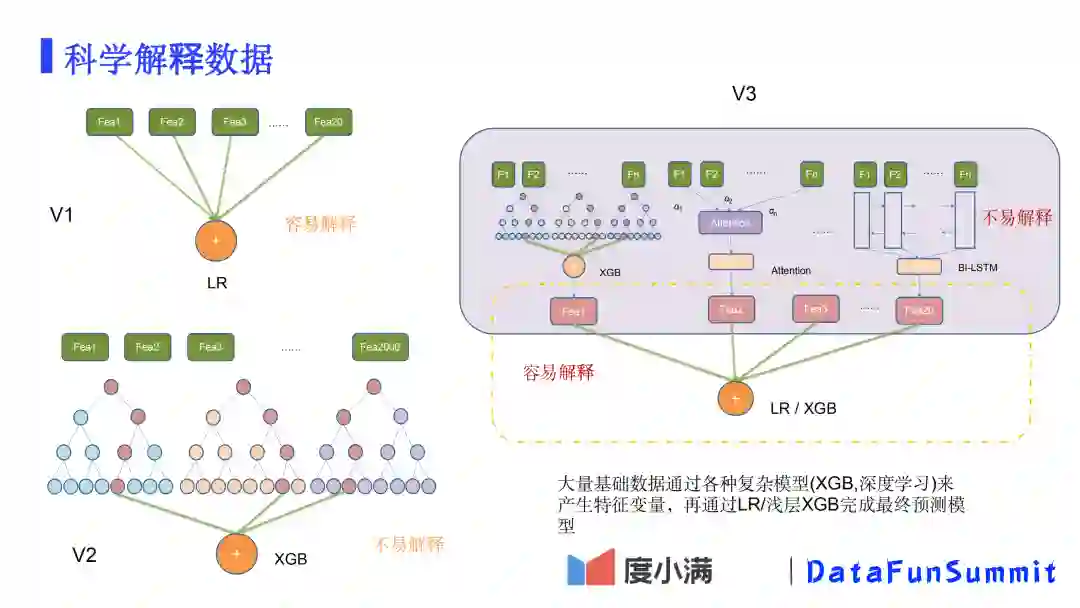
最后讲一下如何解释模型结果。
V1:逻辑回归模型:优点——可解释强。缺点——特征数量少,模型简单,对特征的质量要求非常高,预测的能力相对较弱。
V2:决策树模型:优点——避免大量特征工程,模型效果较好。缺点——特征多,且特征之间是非线性关系,难以解释。
V3: 两层模型:把成千上万的变量基于数据源,通过各种机器学习、深度学习的算法构建子模型,然后把这些子分作为上层LR或浅层XGB模型的输入,完成最终的模型。优点是在顶层模型上解释性很好,子分与结果具有一定线性关系,可以快速定位子分的问题,非常便于排查问题。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“数据科学” 就可以获取《数据科学专知最新资料合集》专知下载链接







